Fix the Target, Precompute Once: A Backend-Free Word-Ladder Solver With a BFS Distance Field
Every word ladder ends at the same word. One offline BFS precomputes a distance field, making par and shortest-path queries O(1) lookups, no backend.
Join the DZone community and get the full member experience.
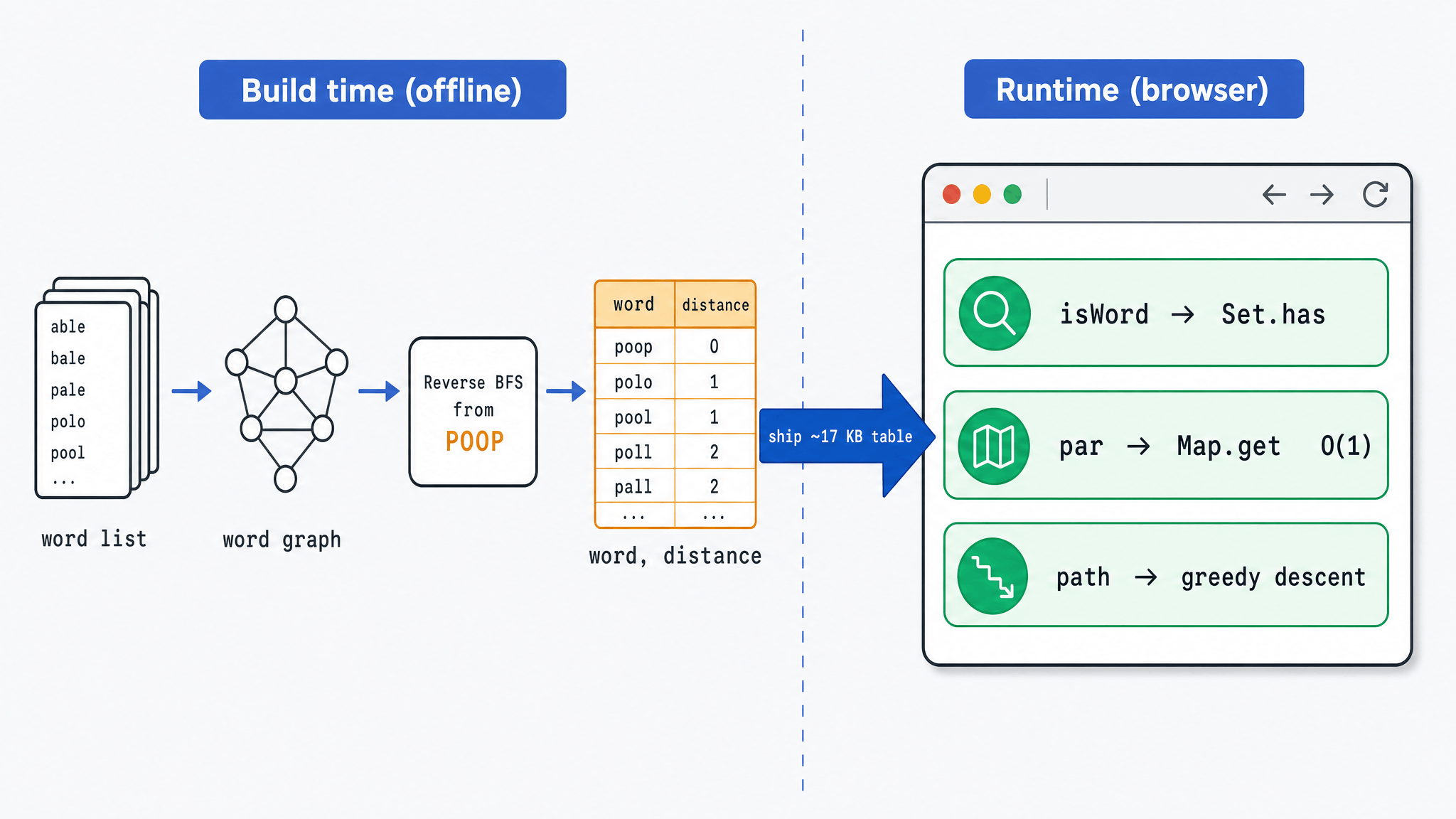
Join For FreeWhen you build an interactive puzzle, the latency budget is unforgiving. Every keystroke needs an answer that feels instant. A daily word-ladder game has to do three of those instant jobs at once: confirm that the word a player typed is legal, tell them the best possible score for the day, and, on request, reveal the shortest solution. I ran into all three while building Poople, a daily game where you change a 4-letter word into POOP one letter at a time, and the fix turned out to be a tidy lesson in trading repeated computation for one-time precomputation.
The obvious approach is to run a graph search whenever you need an answer. That works, and it is also the wrong default here. This article walks through why, then shows how fixing the destination word lets you replace every future search with a single offline pass plus an O(1) lookup. The whole solver then runs in the browser, with no backend and no per-request search.
The Problem in Graph Terms
A word ladder connects two words by changing one letter at a time while keeping a valid word at each step. The idea is old. Lewis Carroll published it as Doublets in 1877. Model it as a graph, and it becomes a textbook shortest-path problem:
- Each valid 4-letter word is a node.
- Two nodes share an edge when their words differ by exactly one letter.
- The shortest path between two words is the fewest steps to ladder between them.
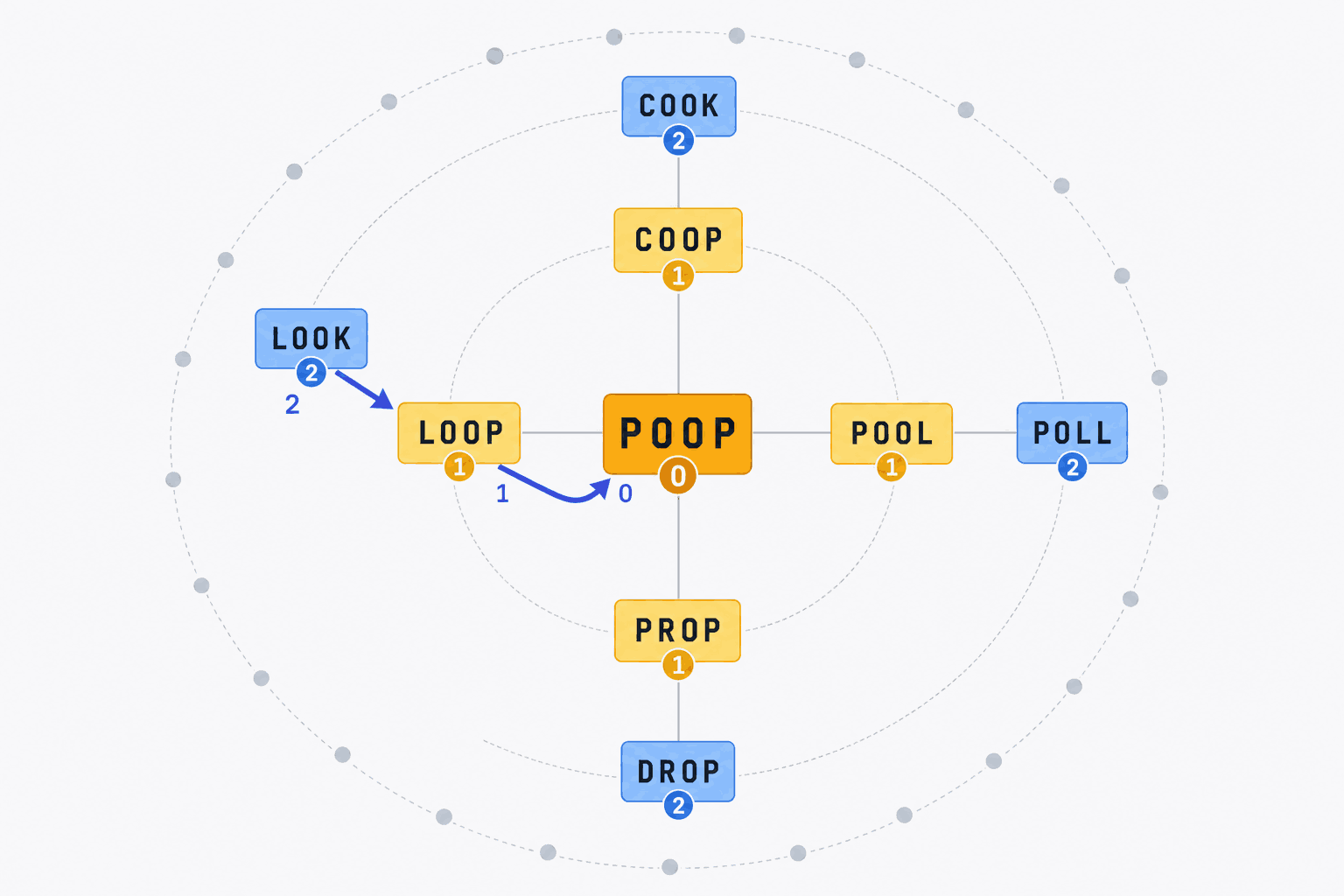
In Poople, the destination is always the same word, POOP, and that fixed target is the hinge the whole design turns on. The shortest distance from a word to POOP is what the game calls par, the best achievable score for that day's starting word. In an unweighted graph like this one, breadth-first search gives those shortest distances directly.
The graph is small. The shipped dictionary holds about 2,300 valid 4-letter words, and the hardest starting words sit around eleven steps from POOP. Small, but not so small that you want to search for it again on every interaction.
Modeling the Edges Without Storing Them
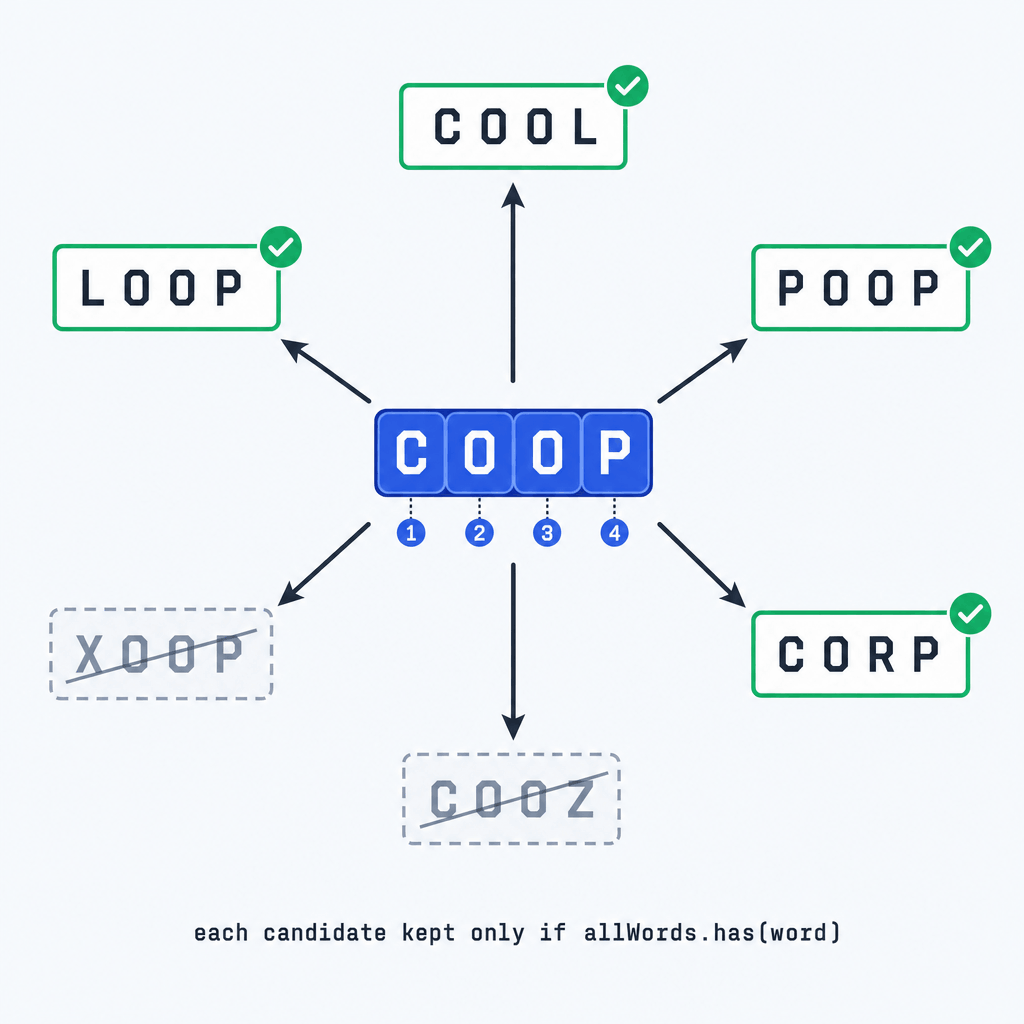
You do not need an adjacency list. Because an edge is just a one-letter difference, you can generate a node's neighbors on demand by trying every single-letter change and keeping the ones that land on a real word. Membership is a Set lookup.
const ALPHABET = "abcdefghijklmnopqrstuvwxyz";
/** Every dictionary word exactly one letter away from `word`. */
function neighbors(word: string, dictionary: Set<string>): string[] {
const out: string[] = [];
for (let i = 0; i < word.length; i++) {
for (const c of ALPHABET) {
if (c === word[i]) continue;
const candidate = word.slice(0, i) + c + word.slice(i + 1);
if (dictionary.has(candidate)) out.push(candidate);
}
}
return out;
}For a 4-letter word, this checks 4 positions times 25 other letters, so 100 candidate strings, each an O(1) Set lookup. The graph stays implicit, which keeps the shipped data to a flat word list rather than a serialized edge structure.
The Naive Approach, and Why It Does Not Fit
With neighbors in hand, the textbook move is a per-query breadth-first search that returns the path.
function shortestPath(start: string, end: string, dict: Set<string>): string[] | null {
if (!dict.has(start)) return null;
const queue: string[][] = [[start]];
const visited = new Set<string>([start]);
while (queue.length) {
const path = queue.shift()!;
const node = path[path.length - 1];
if (node === end) return path;
for (const next of neighbors(node, dict)) {
if (!visited.has(next)) {
visited.add(next);
queue.push([...path, next]);
}
}
}
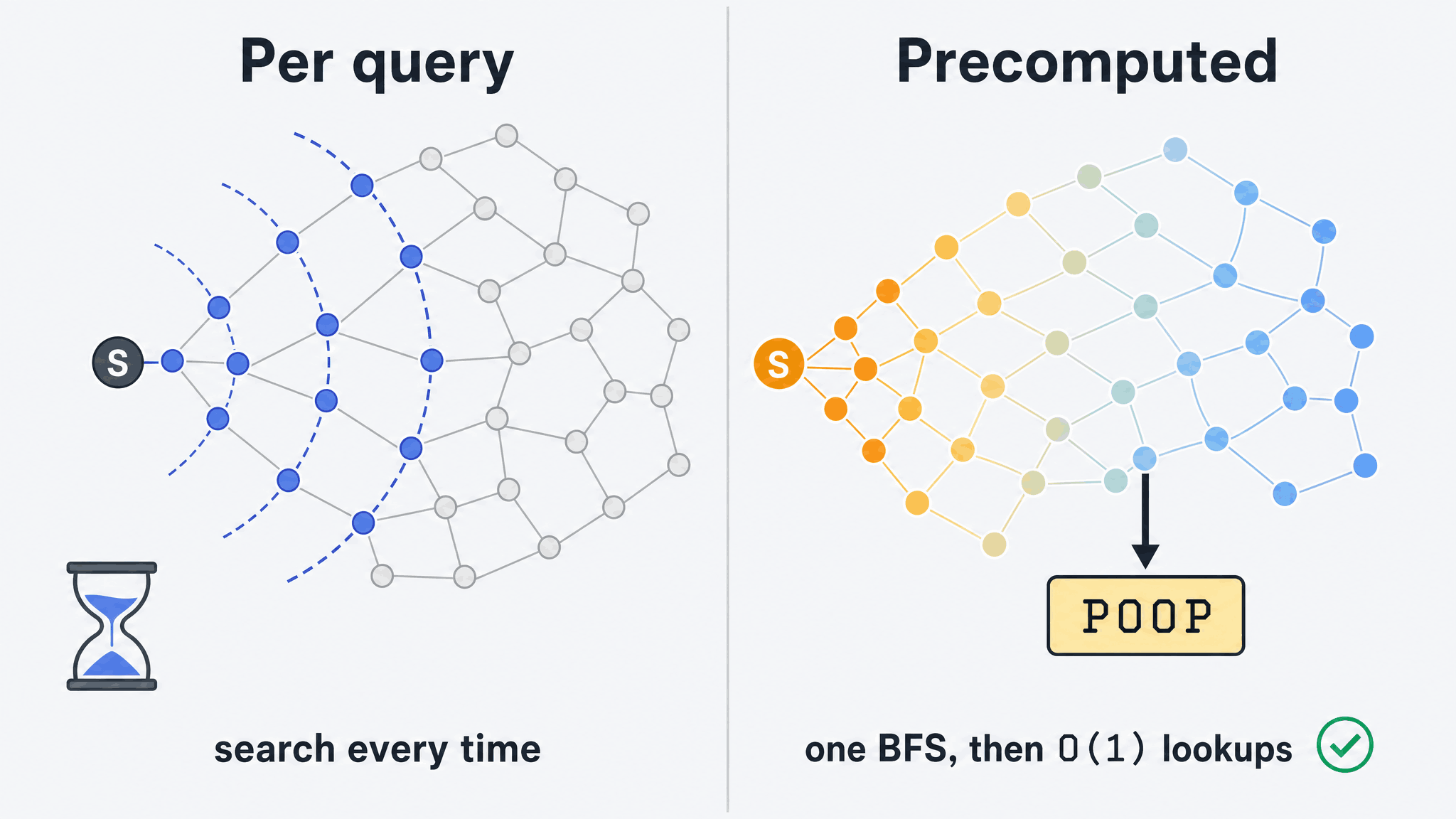
return null;This is correct and easy to read. It also has two properties I did not want in a game loop. It stores a full path for every entry in the queue, so memory grows with the frontier. More importantly, it repeats the entire search for every word a player explores. On a game whose target never changes, that is the same work over and over.
The Inversion: One Search From the Target
Here is the key observation. Every query ends at the same node, POOP. So search backward from POOP exactly once. One breadth-first pass sources at the target labels every reachable word with its distance to POOP. That labeling is a distance field, the same idea as a flow field in grid pathfinding, and it answers every future query in advance.
The build step runs offline, in a script during the build, never in the player's browser.
/** Run once at build time. Distance from every reachable word to the target. */
function buildDistanceField(words: Set<string>, target = "poop"): Map<string, number> {
const dist = new Map<string, number>([[target, 0]]);
let frontier = [target];
while (frontier.length) {
const next: string[] = [];
for (const word of frontier) {
const d = dist.get(word)! + 1;
for (const neighbor of neighbors(word, words)) {
if (!dist.has(neighbor)) {
dist.set(neighbor, d);
next.push(neighbor);
}
}
}
frontier = next;
}
return dist;Because the graph is undirected, distance from POOP to a word equals distance from that word to POOP, so one source covers the entire dictionary. The output serializes to one word,distance line per word, which is the data the game ships.
// build-distances.ts
const field = buildDistanceField(allWords);
const lines = [...field].map(([word, d]) => `${word},${d}`).join("\n");
writeFileSync("word-dist.ts", "export const WORD_DIST_RAW = `\n" + lines + "\n`;");For about 2,300 words, the full pass finishes in a few milliseconds on a laptop, and the resulting table is roughly 17 KB of raw text. That table is the only artifact the runtime needs.
Runtime: Lookups Instead of Searches
At load, the shipped table parses once into two structures: a Map from word to distance, and a Set of valid words. After that, the three jobs from the introduction are all constant-time or close to it.
const distEntries: Array<[string, number]> = WORD_DIST_RAW
.trim()
.split("\n")
.map((line) => {
const [word, dist] = line.split(",");
return [word.trim().toLowerCase(), parseInt(dist, 10)];
});
/** word -> shortest distance to POOP. This is "par". */
export const wordDist: Map<string, number> = new Map(distEntries);
/** Every legal move, derived from the same table. */
export const allWords: Set<string> = new Set(distEntries.map(([w]) => w));
export function getDist(word: string): number {
return wordDist.get(word.toLowerCase()) ?? -1; // -1 means unknown word
}
export function isWord(word: string): boolean {
return allWords.has(word.toLowerCase());
}Validating a move is isWord, an O(1) Set lookup. Reading par is getDist, an O(1) Map lookup. The third job, showing a full shortest solution, is where the distance field pays off a second time. You do not need another search. From the start word, repeatedly step to any neighbor whose distance is one less than the current distance, until you reach POOP.
function solveShortestPath(start: string, target = "poop"): string[] {
let current = start.toLowerCase();
const path = [current];
let dist = getDist(current);
if (dist < 0) return path; // unknown word, no route
while (current !== target && dist > 0) {
const step = neighbors(current, allWords).find((n) => getDist(n) === dist - 1);
if (!step) break;
path.push(step);
current = step;
dist -= 1;
}
return path;
}This greedy descent is always correct on a distance field, and that is worth stating precisely. Every node at distance d greater than zero has at least one neighbor at distance d - 1, because that is exactly how BFS assigned the labels. So a step down always exists, and the walk reaches zero in d steps. There is no queue and no visited set. The work is proportional to par, which caps near eleven, so a solution is effectively free to produce.

A Daily Puzzle With No Database
There is one more piece. The game is the same for everyone in the world on a given day, and it still has no backend. The puzzle is a pure function of the clock. Take whole days since a fixed epoch and use that integer both as the puzzle number and as the index into a list of starting words.
const DAY_MS = 86_400_000;
const EPOCH_UTC = Date.UTC(2025, 7, 14, 8, 0, 0, 0); // 2025-08-14 08:00 UTC
function daysSinceEpoch(nowMs = Date.now()): number {
if (nowMs <= EPOCH_UTC) return 0;
return Math.floor((nowMs - EPOCH_UTC) / DAY_MS);
}
function getStartWord(startWords: string[], dayIndex = daysSinceEpoch()): string {
const len = startWords.length;
return startWords[((dayIndex % len) + len) % len];No database read, no per-user state, no synchronization. Two players who open the page at the same moment compute the same puzzle independently. The 08:00 UTC rollover is just the time component baked into the epoch. Because the result depends only on the date, the page is fully cacheable at the edge, which is what lets the whole game sit behind a CDN.
Tradeoffs and Lessons
Precompute when the target is fixed. The entire win comes from one constraint: every query ends at the same node. That lets a single backward search amortize across all future queries. If the target varied per day, you would rebuild the field per day, which is still cheap here but changes the calculus.
A distance field beats path-in-queue BFS for repeated queries. The naive solver allocates a growing array per queued path and re-explores every time. The field uses one shared Map, and reconstruction is a greedy walk with O(par) memory.
Keep the shipped data flat and parse it once. A word,distance table is trivial to generate, diff in version control, and parse into a Map and a Set at module load. There is no custom binary format to maintain.
Mind the graph-construction cost if you scale up. Generating neighbors with per-position membership tests is O(N x L x 26) across the dictionary. At four letters and a 26-letter alphabet, that is nothing. For longer words or larger alphabets, the classic optimization is to bucket words by wildcard patterns such as *OOP, P*OP, PO*P, and POO*, so words sharing a bucket are neighbors. That builds adjacency in O(N x L) and is worth the switch only when the simple version starts to hurt.
Guard the edges. Unknown words return a sentinel distance of -1 rather than throwing, and the descent has a natural termination because the distance strictly decreases. A small step cap is a cheap safety net against any future data inconsistency.
Many shortest paths can exist. Several routes can tie for par. The greedy descent returns one valid par path, which is all the game needs to show, and scoring by step count treats every par route as equal.
Where This Pattern Applies
The technique generalizes to any setting where many shortest-path queries share a fixed endpoint over a static graph:
- Routing toward a single sink, such as a depot or an exit.
- Autocomplete ranking by edit distance to a fixed term.
- Game hint systems and grid flow fields, where a unit always heads toward one goal.
- Any repeated shortest-path query to a constant target where the graph rarely changes.
The limits follow from the assumptions. The field assumes a fixed target and a static graph. Change the target or the word set, and you rebuild the field, which is a build-time cost rather than a request-time one. For variable targets, a bidirectional search or a small set of precomputed fields, one per target, keeps most of the benefit.
The lesson that stuck with me is simple. When a search always ends in the same place, stop searching forward from the start. Search backward from the end once, write down the answer for every node, and let the runtime read instead of compute. You can see the result running live at Poople, where every par score and every shortest solution is a lookup into a table that was built before you ever opened the page.
Opinions expressed by DZone contributors are their own.
Comments