In the world of data analytics, the concept of orchestrating data is a relatively emerging concept that is still in its infancy. As a result, different organizations consider different approaches, tools, and processes to orchestrate data that suits their use case. Though the underlying approaches and tools may differ, the fundamentals of data orchestration remain consistent.
What Is Data Orchestration?
Data orchestration refers to a combination of tools and processes that allow you to automate, streamline, and simplify data management for enhanced analytics and reporting. This can be done by combining different applications into one single workflow or by connecting them together in order to create an automated pipeline for processing large amounts of information.
Modern data orchestration encompasses a framework of different data pipelines and workflows that help data-driven applications ingest and process data more efficiently. As one of its fundamental benefits, data orchestration breaks down data silos by connecting multiple storage systems and reconciling varied data formats into a unified, consistent format. The resultant output is considered more sensible and can be used further for advanced analytics and business insights. By eliminating the need to repeat the same query on different databases, orchestration also reduces the risk of data duplication.
Orchestrated vs. Unorchestrated Data
The term "orchestration" is used differently for data. In some cases, orchestration is referred to as a set of rules for data management so that data can be easily accessed and analyzed. Others consider orchestration as a process where data is transformed from one format into another. In reality, modern data orchestration combines both.
Applications and users produce data in a wide variety of formats. This data is typically semi-structured, unstructured, or both. In legacy applications, software teams relied on the manual combination, verification, and storage to make data useful. Such data workflows also relied on traditional utilities such as cron jobs and other scheduling tools to manage the transfer of data between multiple locations.
Figure 1: Traditional data workflow
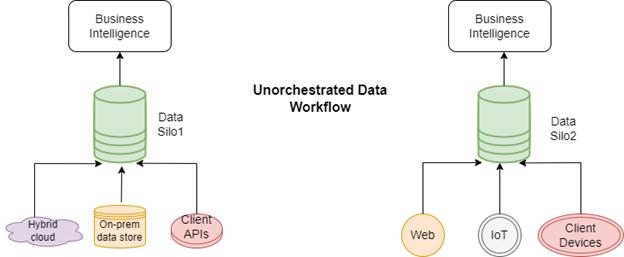
Unorchestrated data presents multiple challenges in the modern tech landscape that involve efficient models such as DevOps and DataOps teams. These include:
- Time-consuming evaluations of dependencies between different workflows
- Manual audit log evaluation that also hampers performance assessment
- Fatal errors that require manual cleanup, which is costly and time consuming
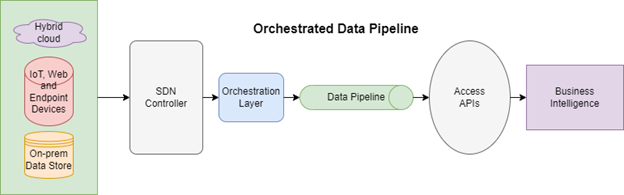
In contrast to the traditional approach, data orchestration emphasizes the automation of data management workflows through virtualization, automation, and real-time analytics. Orchestrated data is unified and allows for standard, programmatic access by all types of clients. Besides this, orchestrated data is always local to compute, is accessible on demand, and scales elastically.
Figure 2: A typical orchestrated data workflow
Abstraction Across Stages of a Data Pipeline
While the implementation of a data orchestration platform varies by the use case and organization, the process typically follows a similar workflow. A typical data pipeline commonly undergoes the stages shown in Figure 3:
Figure 3: Stages of a typical data pipeline
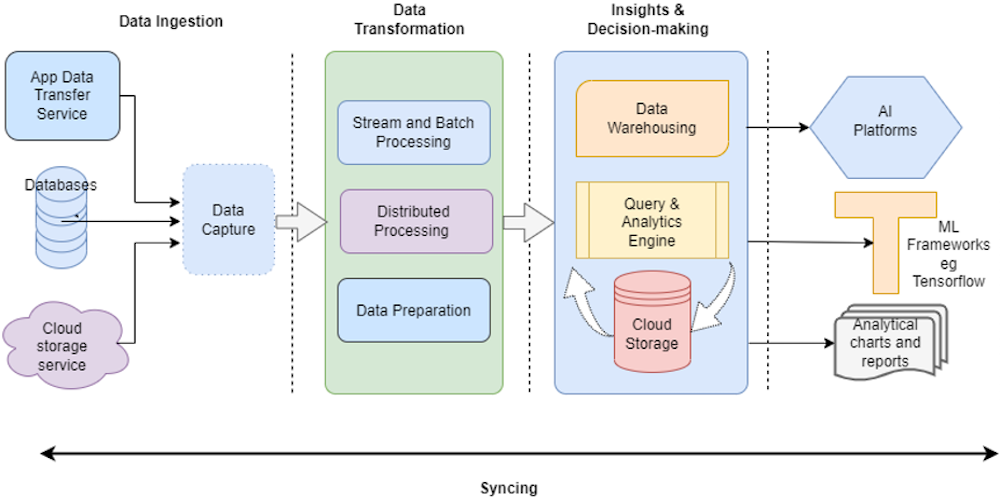
Data Ingestion
This stage involves the collection of data from a wide variety of sources and the organization of both existing and incoming data before it is ready for the next stages of the pipeline. Ingestion involves (both structured and semi-structured) data being collected from the standalone legacy source systems, flat files, or cloud-based data stores such as data lakes and data warehouses. To prepare the sourced data for the pipeline, the ingestion phase typically follows processes such as:
- Enriching incoming information with existing data
- Applying labels and annotations
- Performing integrity and validity checks
Data Transformation
While data produced by the ingestion stage is structured and organized, it is usually presented in native formats. Also known as the cleansing stage, the transformation stage encompasses various tools and processes that reconcile data into a standard format for further processing and analysis by internal systems. By the end of the transformation phase, the data pipeline achieves a consistent, recognizable data format that was initially ingested from multiple sources in multiple formats.
Depending upon the type of data, a transformation phase in data orchestration typically involves:
- Multi-language scripting
- Data mapping
- Deduplication
- Processing graph/geospatial data
Insights and Decision Making
The insights and decision-making stage relies on a unified data pool that is collected from multiple sources and is then presented through various business intelligence (BI) or analytical platforms for decision making. Considered one of the most crucial stages of a data pipeline, this stage activates data by deriving key fields and applying business logic for users or services consuming it. The stage involves processes such as:
- Cleaning up replicated datasets
- Use-case-based data processing
- Analytics and reporting to help generate insights
Syncing
Syncing enables congruence between different data sources and pipeline endpoints. The synchronization stage entails the activities involved in updating changing data to data stores to ensure data remains consistent through all stages of a pipeline's lifecycle. Some synchronization techniques include:
- Version control
- File synchronization
- Server mirroring
- Connecting distributed filesystems
Benefits of Data Orchestration
Data orchestration helps organizations reduce data silos by connecting multiple storage systems without requiring extensive storage locations or massive migrations. While use cases vary for different organizations, here are some of the most commonly known benefits of data orchestration.
Technical Benefits
Some technical benefits of implementing data orchestration include achieving consistent service-level agreements (SLAs), eliminating I/O bottlenecks, quickly adapting to framework and storage systems of your choice, and improving data governance.
Data orchestration helps to enforce the tracking of scattered data across disparate systems. By helping organize incoming performance data in real time through an efficient data validation framework, orchestration ensures that data complies with set standards. This makes it easy to set, monitor, and achieve defined SLAs, irrespective of the number of different instances. Additionally, by leveraging end-to-end automation tools, orchestration can take action on performance and usage metrics that don't comply with preset standards.
Orchestration defragments and virtualizes data so that it is always local to the compute element. By allowing data to be accessed through a single namespace regardless of its physical location, orchestration significantly improves memory access speed for data workloads running on multiple platforms, thereby reducing read/write bottlenecks associated with traditional shared access. Orchestration also eliminates the bottlenecks arising from the manual organization of incoming data, allowing for faster reads and writes.
Data orchestration allows data pipelines to scale independently from storage or compute. Organizations can leverage this flexibility to build hybrid data pipelines that utilize any combination of tools to process data. Additionally, by allowing data teams to build applications that ingest data from disparate sources using APIs, organizations can quickly build up platform-agnostic, data-driven frameworks without changing an existing tech stack.
By connecting multiple data systems and organizing data in a single pipeline, orchestration enforces common data governance principles across a distributed team structure. Orchestration also leverages specific tools to block or quarantine sources of corrupt data until they have been dealt with.
Business Benefits
One of the primary benefits of data orchestration is to enrich data for deeper analysis and business insights. Business benefits of orchestration include elastic cloud computing power to solve problems quicker and self-service data infrastructure across business units.
Modern data orchestration platforms bring the elastic benefits of cloud computing, such as flexible storage, enhanced scalability, and high availability into data pipelines for real-time insights and analytics. Cloud data orchestrators combine distributed data pipelines into a single workflow that ingests and analyzes data in real time. This powers faster decision making on a continuous stream of changing data to make meaningful insights. Organizations can also reduce spend on infrastructure since they only pay for actual resource consumption.
Cloud computing platforms enable data engineers to implement pipelines that connect multiple, cross-functional departments. The teams can use SaaS solutions that enable them to access different parts of the pipeline on demand, allowing for both independent and seamless collaboration.
Use Cases for Data Orchestration
With modern businesses becoming increasingly data driven, most companies implement data orchestration to execute tasks that extract value from growing data volumes. Below are some common use cases for data orchestration.
Bursting Compute to Public Clouds
Most organizations begin by running their workloads locally. As data orchestration abstracts compute and storage from the data consumed, organizations can burst workload processing to the cloud when demands spike. The platform-agnostic framework also makes it easy to move data between computing environments, enabling teams to rapidly burst processes between the cloud and local infrastructure. By granting firms access to more compute resources when necessary, orchestrators provide the flexibility to deal with the scaling demands of dynamic, data-driven applications.
Hybrid Cloud Storage With On-Prem Compute
An orchestrator forms the proxy that allows data and applications to interoperate among instances, services, and infrastructure. While doing so, data orchestration platforms ensure that entities can access organizational data seamlessly, regardless of its location. This enables organizations to provision infrastructure for hybrid deployments with multiple storage options and locally hosted compute resources. As a result, organizations can allocate multiple cloud resources for short-term projects, thereby benefiting from affordable pricing options other than purchasing extra storage equipment.
Splitting a Data Pipeline Across Data Centers
Organizations typically deal with continuous streams of data that become larger and more complex over time. Data orchestration automates the management of such data streams by implementing a single pipeline across various data sources while bringing data closer to compute. Such frameworks eliminate the effort required to manage data infrastructure, enabling the consolidation of multiple data centers, sources, and joins into a single pipeline. This makes it easy to both distribute and process data across multiple data centers while keeping it available on demand.
High-Performance Analytics and AI on Cloud Storage
Cloud-based data orchestration platforms serve as the infrastructure foundation for enterprise AI and high-performance analytics. Such platforms also provide cloud-based storage and compute, offering resources to train AI and analytics models to extract meaningful insights from big data. On account of its platform-agnostic capabilities, data orchestration allows organizations to leverage the benefits of on-prem, private, or public cloud infrastructure in a single data pipeline to help process varied data types for complex AI-based insights and decision making.
