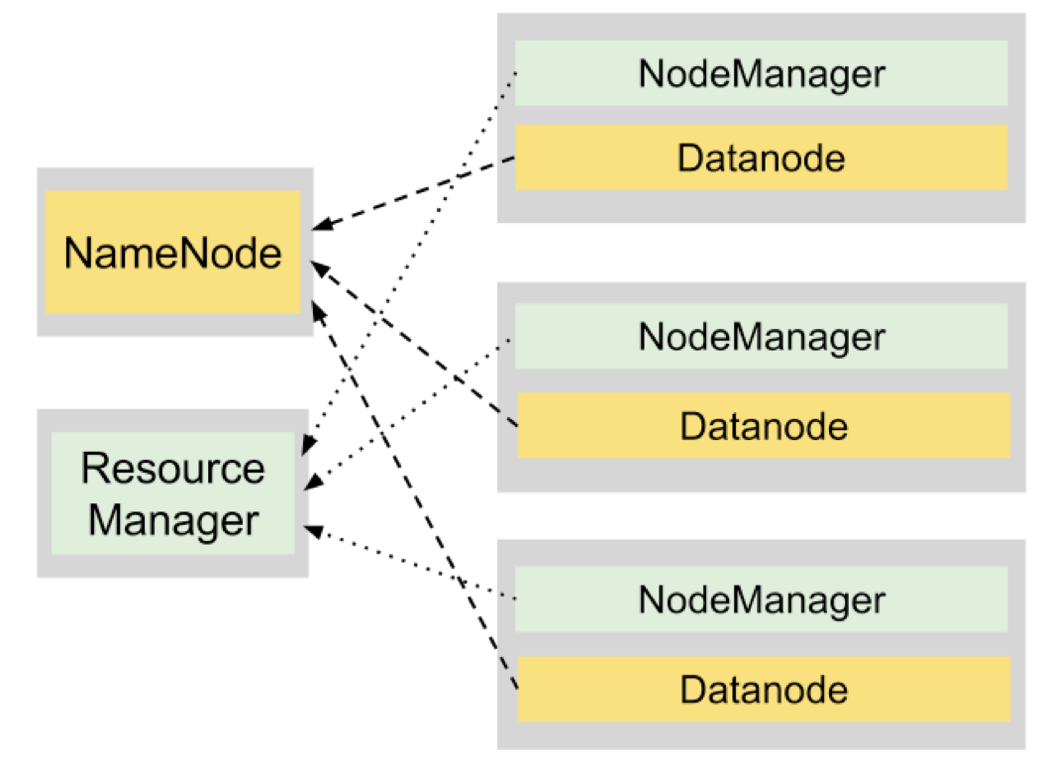
There are a number of frameworks that make the process of implementing distributed applications on Hadoop easy. In this section, we focus on the most popular ones: Hive and Spark.
Hive
Hive enables working with data on HDFS using the familiar SQL dialect.
When using Hive, our datasets in HDFS are represented as tables that have rows and columns. Therefore, Hive is easy to learn and appealing to use for those who already know SQL and have experience working with relational databases.
Hive is not an independent execution engine. Each Hive query is translated into code in either MapReduce, Tez, or Spark (work in progress) that is subsequently executed on a Hadoop cluster.
Hive Example
Let’s process a dataset about songs listened to by users at a given time. The input data consists of a tab-separated file called songs.tsv:
"Creep" Radiohead piotr 2017-07-20
"Desert Rose" Sting adam 2017-07-14
"Desert Rose" Sting piotr 2017-06-10
"Karma Police" Radiohead adam 2017-07-23
"Everybody" Madonna piotr 2017-07-01
"Stupid Car" Radiohead adam 2017-07-18
"All This Time" Sting adam 2017-07-13
We use Hive to find the two most popular artists in July, 2017.
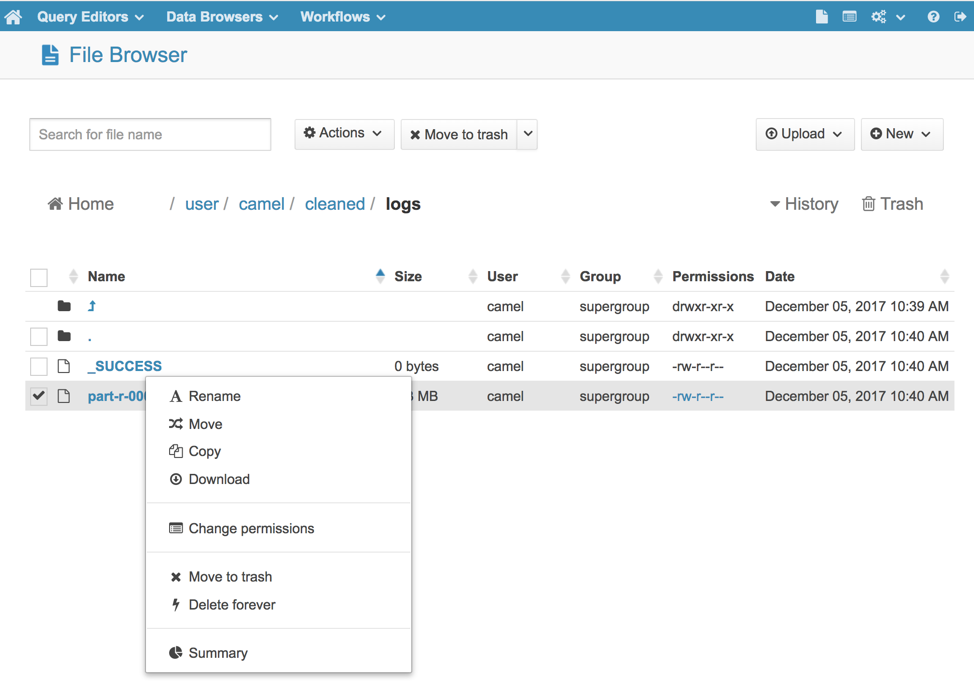
Upload the songs.txt file on HDFS. You can do it with the help of the “File Browser” in HUE or type the following commands using the command line tool:
# hdfs dfs -mkdir /user/training/songs
# hdfs dfs -put songs.txt /user/training/songs
Enter Hive using the Beeline client. You have to provide an address to HiveServer2, which is a process that enables remote clients (such as Beeline) to execute Hive queries and retrieve results.
# beeline
beeline> !connect jdbc:hive2://localhost:10000 training passwd
Create a table in Hive that points to our data on HDFS (note that we need to specify the proper delimiter and location of the file so that Hive can represent the raw data as a table):
beeline> CREATE TABLE songs(
title STRING,
artist STRING,
user STRING,
date DATE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY 't\'
LOCATION '/user/training/songs';
Hot Tip: After you start a session with Beeline, all the tables that you create go under the “default” database. You can change it either by providing a specific database name as a prefix to the, table name or by typing the “use <database_name>;” command.
Check if the table was created successfully: beeline\> SHOW tables;
Run a query that finds the two most popular artists in July, 2017:
SELECT artist, COUNT(\*) AS total
FROM songs
WHERE year(date) = 2017 AND month(date) = 7
GROUP BY artist
ORDER BY total DESC
LIMIT 2;
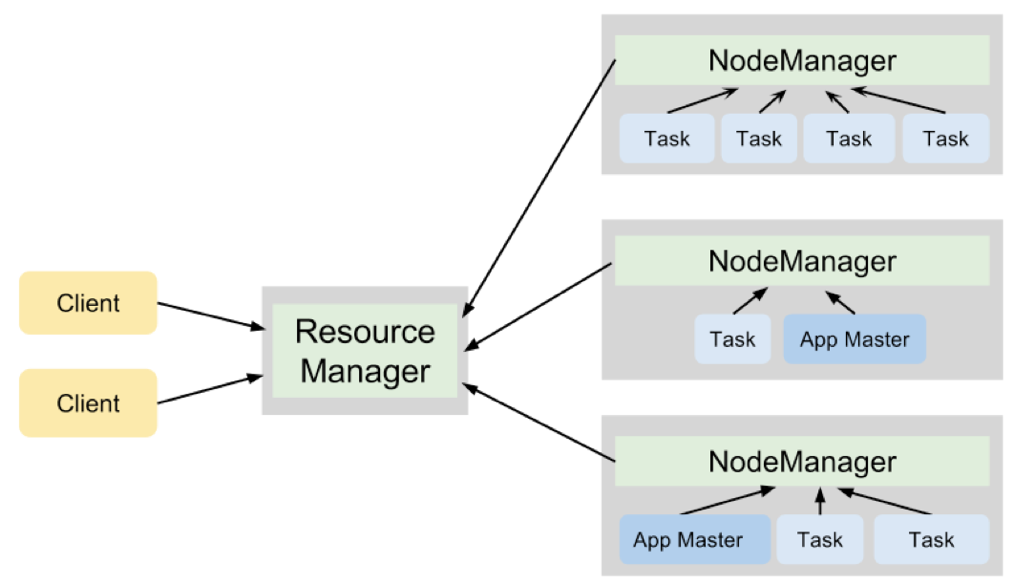
You can monitor the execution of your query with the ResourceManager WebUI. Depending on your configuration, you will see either MapReduce jobs or a Spark application running on the cluster.
Note: You can also write and execute Hive queries from HUE. There is a Query Editor dedicated for Hive with handy features like syntax auto-completion and coloring, the option to save queries, and basic visualization of the results in the form of line, bar, or pie charts.
Spark
Apache Spark is a general purpose distributed computing framework. It is well integrated with the Hadoop ecosystem and Spark applications can be easily run on YARN.
Compared to the MapReduce - the traditional Hadoop computing paradigm - Spark offers excellent performance, ease of use, and versatility when it comes to different data processing needs.
Spark's speed comes mainly from its ability to store data in RAM between subsequent execution steps and optimizations in the execution plan and data serialization.
Let’s jump straight into the code to get a taste of Spark. We can choose from Scala, Java, Python, SQL, or R APIs. Our examples are in Python. To start Spark Python shell (called pyspark), type \# pyspark.
After a while, you’ll see a Spark prompt. It means that a Spark application was started on YARN (you can go to the ResourceManager WebUI for confirmation; look for a running application named “PySparkShell”).
Hot Tip: If you don’t like to work with shell, you should check out web-based notebooks such as Jupyter (https://jupyter.org) or Zeppelin (https://zeppelin.apache.org).
As an example of working with Spark’s Python dataframe API, we implement the same logic as with Hive, e.g. finding the two most popular artists in July, 2017.
First, we have to read in our dataset. Spark can read data directly from Hive tables: # songs = spark.table("songs")
Data with schema in Spark is represented as a so called dataframe. Dataframes are immutable and are created by reading data from different source systems or by applying transformations on other dataframes.
To preview the content of any dataframe, call the show() method:
# songs.show()
+-------------+---------+-----+----------+
| title| artist| user| date|
+-------------+---------+-----+----------+
| Creep|Radiohead|piotr|2017-07-20|
| Desert Rose| Sting| adam|2017-07-14|
| Desert Rose| Sting|piotr|2017-06-10|
| Karma Police|Radiohead| adam|2017-07-23|
| Everybody| Madonna|piotr|2017-07-01|
| Stupid Car|Radiohead| adam|2017-07-18|
|All This Time| Sting| adam|2017-07-13|
+-------------+---------+-----+----------+
To achieve the desired result, we need to use a couple of intuitive functions chained together:
# from pyspark.sql.functions import desc
# songs.filter(\"year(date) = 2017 AND month(date) = 7\")
.groupBy(\"artist\")
.count()
.sort(desc(\"count\"))
.limit(2)
.show()
Spark's dataframe transformations look similar to SQL operators, so they are quite easy to use and understand.
Hot Tip: If you perform multiple transformations on the same dataframe (e.g. when you explore a new dataset)S you can tell spark to cache it in memory by calling the cache() method on the dataframe ( e.g. songs.cache()). Spark will then keep your data in RAM and avoid hitting the disk when you run subsequent queries, giving you an order of magnitude better performance.
Dataframes are just one of the available APIs in Spark. There are also APIs and libraries for near real-time processing (Spark Streaming), machine learning (MLlib), or graph processing (GraphFrames).
Thanks to Spark’s versatility, you can use it to solve a wide variety of your processing needs, staying within the same framework and sharing pieces of code between different contexts (e.g. batch and streaming).
Spark can directly read and write data to and from many different data stores, not only HDFS. You can easily create dataframes from records in a table in MySQL or Oracle, rows from HBase, JSON files on your local disk, index data in ElasticSearch, and many, many others.