While the basic architectural approach of distributed SQL databases is easily recognized and distinct from both NoSQL and traditional relational databases, there are some key differences between them.
Delivery (Cloud/DBaaS, On-Premises, Hybrid)
At this time, every distributed SQL database can be installed in the cloud; however, not all of them offer a fully managed database-as-a-service (DBaaS). Some distributed SQL databases are available in DBaaS formation, as a customer install, and even hybrid installations where the DBaaS can manage local instances and replicate between a private data center and a cloud installation, and vice versa.
Compatibility
Distributed SQL databases strive to be compatible with existing traditional RDBMSs. However, similar to the previous generation of relational databases, there are differences in dialects, data types, and extended functionality like procedural languages. Leading distributed SQL databases have varied approaches to address compatibility.
MariaDB Xpand, for example, maintains compatibility with both MySQL and MariaDB databases. This compatibility includes both wire and SQL dialect, which means you can use most of your existing tools and frameworks that work with MySQL or MariaDB. CockroachDB attempts to be wire compatible with PostgreSQL but reimplements the query engine to distribute processing; this increases compatibility but reduces some opportunity for distributed query processing and tuning.
For complex applications migrating to distributed SQL, an existing traditional RDBMS front end in compatibility mode may make the most sense, particularly if you're using extended features of a traditional database. However, if you're running in production over the long term, migrating to a performance topology is likely a better option than using an existing front end.
Consensus Algorithm
In the early 2010s, NoSQL databases were widely popular for their scalability features. However, they relaxed transactional consistency and removed key database features, including joins. While adoption of NoSQL was swift for applications where scale and concurrency were the most important factors, most mission-critical applications that required transactional integrity remained in client-server databases like Oracle, MySQL, PostgreSQL, and SQL Server.
Ongoing research into consensus algorithms (e.g., Paxos Raft) enabled the creation of better horizontally scaling databases that maintain consistency. There are academic arguments over which is better, but from a user standpoint, they serve the same basic purpose. This research and other developments made some of NoSQL's compromises unnecessary: It's no longer necessary to rely on "eventual consistency" or BASE instead of strong or ACID-level transactions.
Scalability
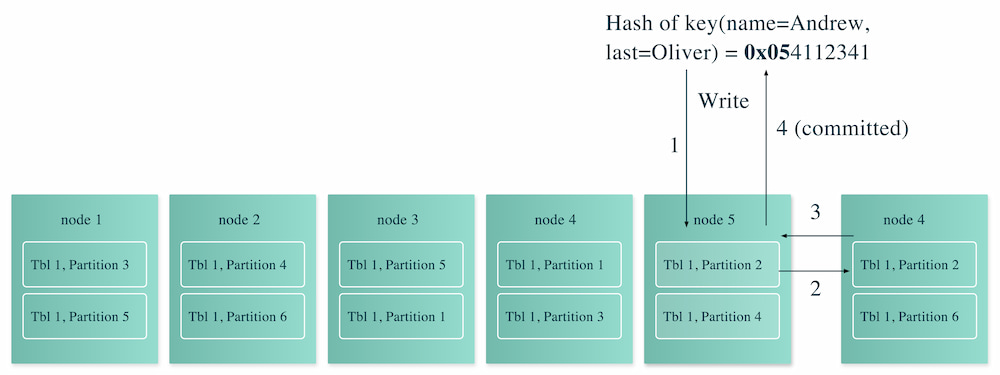
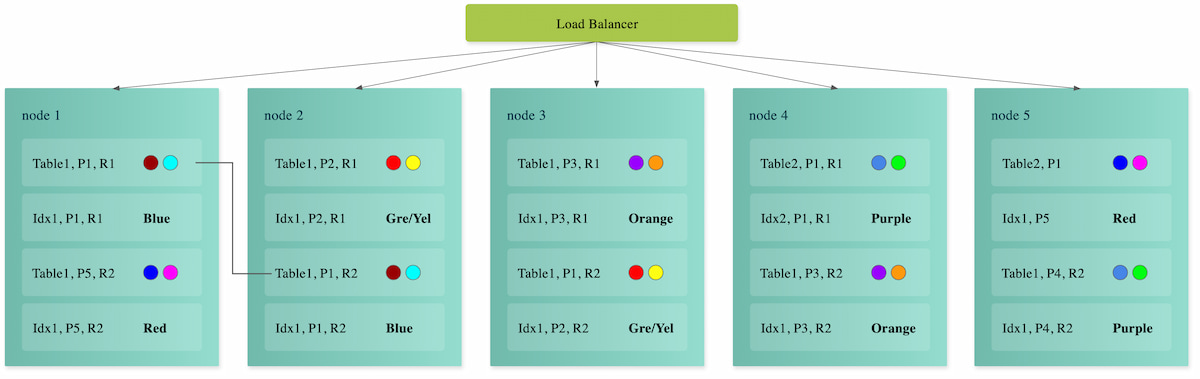
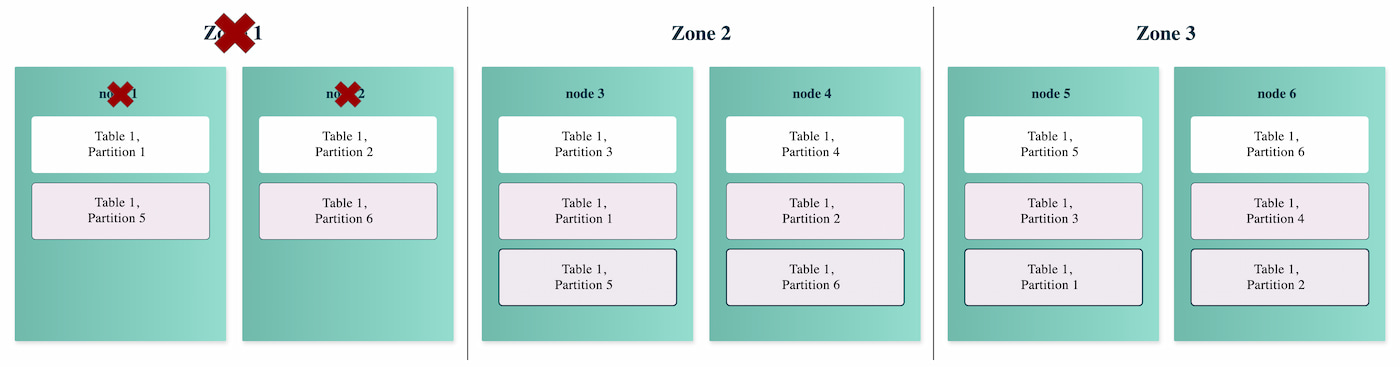
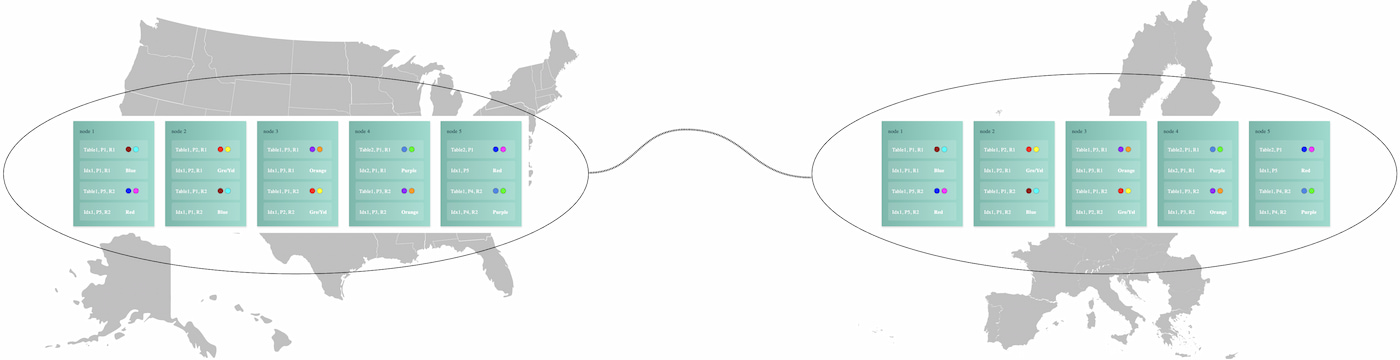
The distributed SQL architecture enables horizontal scalability; however, implementation details have a large impact on production reality. The key to scalability is how data is assigned to nodes and how data is rebalanced over time. Additionally, load balancing plays a central role in both scalability and performance. Some databases rely on the client to "know" which node to address. Others require traditional IP load balancers or use more sophisticated database proxies that understand more about the underlying database.
Fault Recovery
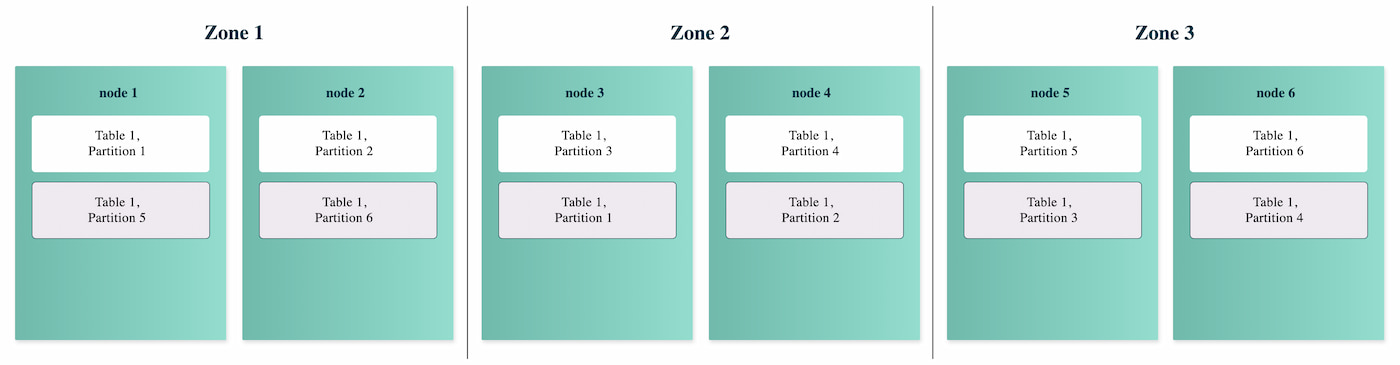
All distributed SQL databases are largely fault-tolerant. However, they differ in what happens during a fault. Does the client have to retry the failed transactions, or can they be recovered and replayed? How long does it take for the database to rebalance data between nodes in the event one is lost?
Kubernetes
The major distributed SQL implementations support Kubernetes, but implementation and performance varies between them based on how IOPS are handled. While some allow bare-metal installations, self-healing and other functionality is limited or lost when running without Kubernetes.
Multimodal
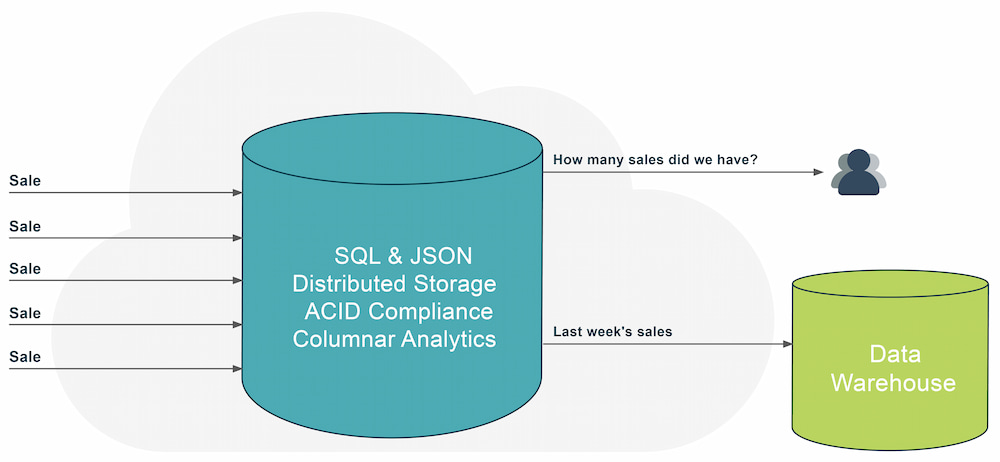
Strictly speaking, multi-modal functionality is not a distributed SQL function but is based on whether ancillary processing or data storage types are provided with the database and how consistency guarantees apply to that functionality. Examples include column storage, analytics, and document storage. If a distributed SQL database provides these additional features, it's possible to combine real-time analytics along with operational capabilities.
Columnar Indexes/Mixed Workload Support
Distributed SQL databases are operational or transactional databases by nature. However, by adding columnar indexes, distributed SQL databases can handle real-time analytical queries. Consider the case of e-commerce: The majority of queries will be light reads and writes, but eventually, someone will want to report on the sales or types of customer engagements — or even offload summaries into a data warehouse. These are long-running analytical queries that may benefit from a columnar index. Most distributed SQL databases do not yet have this capability, but it can be expected to become more commonplace as developers look to consolidate and simplify their data architecture.
Figure 7