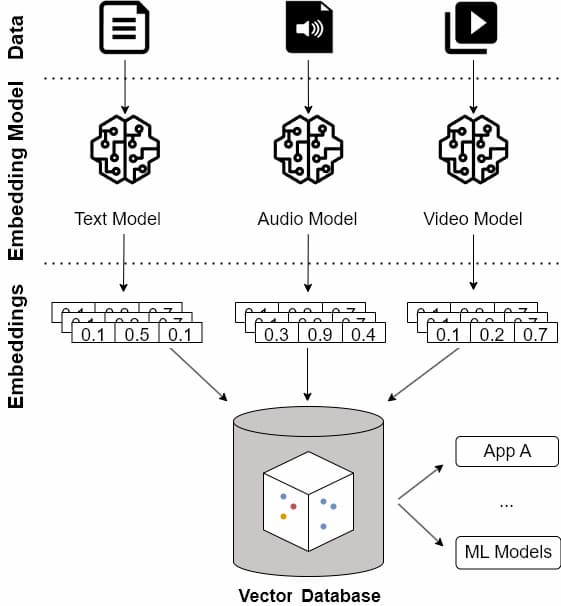
Using vector databases involves understanding their fundamental concepts: embeddings, indexes, and distance and similarity.
Embeddings and Dimensions
As we explained previously, embeddings are numerical representations of objects that capture their semantic meaning and relationships in a high-dimensional space that includes semantic relationships, contextual usage, or features. This numerical representation is composed by an array of numbers in which each element corresponds to a specific dimension.
Figure 4: Embedding representation

The number of dimensions in embeddings are so important because each dimension corresponds to a feature that we capture from the object. It is represented as a numerical and quantitative value, and it also defines the dimensional map where each object will be located.
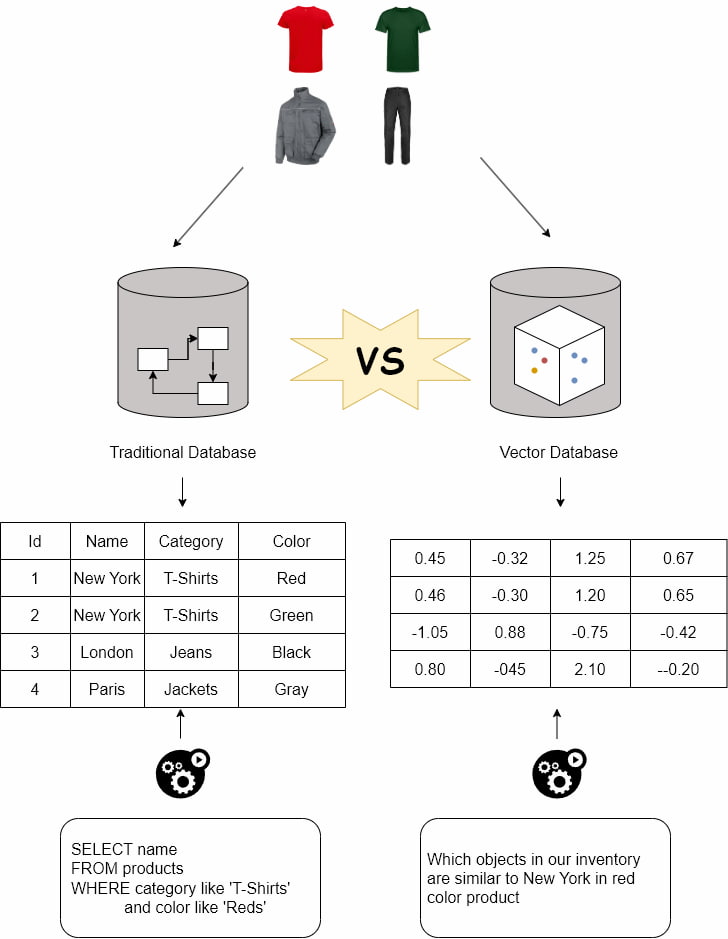
Let's consider a simple example with a numerical representation of words, where the words are the definition of each fashion retail product stored in our transaction database. Imagine if we could capture the essence of these targets with only two dimensions.
Figure 5: Array of embeddings
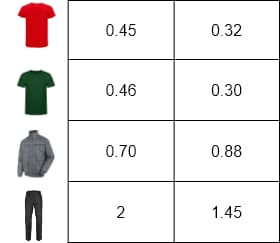
In Figure 6, we can see the dimensional representation of these objects to visualize their similarity. T-shirts are closer because both are the same product with different colors. The jacket is closer to t-shirts because they share attributes like sleeves and a collar. Furthest to the right are the jeans that do not share attributes with the other products.
Figure 6: Dimensional map

Obviously, with two dimensions, we cannot capture the essence of the products. Dimensionality plays a crucial role in how well these embeddings can capture the relevant features of the products. More dimensions may provide more accuracy but also more resources in terms of compute, memory, latency, and cost.
Vector Embedding Models Integration
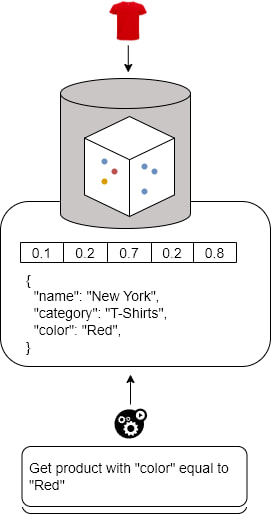
Some vector databases provide seamless integration with embedding models, allowing us to generate vector embeddings from raw data and seamlessly integrate ML models into database operations. This feature simplifies the development process and abstracts away the complexities involved in generating and using vector embeddings for both data insertion and querying processes.
Figure 7: Embeddings generation patterns
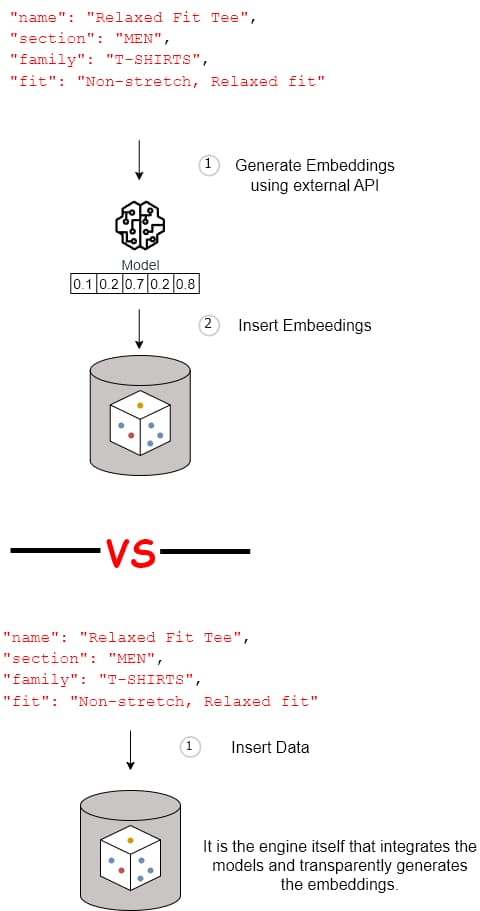
Table 1: Embedding generation comparative
| Examples |
Without Integration |
With Model Integrations |
| Data ingestion |
1. Before we can insert each object, we must call our Model to generate a vector embedding.
2. Then, we can insert our data with the vector. |
We can insert each object directly into the vector database, delegating the transformation to the database. |
| Query |
1. Before we run a query, we must call our Model to generate a vector embedding from our query first.
2. Then, we can run a query with that vector. |
We can run a query directly in the vector database, delegating the transformation to the database. |
Distance Metrics and Similarity
Distance metrics are mathematical measures and functions used to determine the distance (similarity) between two elements in a vector space. In the context of embeddings, distance metrics evaluate how far apart two embeddings are. A similarity query search retrieves the embeddings that are similar to a given input based on a distance metric; this input can be a vector embedding, text, or another object. There are several distance metrics. The most popular ones are the following.
Cosine Similarity
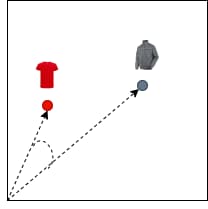
Cosine similarity measures the cosine of the angle between two vector embeddings, and it's often used as a distance metric in text analysis and other domains where the magnitude of the vector is less important than the direction.
Figure 8: Cosine
Euclidean Distance
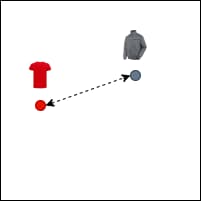
Euclidean distance measures the straight-line distance between two points in Euclidean space.
Figure 9: Euclidean
Manhattan Distance
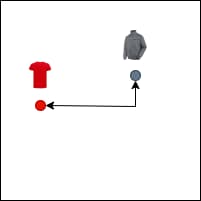
Manhattan distance (L1 norm) sums the absolute differences of their coordinates.
Figure 10: Manhattan
The choice of distance metric and similarity measure has a profound impact on the behavior and performance of ML models; however, the recommendation is to use the same distance metric as the metric used to train the given model.
Vector Indexes
Vector indexes are specialized data structures designed to efficiently store, organize, and query high-dimensional vector embeddings. These indexes provide fast search queries in a cost-effective way. There are several indexing strategies that are optimized for handling the complexity and scale of the vector space. Some examples include:
- Approximate nearest neighbor (ANN)
- Inverted index
- Locality-sensitive hashing (LSH)
Generally, each database implements a subset of these index strategies, and in some cases, they are customized for better performance.
Scalability
Vector databases are usually highly scalable solutions that support vertical and horizontal scaling. Horizontal scaling is based on two fundamental strategies: sharding and replication. Both strategies are crucial for managing large-scale and distributed databases.
Sharding
Sharding involves dividing a database into smaller, more manageable pieces called shards. Each shard contains a subset of the database's data, making it responsible for a particular segment of the data.
Table 2: Key sharding advantages and considerations
| Advantages |
Considerations |
| By distributing the data across multiple servers, sharding can reduce the load on any single server, leading to improved performance. |
Implementing sharding can be complex, especially in terms of data distribution, shard management, and query processing across shards. |
| Sharding allows a database to scale by adding more shards across additional servers, effectively handling more data and users without degradation in performance. |
Ensuring even distribution of data and avoiding hotspots where one shard receives significantly more queries than others can be challenging. |
| It can be cost effective to add more servers with moderate specifications than to scale up a single server with high specifications. |
Query throughput does not improve when adding more sharded nodes. |
Replication
Replication involves creating copies of a database on multiple nodes within the cluster.
Table 3: Key advantages and considerations for replication
| Advantages |
Considerations |
| Replication ensures that the database remains available for read operations even if some servers are down. |
Maintaining data consistency across replicas, especially in write-heavy environments, can be challenging and may require sophisticated synchronization mechanisms. |
| Replication provides a mechanism for disaster recovery as data is backed up across multiple locations |
Replication requires additional storage and network resources, as data is duplicated across multiple servers. |
| Replication can improve the read scalability of a database system by allowing read queries to be distributed across multiple replicas. |
In asynchronous replication setups, there can be a lag between when data is written to the primary index and when it is replicated to the secondary indexes. This lag can impact applications that require real-time or near-real-time data consistency across replicas. |
Use Cases
Vector databases and embeddings are crucial for several key use cases, including semantic search, vector data in generative AI, and more.
Semantic Search
You can retrieve information by leveraging the capabilities of vector embeddings to understand and match the semantic context of queries with relevant content. Searches are performed by calculating the similarity between the query vector and document vectors in the database, using some of the previously explained metrics, such as cosine similarity. Some of the applications would be:
- Recommendation systems: Perform similarity searches to find items that match a user's interests, providing accurate and timely recommendations to enhance the user experience.
- Customer support: Obtain the most relevant information to solve customers' doubts, questions, or problems.
- Knowledge management: Find relevant information quickly from the organization's knowledge composed by documents, slides, videos, or reports in enterprise systems.
Vector Data in Generative AI: Retrieval-Augmented Generation
Generative AI and large language models (LLMs) have certain limitations given they must be trained with a large amount of data. These trainings impose high costs in terms of time, resources, and money. As a result, these models are usually trained with general contexts and are not constantly updated with the latest information.
Retrieval-augmented generation (RAG) plays a crucial role because it was developed to improve the response quality in specific contexts using a technique that incorporates an external source of relevant and updated information into the generative process. A vector database is particularly well suited for implementing RAG models due to its unique capabilities in handling high-dimensional data, performing efficient similarity searches, and integrating seamlessly with AI/ML workflows.
Figure 11: Overview of RAG architecture
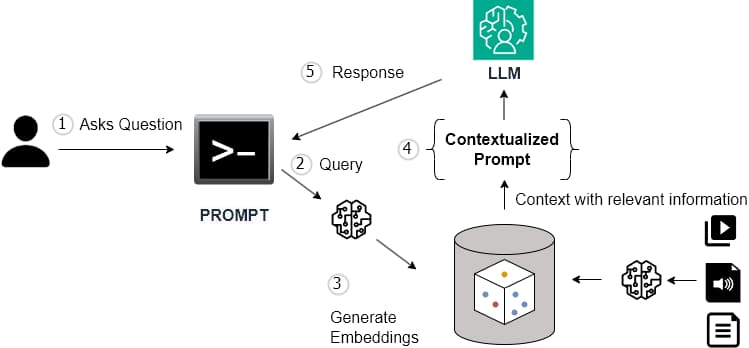
Using vector databases in the RAG integration pattern has the following advantages:
- Semantic understanding: Vector embeddings capture the nuanced semantic relationships within data, whether text, images, or audio. This deep understanding is essential for generative models to produce high-quality, realistic outputs that are contextually relevant to the input or prompt.
- Dimensionality reduction: By representing complex data in a lower-dimensional vector space, this is aimed to reduce vast datasets to make it feasible for AI models to process and learn from.
- Quality and precision: The precision of similarity search in vector databases ensures that the information retrieved for generation is of high relevance and quality.
- Seamless integration: Vector databases provide APIs, SDKs, and tools that make it easy to integrate with various AI/ML frameworks. This flexibility facilitates the development and deployment of RAG models, allowing researchers and developers to focus on model optimization rather than data management challenges.
- Context generation: Vector embeddings capture the semantic essence of text, images, videos, and more, enabling AI models to understand context and generate new content that is contextually similar or related.
- Scalability: Vector databases provide a scalable solution that can manage large-scale information without compromising retrieval performance.
Vector databases provide the technological foundation necessary for the effective implementation of RAG models and make them an optimal choice for interaction with large-scale knowledge bases.
Other Specific Uses Cases
Beyond the main use cases discussed above are several others, such as:
- Anomaly detection: Embeddings capture the nuanced relationships and patterns within the data, making it possible to detect anomalies that might not be evident through traditional methods.
- Retail comparable products: By converting product features into vector embeddings, retailers can quickly find products that are similar in characteristics (e.g., design, material, price, sales).