Introduction
Why Search and Why Graph
Search is a key feature of most applications. Users search for products, places, other users, documents, and more. And while structured search was common for early applications, today, driven by the ubiquity of internet search engines, full-text search dominates the usage.
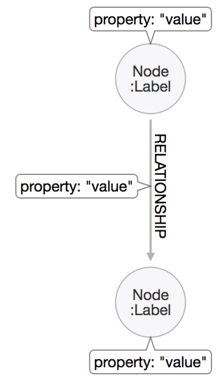
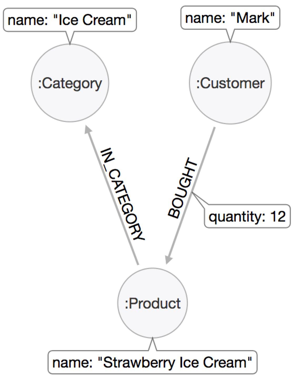
The world around us consists of connected information. Being able to store and query those rich networks of data allows us to support decisions, make recommendations, and predict impacts. Graph databases enable both transactional as well as analytical uses on top of our highly connected domains.
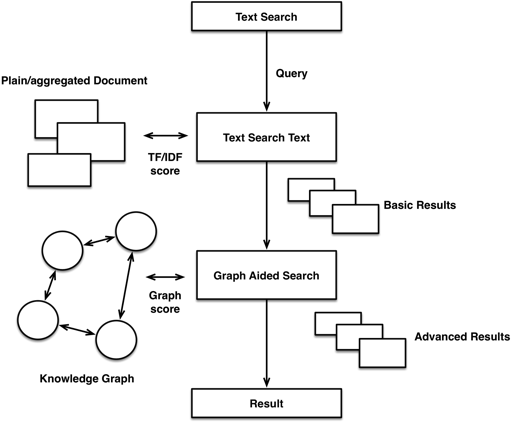
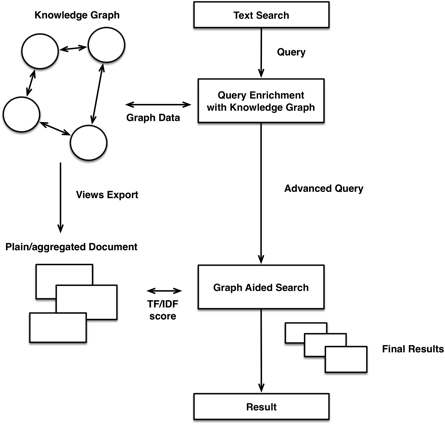
Bringing both together allows us to enhance search results with graph-based capabilities like recommendation features or concept search, and also to use advanced search results as entry points to graph traversals.
Our Use Case: Multi-Faceted Search with Recommendations
Each domain has specific expectations in terms of search relevance and a different set of issues, constraints, and requirements.
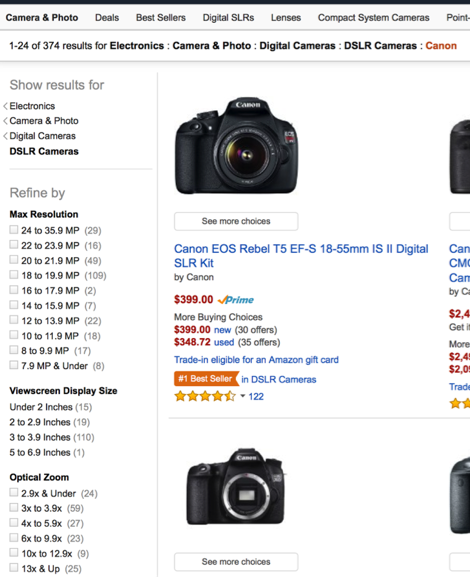
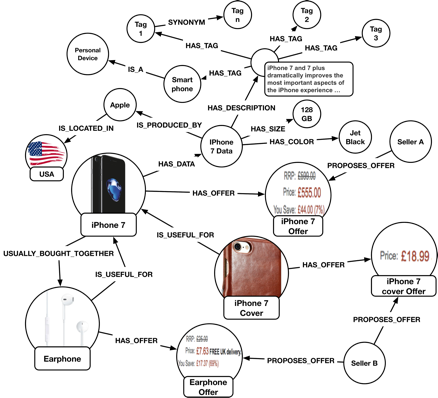
Our use case example is product search, used by any retailer (Amazon, eBay, Target, etc.).
Text search and catalog navigation are not only the entry points for users but they are also the main “salespeople”. Compared to other search engines, the set of “items” to be searched is more controlled and regulated.
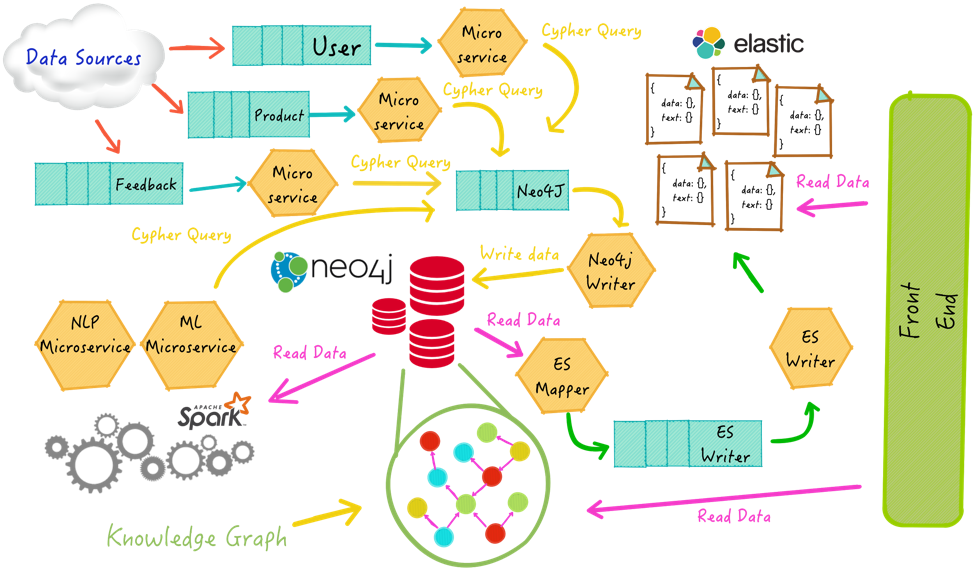
For the search infrastructure, these aspects have to be taken into account:
- Multiple data sources: Products and related information come from various heterogeneous sources like product suppliers, information providers, and sellers.
- Marketing strategy: New promotions, offers, and marketing campaigns are created to promote the site or specific products. All of them should affect results boosting.
- Personalization: In order to provide a better and more customized user experience, clicks, purchases, search queries, and other user signals must be captured, processed, and used to personalize search results.
- Provider information: Product suppliers are the most important. They provide information like quantity, availability, delivery options, timing, and changes in the product’s details.
All these requirements and data sources affect search results in several ways. Designing a search infrastructure for e-commerce vendors requires an entire ecosystem of data and related data flows together with platforms to manage them.