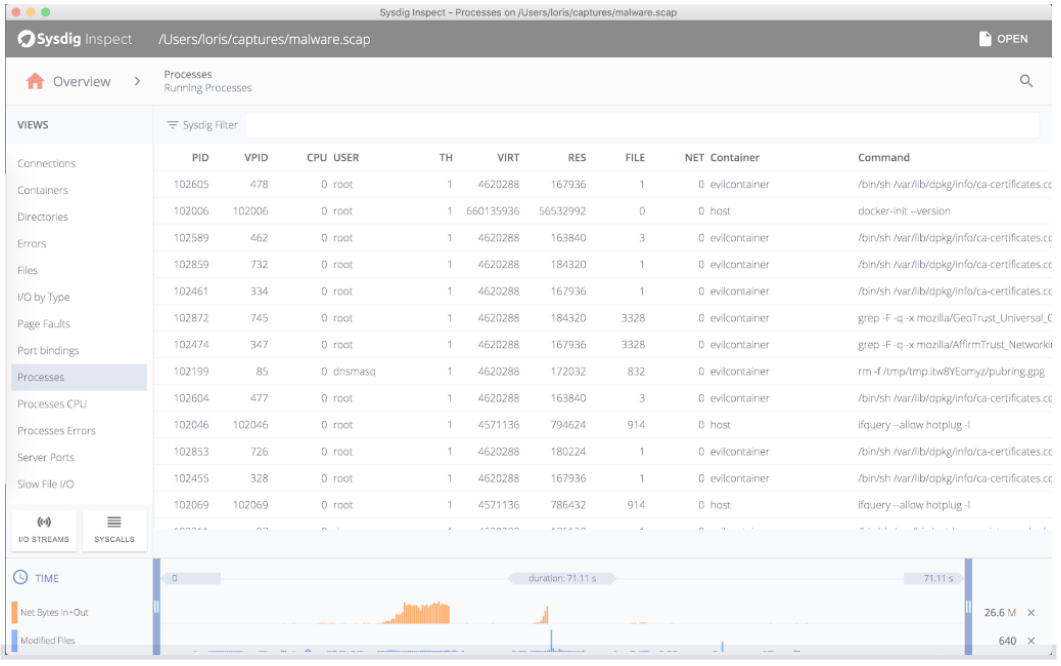
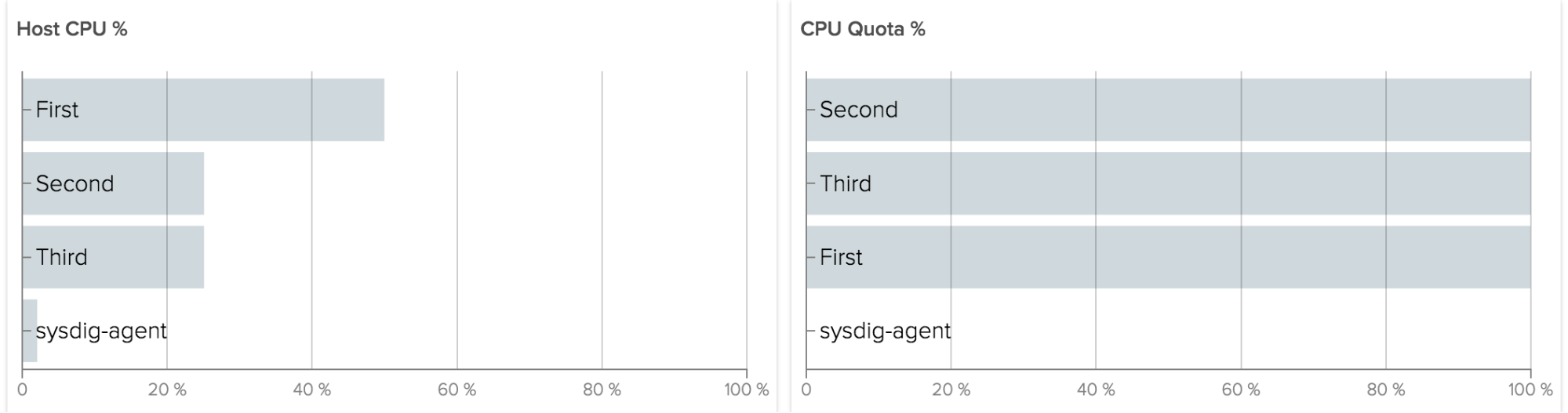
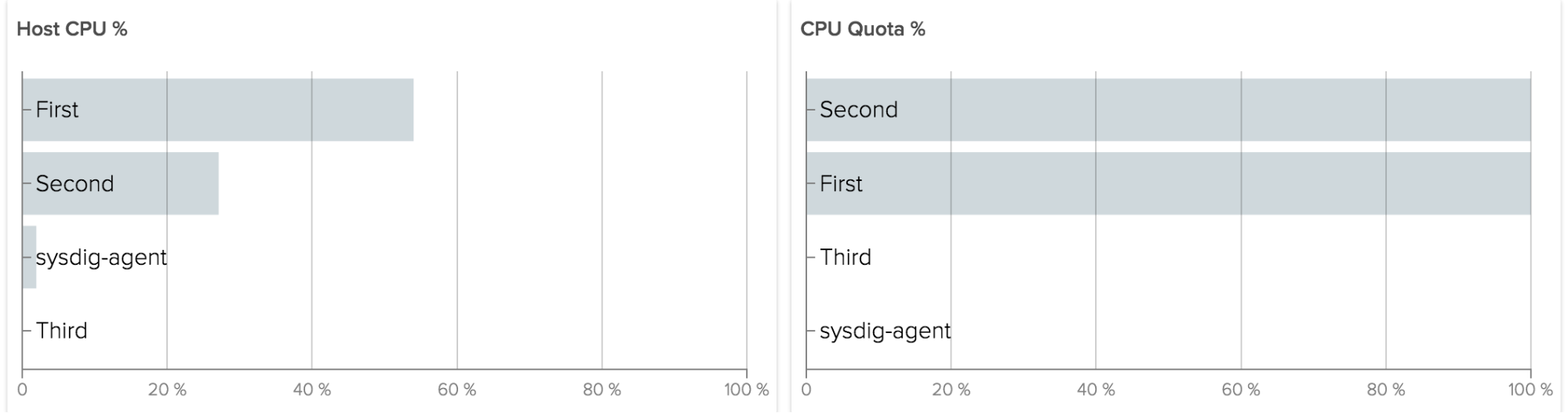
Regardless of your platform, some things don’t change… and that’s certainly true when it comes to networking data. Especially with Docker in the mix, networking can become more complex and communication patterns can become more convoluted. It’s important to keep track of basic information, e.g. how much data a container is consuming and emitting.
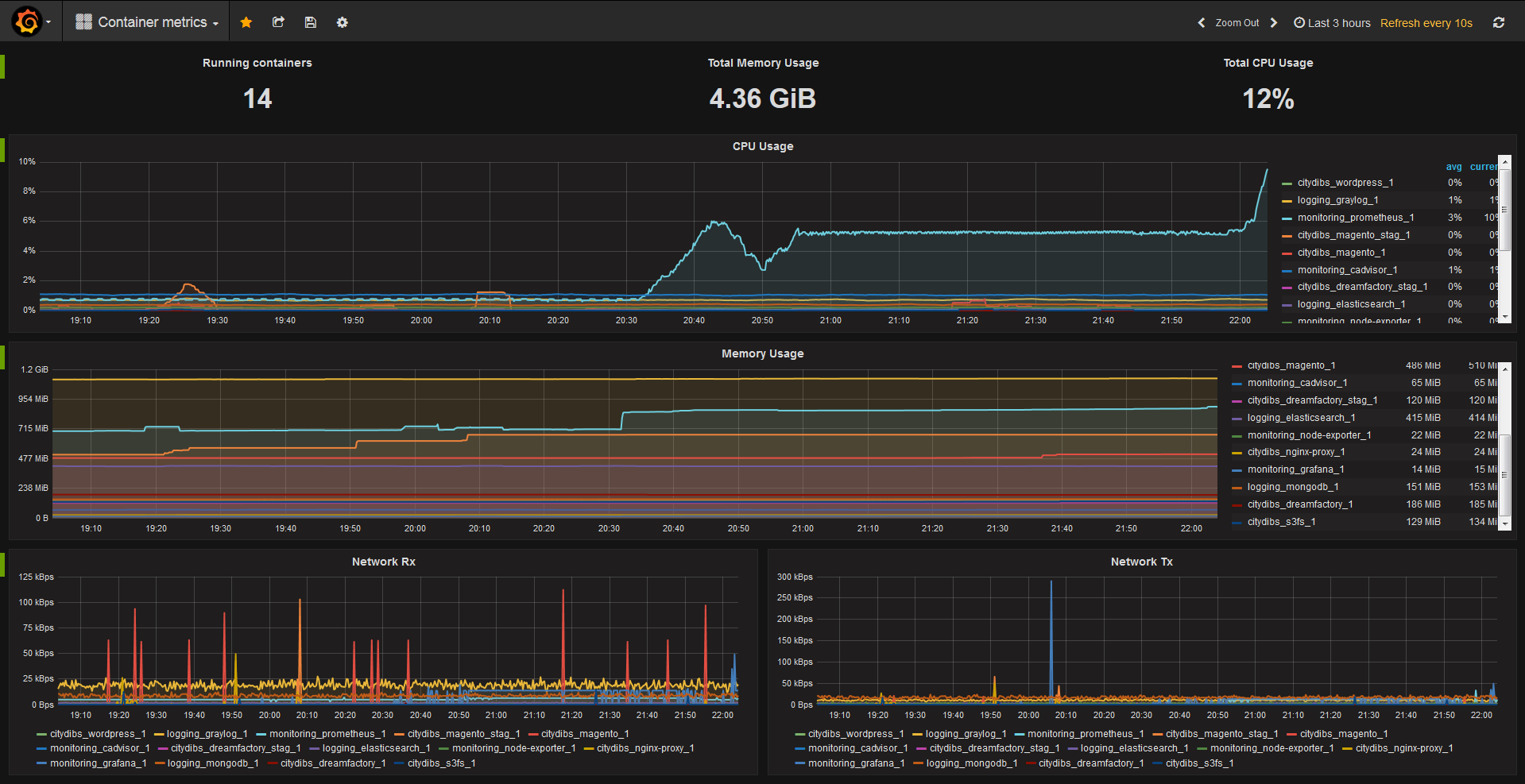
This type of data collection requires something more full-featured than the Docker API, so instead, you could collect this type of information from open-source Sysdig. Let’s look at some basic network data for a set of containers, each running the same Java application:

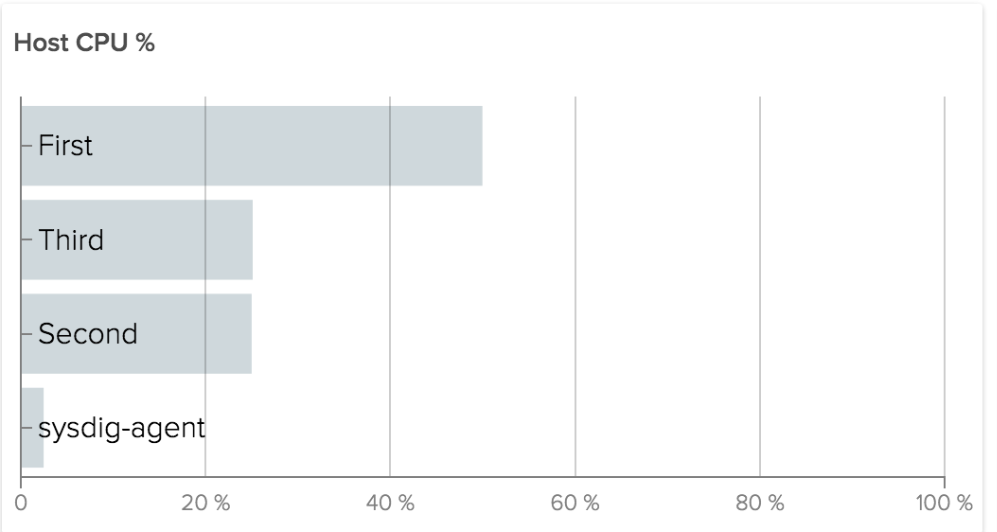
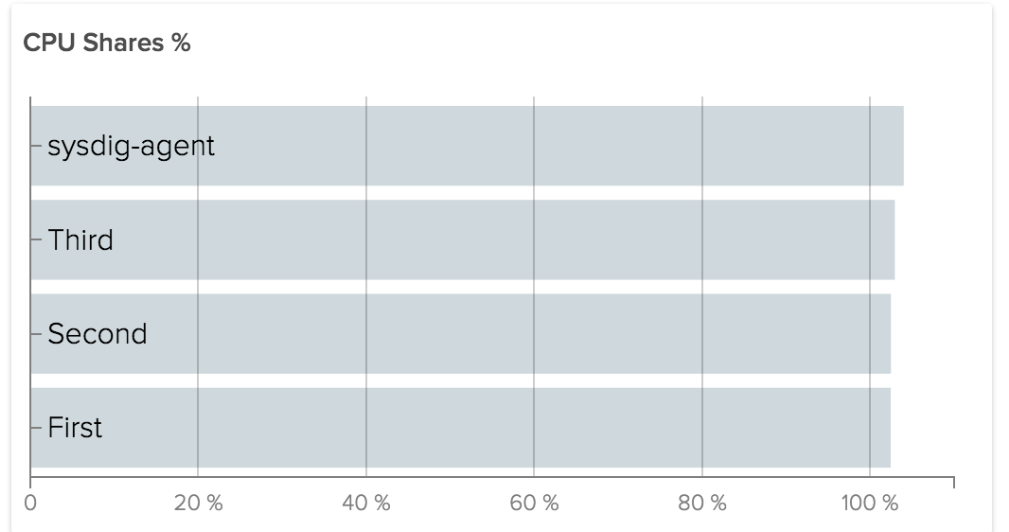
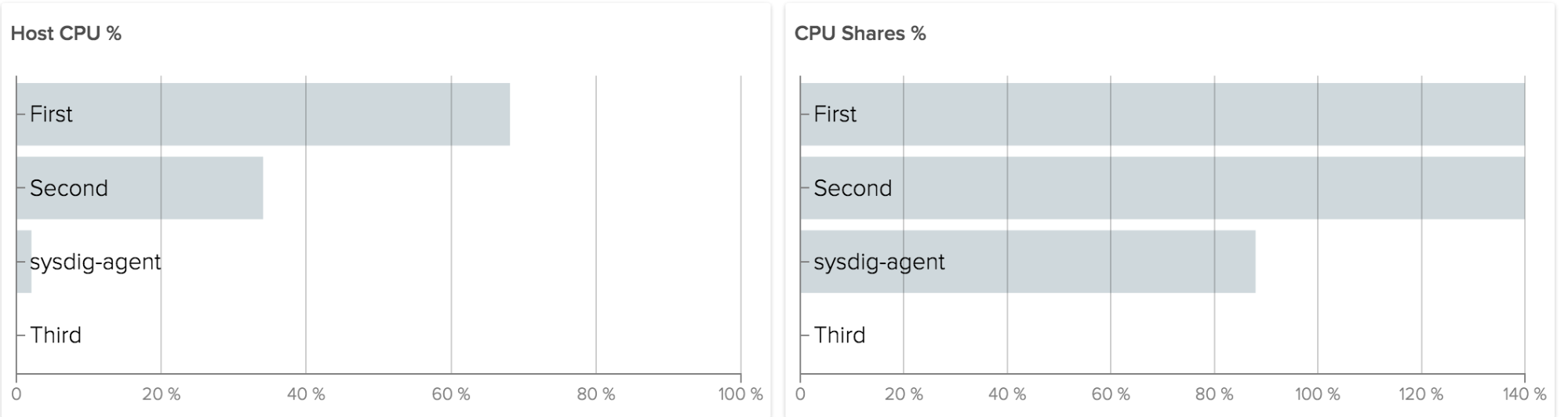
As you can see, there is some slight variation between the containers. If, however, we see an extreme variation, we may want to investigate further.
At the same time, since these containers are each running the same Java application, it may be more useful to consider them a “service” and see how they are performing in aggregate. This leads up to our last example.
From Container to Microservice Data With Labels
Docker and Kubernetes provide “labels.” These are much like they sound — additional, contextual information is applied on a per-container basis. They are unstructured and non-hierarchical, though basic tags in Kubernetes do have a hierarchy. As such, you can use them to broadly identify subcategories of your containers. All the containers of a given service could carry the same label, non-standard containers could carry another label, and different versions of software could have yet another label. If you’re a filer and an organizer, labels will be heaven for you.
So, what can we do with a label? Well, the first thing is that we can aggregate data. From the example above, let’s suppose we applied the label “javaapp” to our containers. Now, when we show our network data, we see something much simpler:

One line — that’s it. In this case, we’re showing the average network data across the containers, but you could easily calculate anything that helps you better understand the performance of this collection of containers.
But let’s go a little further with labels, network data, and the “top connections” example we showed in the open-source section.
Using this information and an appropriate visualization, we can do more than create a table of network data: we can actually create a map of our services, the containers that make them up, and who they are communicating with. Here, we can see the aggregated Java service orchestrated by Kubernetes, the individual containers that make up the service, and (in a more complete view) the other services in your environment that the Java service communicates with. Note that this is a little more advanced than the other examples, and the visualization in particular may require some coding in D3 or something similar if you want to stay fully open-source.
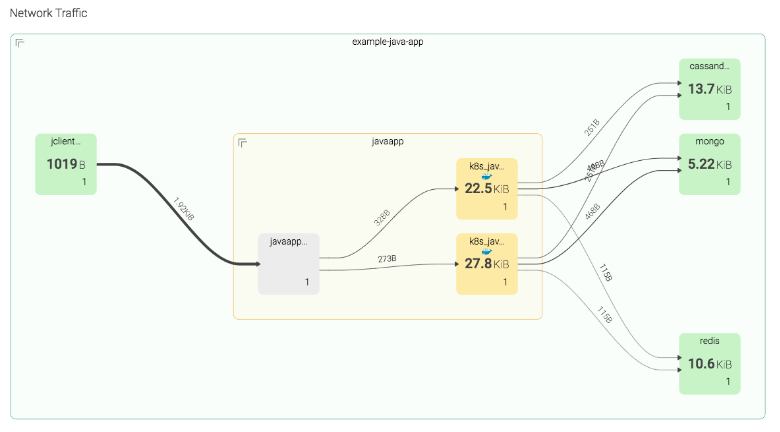
Here, we see a few different things: Our “javaapp” consists of two containers (yellow) and a service called “javaapp” (gray), which is just an abstraction created by whoever is routing requests to those containers. We see each of the Java app containers communicating with a Cassandra service, a Mongo service, and a Redis service, and presumably, those are made up of containers, as well (hidden here to avoid too much complexity).
This view helps us in a few different ways:
- We quickly can understand the logical composition of our application.
- We can aggregate containers into higher-level services.
- We can easily see communication patterns among containers.
- We may be able to easily spot outliers or anomalies.