
The Hidden Value of Your CI/CD Pipeline
Today’s world is driven by rapid change. Failing to keep up with the pace of the evolution of technology and business models might lead even a large corporation to collapse in the blink of an eye. DevOps allows software, and thus businesses, to increase the speed of development and adapt to an ever-changing market, maintaining a level of quality and reliability that meet customers’ expectations.
There is a lot of pressure on dev teams to release on time, and decreasing the time-to-market is essential in today’s highly competitive environment.
When something goes wrong with a software release, the costs associated can be overwhelming, going from urgently producing patches to rolling back to the previous version when possible, if not having to re-engineer or even redesign significant portions of the software.
What we lack is proper visibility into the development process that would allow us to estimate the risks attached to a software release correctly. We want to have historical data to analyze and estimate a probabilistic measure of the success of a new release.
The Continuous Integration and Continuous Delivery (CI/CD, for short) pipeline is the engine that drives the DevOps methodology and allows teams to streamline the iterations of software changes from the initial idea to the rollout to the entire customer base. With a fast and efficient CI/CD pipeline, all the people involved in the design, implementation, testing, and rollout of software changes can work together and communicate seamlessly at any stage.
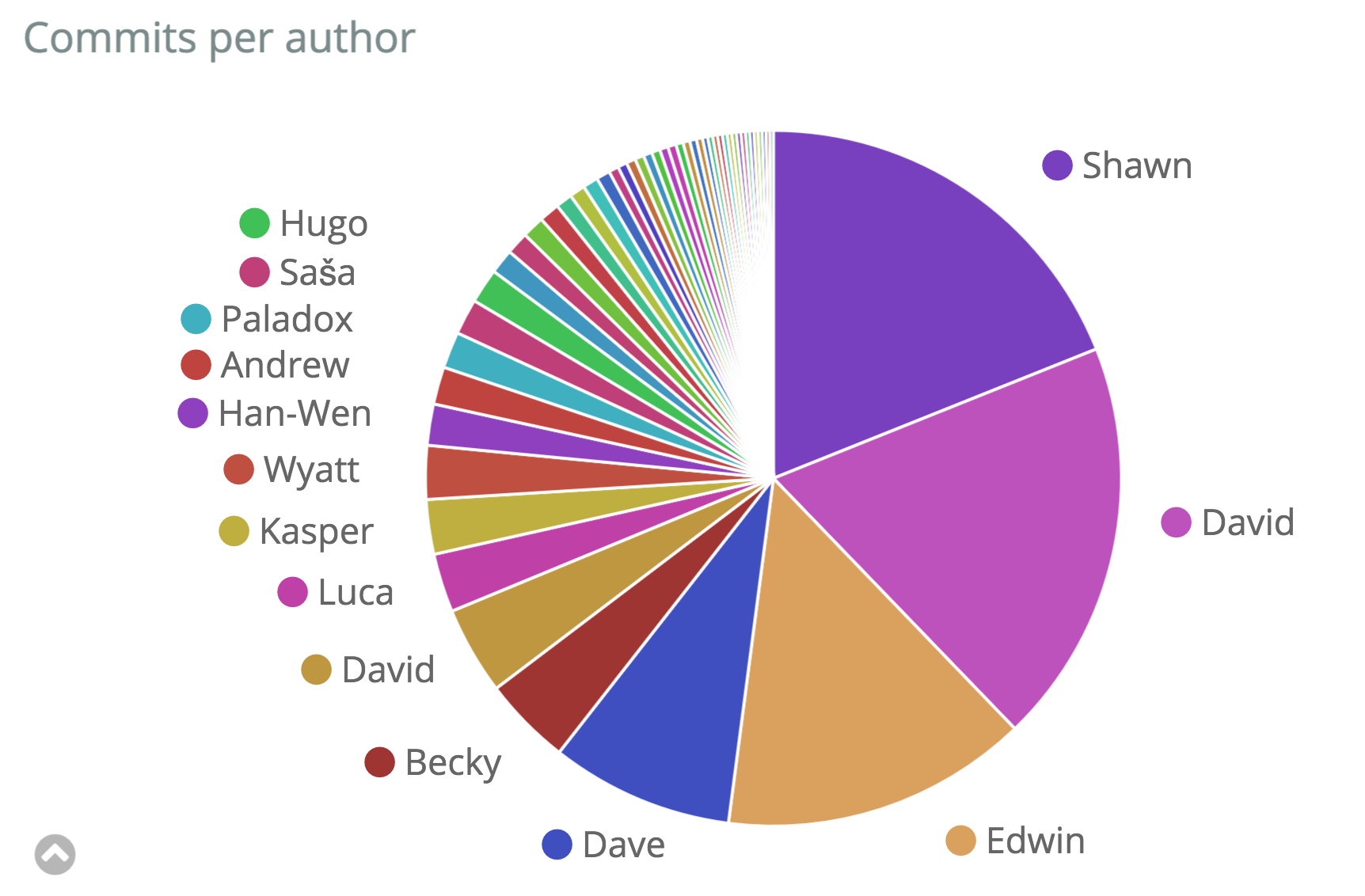
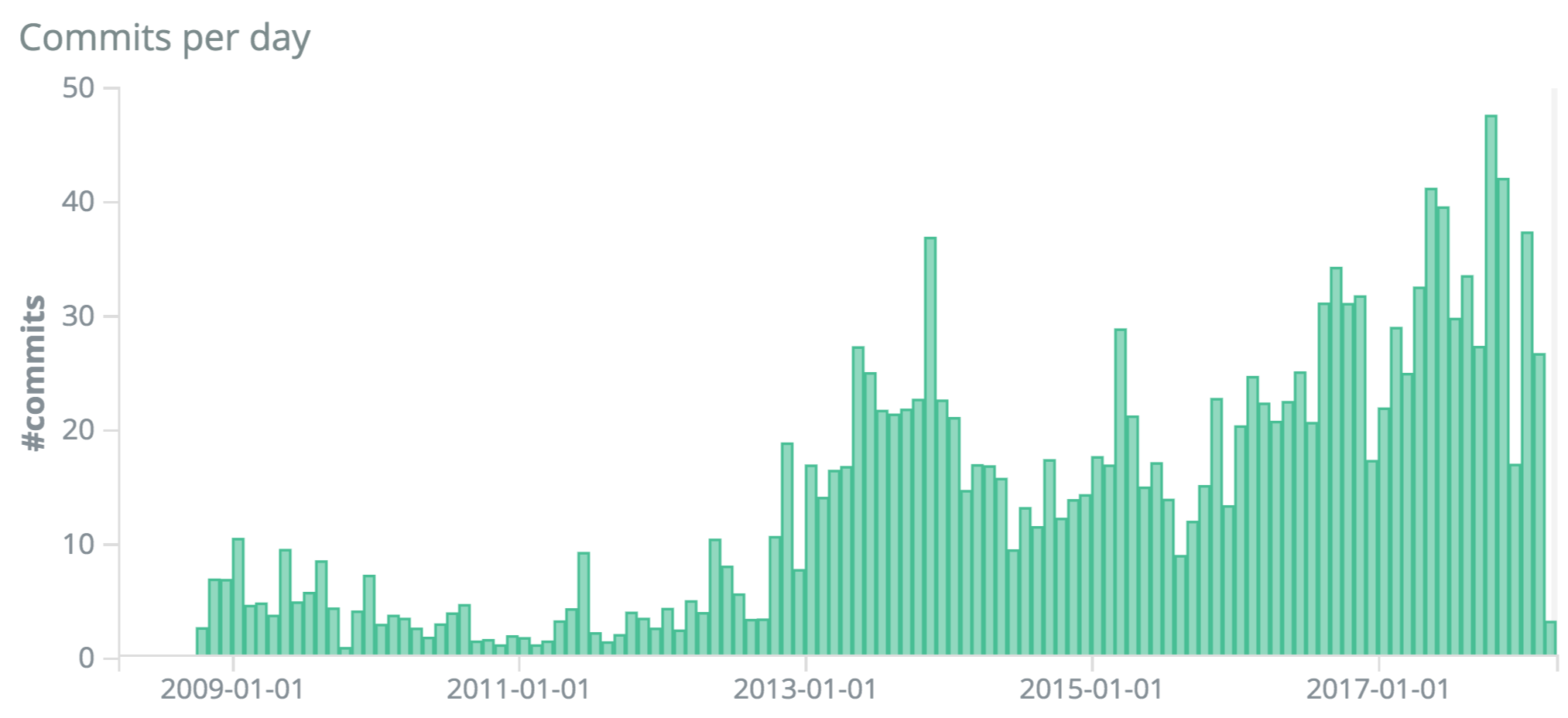
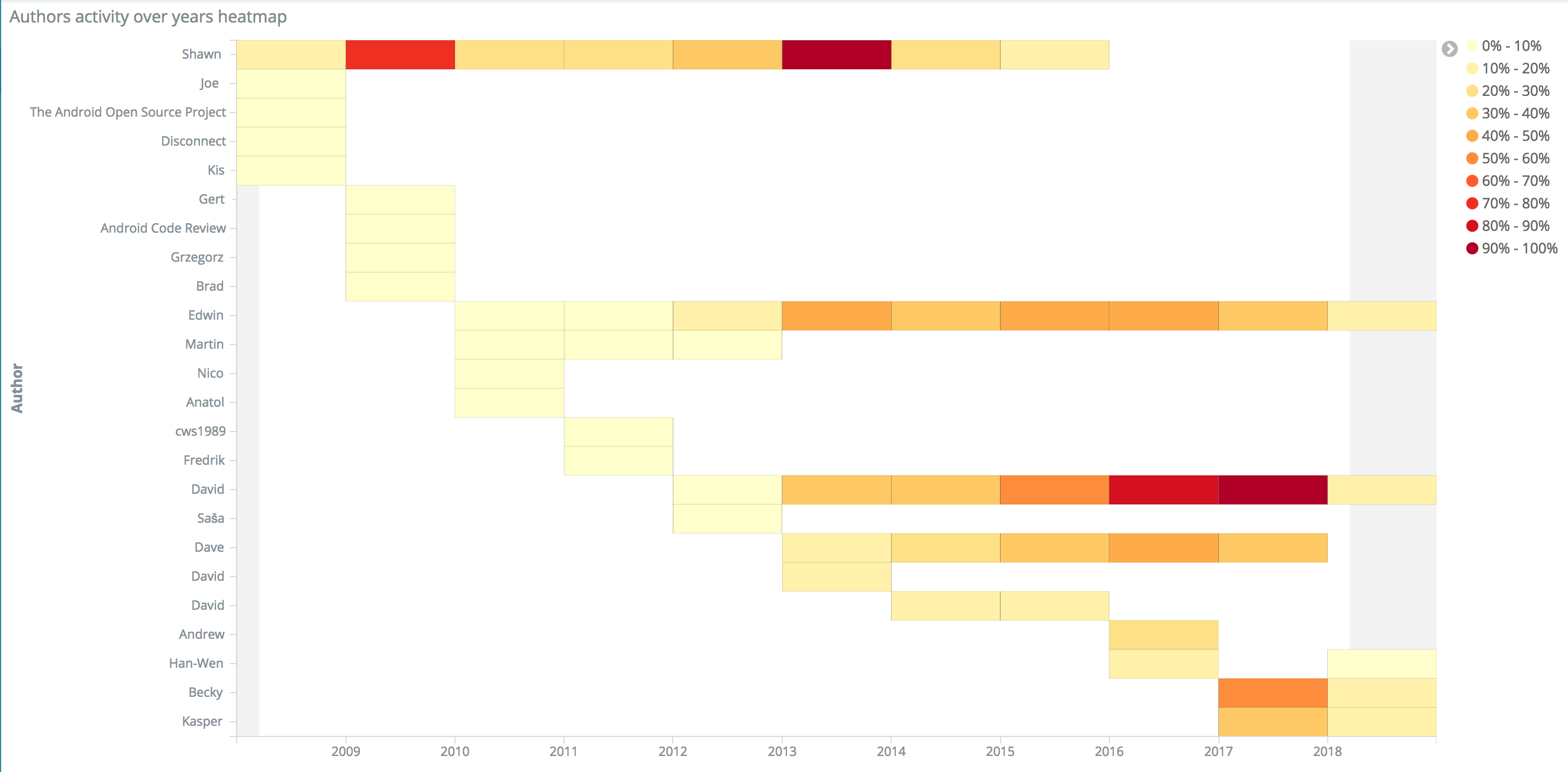
The CI/CD pipeline produces a lot of logs and events during every stage, including audits and comments on the issue, reviews on the code changes, build logs and tests result up to the deployment, and production logs. The sheer amount and size of that information lead many organizations to stash or even discard most of them. The collection, storage, and analysis of that data allow us to understand and improve the entire E2E DevOps pipeline.
The aim of DevOps analytics is to uncover the hidden value of CI/CD logs and events and demonstrate various benefits at different levels.
Each employee needs to see what is relevant to them in a form that is suitable to their skills and understanding:
| Release Engineer | Product Manager | Delivery Manager | Head of Engineering | |
|---|---|---|---|---|
| Form | Deeply technical with deep links | Functional feature-based view | Timeline view of deliveries | Deliveries by dev teams |
| Value | Improve pipeline stability | Reduce time-to-market, maximize customer satisfaction | Prevent delays and minimize post-release issues | Maximize team cooperation, minimize risks related to a release |

{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}