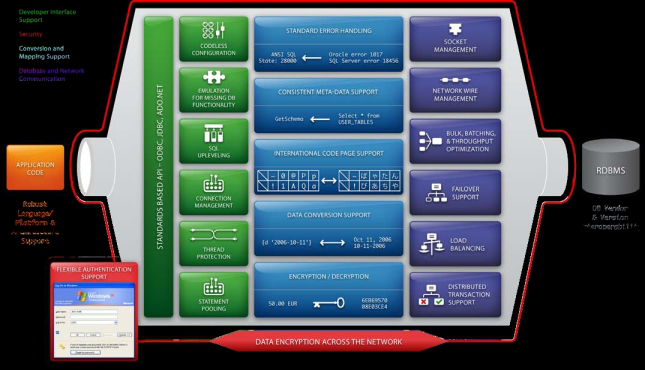
These advanced features are complex and meant as an overview. For all the bells and whistles for these advanced options, check your JDBC driver documentation!
Debugging and Logging
Well-written JDBC drivers offer ways to log the JDBC calls going through the driver for debugging purposes. As an example, to enable logging with some JDBC drivers, you simply set a connection option to turn on this spying capability:
Codeless Configuration (Hibernate and JPA)
Codeless Configuration is the ability to change driver behavior without having to change application code. Using a driver under something like Hibernate or JPA means that the user cannot use proprietary extensions to the JDBC objects and should instead control and change driver behavior through connection options.
Additionally, codeless configuration is the ability to monitor and change JDBC driver behavior while the driver is in use. For example, using a tool like JConsole to connect to a driver exported MBean and check the PreparedStatement pool stats as well as importing/exporting new statements on the fly to fine tune application performance.
Encrypt Your Data Using SSL
Ensure that your data is secure by encrypting the wire traffic between the server and client using SSL encryption:
- Set the EncryptionMethod connect option to SSL.
- Specify the location and password of the trustStore file used for SSL server authentication. Set connect options or system properties (javax.net.ssl.trustStore and javax.net.ssl.trustStorePassword).
- If your database server is configured for SSL client authentication, configure your keyStore information:
- Specify the location and password of the keyStore file. Either set connect options or Java system properties (javax.net.ssl.keyStore and javax.net.ssl.keyStorePassword).
- If any key entry in the keyStore file is passwordprotected,set the KeyPassword property to thekey password.
Single Sign-on With Kerberos
Kerberos is an authentication protocol, which enables secure proof of identity over a non-secure network. It is also used for enabling single sign-on across multiple sites by delegating credentials. To enable Kerberos:
- Set the authenticationMethod connect option to Kerberos.
- Modify the krb5.conf file to contain your Kerberos realm and the KDC name for that realm. Alternatively, you can set the java.security.krb5.realm and java.security.krb5.kdc system properties.
- If using Kerberos authentication with a Security Manager,grant security permissions to the application and driver.

These security features are not supported by all databases and database versions. Check to ensure your database is setup appropriately before attempting Kerberos and SSL connections.
Application Failover
Application failover is the ability for a driver to detect a connection failure and seamlessly reconnect you to an alternate server. Various types of failover exist for JDBC drivers so check your driver documentation for support - the most common are listed below:
| Connection Failover |
In the case of the primary connection being unavailable, the connection will be established with the alternate server. |
| Extended Failover |
While the application is running, if a connection failover occurs, the driver will reconnect to an alternate server and post a transaction failure to the application. |
| Select Failover |
Same as extended, except instead of posting a transaction failure, this level will reposition any ResultSets, so the application will not know there was a failure at all. |
Bulk Loading
Loading large amounts of data into a database quickly requires something more powerful than standard addBatch(). Database vendors offer a way to bulk load data, bypassing the normal wire protocol and normal insert procedure. There are 2 ways to use Bulk Loading with a JDBC driver that supports it:
- Set enableBulkLoad connect option to true. This will make addBatch() calls use the bulk load protocol over the wire.
- Use a Bulk Load object:

For additional Bulk Load options, check the JDBC driver documentation.