Transformations are used to express the business logic of a streaming application. On the low level, a processing task receives some stream items, performs arbitrary processing, and emits some items. It may emit items even without receiving anything (acting as a stream source) or it may just receive and not emit anything (acting as a sink).
Due to the nature of distributed computation, you can’t just provide arbitrary imperative code that processes the data — you must describe it declaratively. This is why streaming applications share some principles with functional and dataflow programming. This requires some time to get used to when coming from the imperative programming.
Hazelcast Jet’s Pipeline API is one such example. You compose a pipeline from individual stages, each performing one kind of transformation. A simple map stage transforms items with a stateless function; a more complex windowed group-and-aggregate stage groups events by key in an infinite stream and calculates an aggregated value over a sliding window. You provide just the business logic such as the function to extract the grouping key, the definition of the aggregate function, the definition of the sliding window, etc.
We have already mentioned that a stream is a sequence of isolated records. Many basic transformations process each record independently. Such a transformation is stateless.
These are the main types of stateless transformation:
Map transforms one record to one record, e.g.hange format of the record, enrich record with some data.Filter filters out the records that doesn’t satisfy the predicate.FlatMap is the most general type of stateless transformation, outputting zero or more records for each input record, e.g. tokenize a record containing a sentence into individual words.
However, many types of computation involve more than one record. In this case, the processor must maintain internal state across the records. When counting the records in the stream, for example, you have to maintain the current count.
Stateful transformations:
- Aggregation: Combines all the records to produce a single value, e.g.
min, max, sum, count, avg.
- Group-and-aggregate: Extracts a grouping key from the record and computes a separate aggregated value for each key.
- Join: Joins same-keyed records from several streams.
- Sort: Sorts the records observed in the stream.
This code samples shows both stateless and stateful transformations:
logs.map(LogLine::parse)
.filter((LogLine log) -> log.getResponseCode() >= 200 && log.getResponseCode() < 400)
.flatMap(AccessLogAnalyzer::explodeSubPaths)
.groupingKey(wholeItem())
.aggregate(counting());
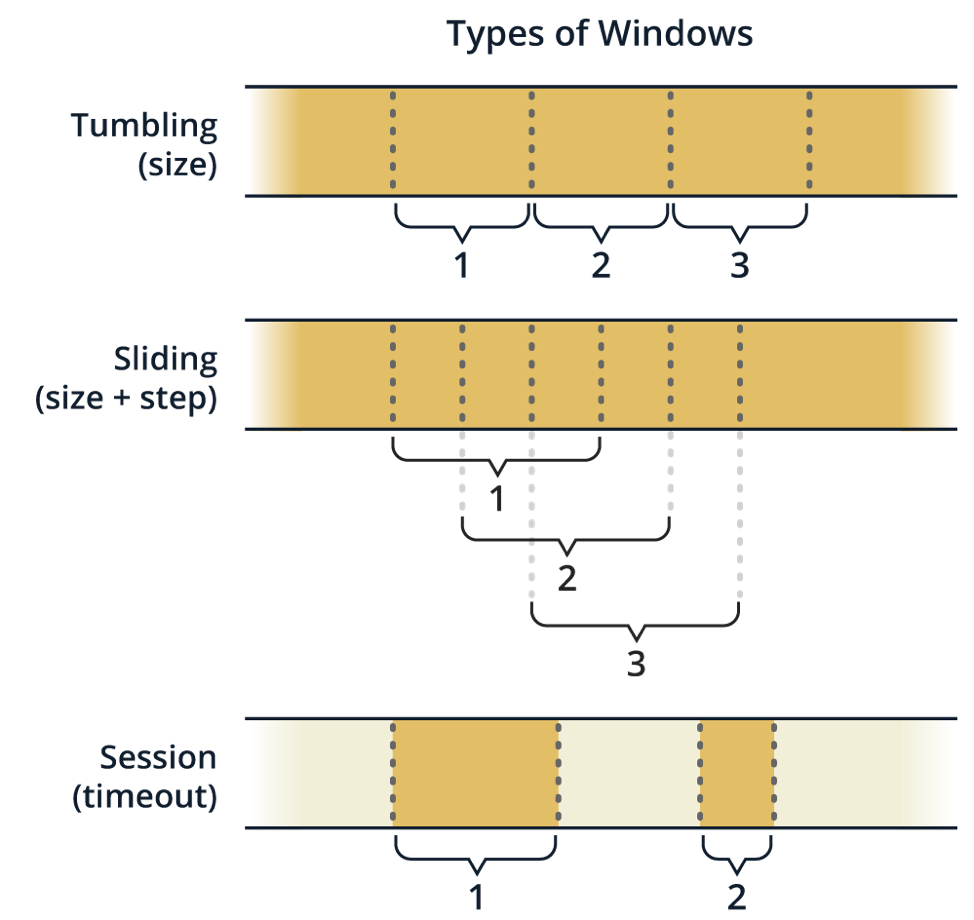
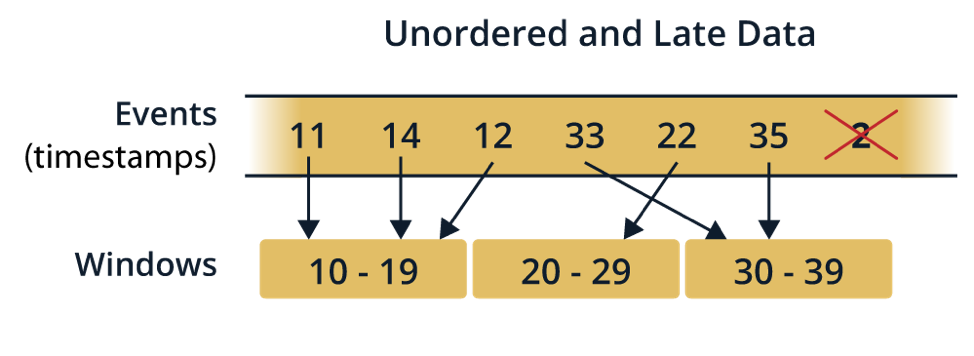
In the most general case, the state of stateful transformations is affected by all the records observed in the stream, and all the ingested records are involved in the computation. However, we’re mostly interested in something like “stats for last 30 seconds” instead of “stats since streaming app was started” (remember: the stream is generally infinite). This is where the concept of windowing enters the picture — it meaningfully bounds the scope of the aggregation. See the Windowing section.
Keyed or Non-Keyed Aggregations
You often need to classify records by a grouping key, thereby creating sub-streams containing just the records with the same grouping key. Each record group is then processed separately. This fact can be leveraged for easy parallelization by partitioning the data stream on the grouping key and letting independent threads/processes/machines handle records with different keys.
Examples of Keyed Aggregations
This example processes a stream of text snippets (tweets or anything else) by first splitting them into individual words and then performing a windowed group-and-aggregate operation. The aggregate function is simply counting the items in each group. This results in a live word frequency histogram that updates as the window slides along the time axis. Although quite a simple operation, it gives a powerful insight into the contents of the stream.
tweets.flatMap(tweet ->
traverseArray(tweet.toLowerCase().split("\\W+")))
.window(sliding(10_000, 100))
.groupingKey(wholeItem())
.aggregate(counting(),
(start, end, word, frequency) -> entry(word, frequency));
Another example of keyed aggregation could be gaining insight into the activities of all your users. You key the stream by user ID and write your aggregation logic focused on a single user. The processing engine will automatically distribute the load of processing user data across all the machines in the cluster and all their CPU cores.
Example of Non-Keyed (Global) Aggregation
This example processes a stream of reports from weather stations. Among the reports from the last hour, it looks for the one that indicated the strongest winds.
weatherStationReports
.window(sliding(HOURS.toMillis(1), MINUTES.toMillis(1)))
.aggregate(maxBy(comparing(WeatherStationReport::windSpeed)),
(start, end, station) -> entry(end, station));
A general class of use cases where non-keyed aggregation is useful are complex event processing (CEP) applications. They search for complex patterns in the data stream. In such a case, there is no a priori partitioning you can apply to the data; the pattern-matching operator needs to see the whole dataset to be able to detect a pattern.

{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}