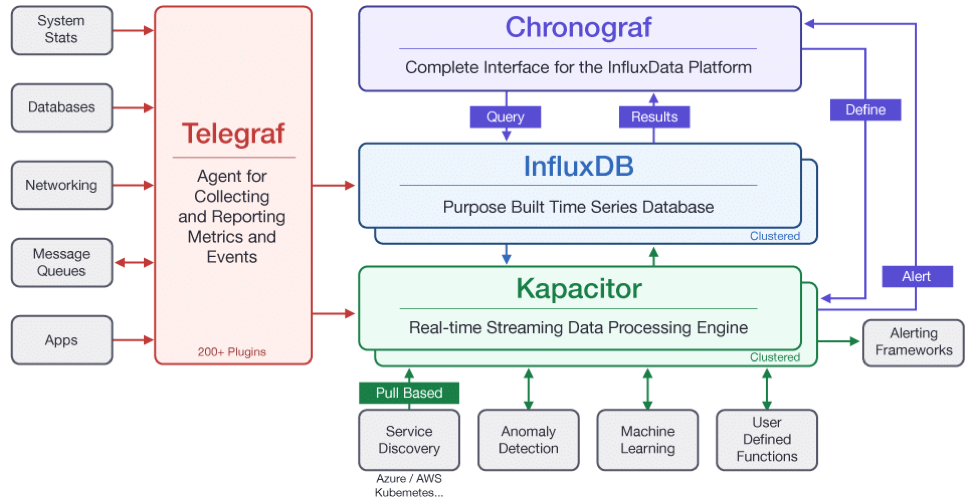
The easiest way to get a feel for what time series data can do for you is to try it. Since the TICK Stack is open source, you can freely ,download and install Telegraf, InfluxDB, Chronograf and Kapacitor. Let’s start with InfluxDB, feed some data, and build some queries.
With InfluxDB installed, it is time to interact with the database. Let’s use the command line interface (influx) to write data manually, query that data interactively, and view query output in different formats. To access the CLI, first launch the influxd database process and then launch influx in your terminal. Once you’ve connected to an InfluxDB node, you’ll see the following output:
$influx
Connected to
[[http://localhost:8086]{.underline}](http://localhost:8086) version
1.7x
InfluxDB shell version 1.7.x
Note that the version of InfluxDB and CLI must be identical.
Creating a Database in InfluxDB
A fresh install of InfluxDB has no databases (apart from the system _internal). You can create a database with the CREATE DATABASE <db-name> InfluxQL statement, where <db-name> is the name of the database you wish to create. Let’s create a database called mydb.
> CREATE DATABASE mydb
To see if the database was created, use the following statement:
> SHOW DATABASES
name: databases
Name
----
_internal
mydb
Now, it is time to populate the mydb database.
Writing and Querying the Database
InfluxDB is populated with points from popular clients via HTTP /write Endpoint POST or via the CLI. Datapoints can be inserted individually or in batches.
Points consist of a timestamp, a measurement (“cpu_load”, for example), at least one key-value field (the measured value itself, e.g. “value=0.64”, or “temperature=21.2”), and zero to many key-value tags containing any metadata about the value (e.g. “host=server01”, “region=EMEA”, “dc=Frankfurt”).
Conceptually, you can think of a measurement as an SQL table, where the primary index is always time. Tags and fields are effectively columns in the table. Tags are indexed, and fields are not.
Points are written to InfluxDB using line protocol:
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
To insert a single time series datapoint with the measurement name of cpu and tags host and region, with the measured value of 0.64 into InfluxDB using the CLI, enter INSERT followed by a point in line protocol format:
> INSERT cpu,host=serverA,region=us_west value=0.64
Now query for the data written:
> SELECT “host”, “region”, “value” FROM “cpu”
Name: cpu
---------
Time host region value
2015-10-21T19:28:07.5806643472 serverA us_west 0.64
Great! You successfully installed InfluxDB and can write and query the data.
Next step is to collect data via Telegraf and send it to InfluxDB.
Data Collection with Telegraf
Telegraf is a plugin-driven server agent for collecting and reporting metrics. Telegraf has plugins to pull metrics from third-party APIs, or to listen for metrics via StatsD and Kafka consumer services. It also has output plugins to send metrics to a variety of datastores.
Install Telegraf from InfluxData download page: https://portal.influxdata.com/downloads/
Before starting the Telegraf server, you need to edit and/or create an initial configuration that specifies your desired inputs (where the metrics come from) and outputs (where the metrics go). Telegraf can collect data from the system it is running on. That is just what is needed to start getting familiar with Telegraf.
The example below shows how to create a configuration file called telegraf.conf with two inputs:
- One input reads metrics about the system’s cpu usage (cpu).
- Another input reads metrics about the system’s memory usage (mem).
InfluxDB is defined as the desired output.
telegraf -sample-config -input-filter cpu:mem -output-filter influxdb > telegraf.conf
Start the Telegraf service and direct it to the relevant configuration file:
MacOS Homebrew
telegraf -config telegraf.conf
Linux (sysvinit and upstart Installations)
Sudo services telegraf start
Linux (systemd Installations)
Systemctl start telegraf
You will see the following output (Note: this output below runs on a Mac):
NetOps-MacBook-Air:~ Admin$ telegraf --config telegraf.conf
2019-01-12T18:49:48Z I! Starting Telegraf 1.8.3
2019-01-12T18:49:48Z I! Loaded inputs: inputs.cpu inputs.mem
2019-01-12T18:49:48Z I! Loaded aggregators:
2019-01-12T18:49:48Z I! Loaded processors:
2019-01-12T18:49:48Z I! Loaded outputs: influxdb
2019-01-12T18:49:48Z I! Tags enabled: host=NetOps-MacBook-Air.local
2019-01-12T18:49:48Z I! Agent Config: Interval:10s, Quiet:false, Hostname:”NetOps-MacBook-Air.local”, Flush Internal:10s
Once Telegraf is up and running, it will start collecting data and writing it to the desired output.
Returning to our sample configuration, we show what the cpu and mem data look like in InfluxDB below. Note that we used the default input and output configuration settings to get this data.
List all measurements in the Telegraf database:
> SHOW MEASUREMENTS
Name: measurements
------------------
Name
Cpu
mem
List all field keys by measurement:
> SHOW FIELD KEYS
name: cpu
---------
fieldKey fieldType
usage_guest float
usage_guest_nice float
usage_idle float
usage_iowait float
usage_irq float
usage_nice float
usage_softirq float
usage_steal float
usage_system float
usage_user float
name: mem
---------
fieldKey fieldType
active integer
available integer
available_percent float
buffered integer
cached integer
free integer
inactive integer
total integer
used integer
used_percent float
Select a sample of the data in the field usage_idle in the measurement cpu_usage_idle:
> SELECT usage_idle FROM cpu WHERE cpu = 'cpu-total' LIMIT 5
name: cpu
---------
time usage_idle
2016-01-16T00:03:00Z 97.56189047261816
2016-01-16T00:03:10Z 97.76305923519121
2016-01-16T00:03:20Z 97.32533433320835
2016-01-16T00:03:30Z 95.68857785553611
2016-01-16T00:03:40Z 98.63715928982245
That’s it! You now have the foundation for using Telegraf to collect and write metrics to your database.
Data visualization and graphing with Chronograf
Chronograf is the administrative interface and visualization engine for the TICK Stack. It is simple to use and includes templates and libraries to allow you to build dashboards of your data and to create alerting and automation rules.
The Chronograf builds are available on InfluxData’s Downloads page.
- Choose the download link for your operating system.
Note: If your download includes a TAR package, we recommend specifying a location for the underlying datastore, chronograf-v1.db, outside of the directory from which you start Chronograf. This allows you to preserve and reference your existing datastore, including configurations and dashboards, when you download future versions.
- Install Chronograf:
- MacOS: tar zxvf chronograf-1.6.2_darwin_amd64.tar.gz
- Ubuntu & Debian: sudo dpkg -i chronograf_1.6.2_amd64.deb
- RedHat and CentOS: sudo yum localinstall > chronograf-1.6.2.x86_64.rpm
- Start Chronograf:
- MacOS: tar zxvf chronograf-1.6.2_darwin_amd64.tar.gz
- Ubuntu & Debian: sudo dpkg -i chronograf_1.6.2_amd64.deb
- Connect Chronograf to your InfluxDB instance or InfluxDB Enterprise cluster:
- Point your web browser to > localhost:8888.
- Fill out the form with the following details:
- Connection String: Enter the hostname or IP of the machine that InfluxDB is running on, and be sure to include InfluxDB’s default port 8086.
- Connection Name: Enter a name for your connection string.
- Username and Password: These fields can remain blank unless you’ve enabled authorization in InfluxDB.
- Telegraf Database Name: Optionally, enter a name for your Telegraf database. The default name is Telegraf.
- Click Add Source.
Pre-canned Dashboards
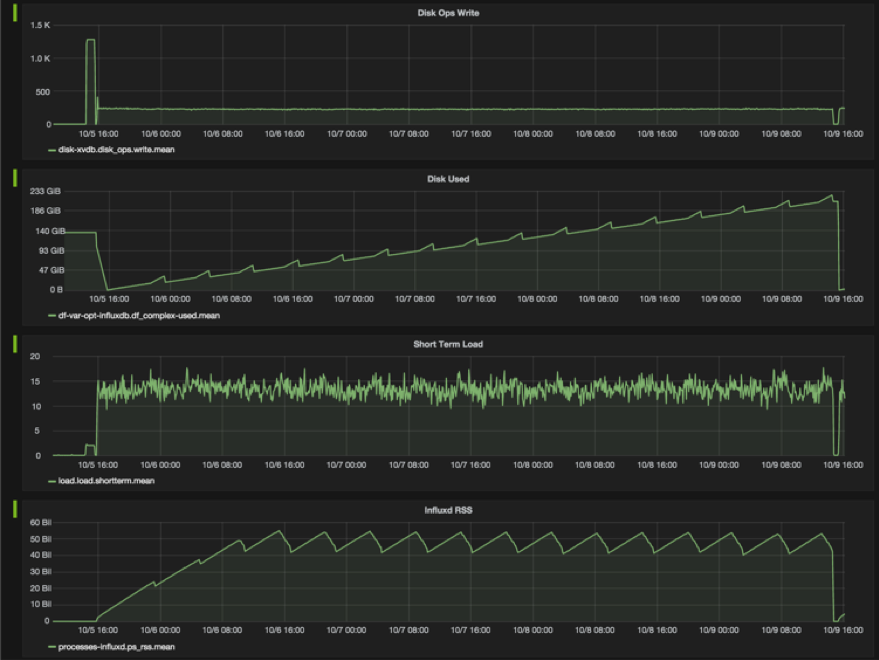
Pre-created dashboards are delivered with Chronograf, and you just have to enable the respective desired Telegraf plugins. In our example, we already enabled the cpu and mem plugins at the config file creation. Let’s take a look (Note: this example runs on a Mac):
Select the Dashboard icon in the navigation bar on the left, and then select “System”:
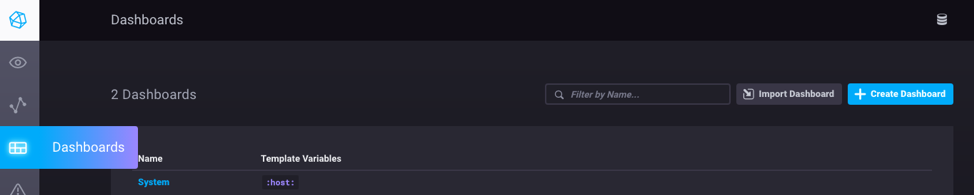
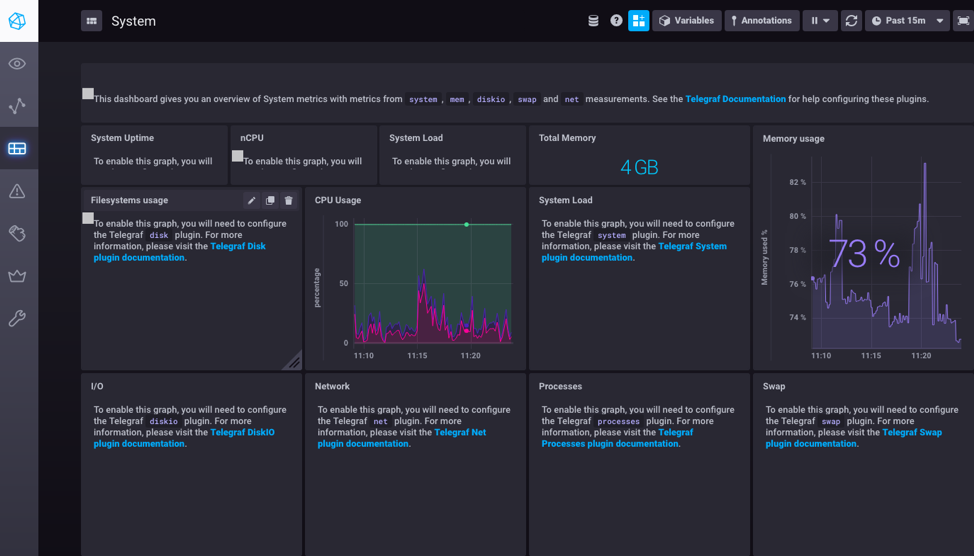
Voilà!
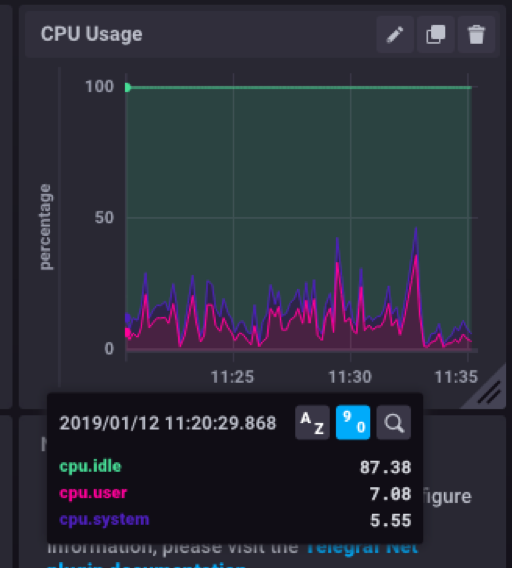
Taking a closer look at cpu measurement, you can see that it shows three measured fields (cpu.idle, cpu.user and cpu.system). You can filter each and move the measurement line to show exact values and timestamp.
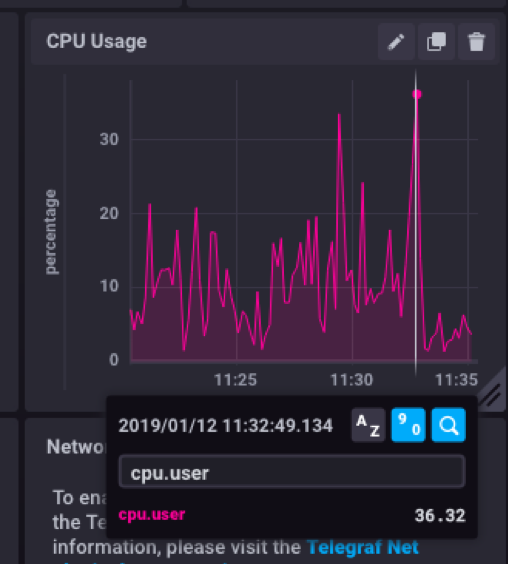
Cpu.user metric filtered:
The selected "System" App option for the example is just one of many pre-created dashboards available in Chronograf. See the list below:
Now that you are set to start exploring the world of time series data, what is next? Learning from others experience is always a good idea. Get more insights from case studies in various industry segments: telecom and service providers, e-commerce, financial markets, IoT, research, manufacturing, telemetry, and of course, the horizontal case of DevOps and NetOps in any organization, and see how time series monitoring generated positive results in the organizations, from better resource management via automation and prediction to five star customer experience.

{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}