2 Billion MySQL Records
Handling 2 billion MySQL records is actually possible. Sure, you'll need a monster server, and zero indexes or foreign keys during import, but it is possible.
Join the DZone community and get the full member experience.
Join For FreeYesterday Gary Gray, a friend of mine sent me the following screenshot. He's got a database table with 2 billion records he intends to use Magic on, and he wanted to show it to me, thinking I'd probably be like, "That's cool." Gary works for Dialtone in South Africa, and is used to handling a "monster amount of data". For the record, neither Gary nor I would want to encourage anyone to handle 2 billion records in MySQL, but as you can obviously, see it is possible.
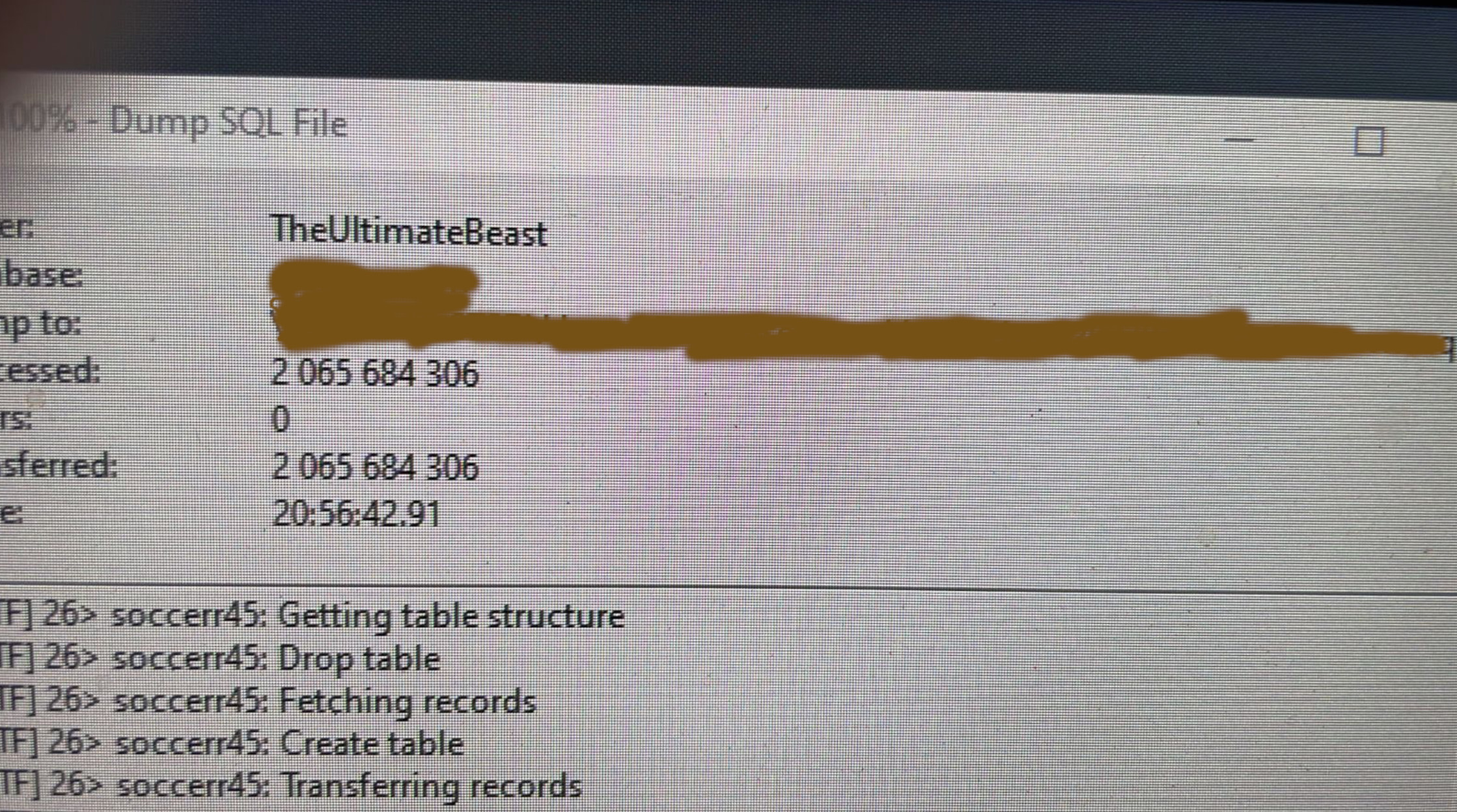
This of course is a legacy system. If it was started today, Gary would obviously use ScyllaDB, Cassandra, or something similar. Simply counting the records in the table above requires 5 minutes of execution in MySQL workbench. Obviously, such sizes are not for those faint at heart. Such a database also implies a lot of inserts. This makes it impossible to add indexes, resulting in every select query you do towards it having some sort of where clause in it that implies a full table scan. However, it is possible.
Another technique to use (if you can create database snapshots) is to import your huge database into a similar table structure to a "read-only database copy" without any indexes or foreign keys, and then add indexes and keys on your read-only copy after having imported your records. This allows you to do at least some selection into it afterward, resulting in query capacity into a read-only "copy" of your database. For the record, importing 2 billion records into MySQL took Gary 20 hours, even on a "monster machine" (as you can see literally was the name of his server in the above screenshot). I don't know how much time creating indexes would require, but I would assume something similar being 20+ hours for each index.
Once you have indexes on your read-only copy, you can actually do some basic CRUD read on it, with "where" statements resulting in filtering, and maybe even do some basic paging and sorting: which, of course, was Gary's point. Then the idea is to generate a Hyperlambda CRUD API, providing him with a backend allowing him to at least extract some meaningful data from it by adding filtering conditions, exposing these again to an automatically generated frontend.
For the record, handling 2 billion database records in MySQL is (probably) madness, but sometimes you have no choice, having inherited some legacy project that slowly built up over time. At the very least, the above provides you with a method to do some basic handling of your data. Interestingly, Magic allowed Gary to extract his data just as rapidly as he could with MySQL Workbench once he was done, which I think is pretty cool. So, yeah:
That's cool, Gary. ;)
Opinions expressed by DZone contributors are their own.
Comments