A Handbook to Implement Fuzzy Search in PostgreSQL
How to use PostgreSQL fuzzy search methods like trigrams, Levenshtein matching, phonetic matching, and pattern ops for LIKE and Regex queries.
Join the DZone community and get the full member experience.
Join For FreeJust like how software engineering has become polyglot, database systems such as PostgreSQL have increasingly become multi-model,
- Using PostgreSQL JSON as a data type.
- Key-Value store type in PostgreSQL.
- Working with geospatial data in PostgreSQL.
And a lot more. In this article, we are going to focus on how to implement fuzzy search in PostgreSQL.
Introduction to the PostgreSQL varlena Data Type
Regardless of whether we choose char, varchar or text , the underlying structure PostgreSQL uses is varlena. Whenever we attempt to design our schema, it is important to understand how the database interprets it. Below is an excerpt from the docs,
Note: There is no performance difference among these three types, apart from increased storage space when using the blank-padded type and a few extra CPU cycles to check the length when storing into a length-constrained column. While
character(it has performance advantages in some other database systems, PostgreSQL has no such advantage. In fact,n)character(it is usually the slowest of the three because of its additional storage costs. In most situationsn)textorcharacter varyingshould be used instead.
The text datatype will be the main focus of this article.
Selecting a Data Set for Our Learning
For this article, we are going to select a storm events dataset from the NOAA website. To simplify, we will not include all the columns that come with the original dataset. Below is the modified database schema for our dataset.

The corresponding table can be created using the following create table statement.
CREATE TABLE storm_events (
event_id integer,
event_type text,
damage_property text,
damage_crops text,
event_source text,
flood_cause text,
episode_narrative text,
event_narrative text
)We can import the CSV using the below command.
COPY storm_events FROM '/path/to/csv' DELIMITER ',' CSV HEADER; Simple Search Using the BTree Index
The simplest of queries you can run on a text column is the equality operator. Let's run a query where our event type is a Winter Storm.
SELECT
event_narrative
FROM
storm_events
WHERE
event_type = 'Winter Storm'
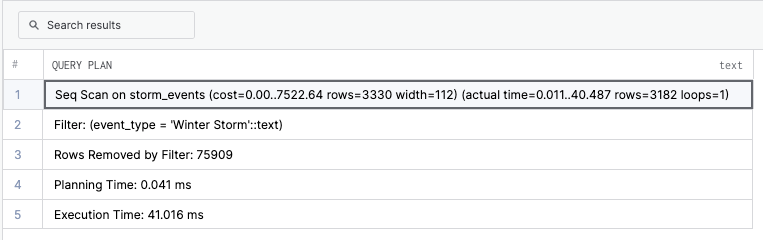
The plan would be to search through all of the rows in the absence of an index. For more on query plans, here is an in-depth article on that topic.
Creating the Index
To speed up our query (it takes 40ms now because of the lesser number of rows, but that will significantly change if the text is bigger and with an increase in the number of rows. 40ms is also considered very slow in relational DBS as the number of queries will be in the thousands and can significantly slow down the server); we can create a simple B-Tree index.
CREATE INDEX ON storm_events USING BTREE(event_type)We also choose to create the index concurrently if there are a large number of rows and if it is a system running in production.
Running Simple Queries
After creating the index, we can observe the speed improvement is significant.

The B-Tree index is one of the simplest yet commonly used indexes in the PostgreSQL world. But when it comes to text, it cannot handle searches. Consider the below query where we search for events where it is some storm, i.e., Winter Storm or Ice Storm, etc.,
EXPLAIN ANALYZE SELECT
event_type
FROM
storm_events
WHERE
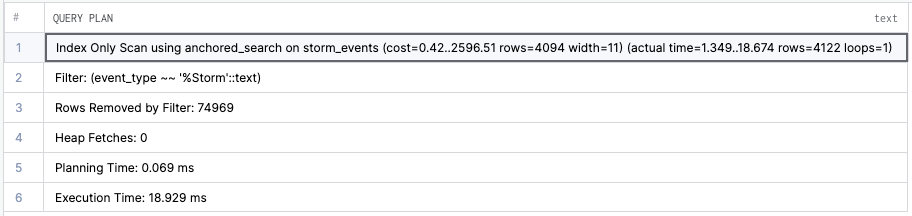
event_type LIKE '%Storm'The BTree index cannot handle such queries, and the planner will resort to a sequential scan.

Pattern Search
B-Tree can still handle variations of the searches if we create indexes using pattern_ops strategy.
CREATE INDEX anchored_search ON storm_events (event_type text_pattern_ops)The like query we used before using the left anchored search LIKE '%Storm' can now use the index.
Regex Search
The pattern_ops can be used for even regular expressions. Consider the query below,
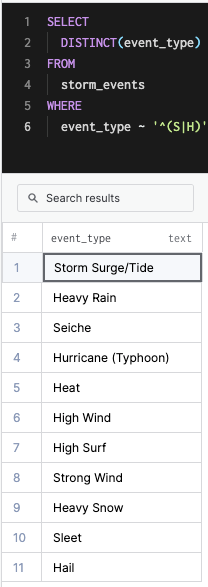
SELECT
DISTINCT(event_type)
FROM
storm_events
WHERE
event_type ~ '^(S|H)'This queries the event types starting with S or H.
Note: The Distinct is used only to give an idea of the results.
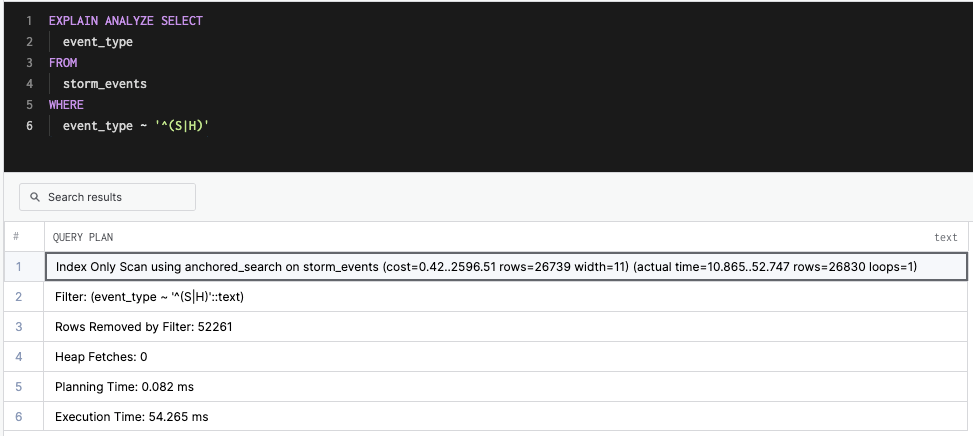
Without the anchored search index we created above, the above query will use a sequential scan. Now it will just use the index.
Limitations of B-Tree Pattern Ops
Even a full-text search will try to use the index, but it will be significantly slower. Consider the below query,
SELECT
event_type
FROM
storm_events
WHERE
event_type ILIKE '%winter%'We are doing an ILIKE since we do not know the cases, and it can even be a mixed case. Also, the word winter can exist anywhere in the string. If we run this, then the query will attempt to use the index.
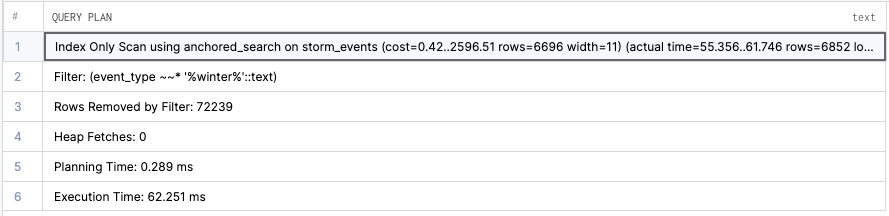
It is about 3.4x slower than our previous anchored searches (i.e., prefix or suffix searches).
One could argue that this is better than a sequential search,

But there is a limitation to this other than just speed. Let's try creating a pattern ops index on a much larger column like episode_narrative.
CREATE INDEX anchored_search_full ON storm_events (episode_narrative text_pattern_ops)This will result in an error,

The B-Tree index has an inherent size limitation(for good reasons) that prevents us from creating indexes for such large text columns. Let's move on to an interesting real-world use case of fuzzy search.
Fuzzy Search in PostgreSQL
The BTree index can only search smaller strings with either direct match or prefix/suffix match with slightly better performance. But in the real world, users often misspell words, and it gets pretty hard to search for them. This is where the fuzzy search capabilities of PostgreSQL come in. They can search strings with similar words and do not have the size limitations of BTree indexes.
Word Similarity Using Trigrams
Without a trigram index, it is practically impossible to search the possibilities unless we manually search through the possibilities. So let's see how we can create a trigram index.
CREATE EXTENSION pg_trgm;Once this extension is enabled, we can do fuzzy searches like below.

The SIMILARITY function returns what is called a score. We can adjust this score according to the matches we need. The default score is 0.3 And if we are not worried about the score, then we can use the below shorthand.
SELECT * FROM storm_events WHERE event_type % 'Drot'Which is the same as the above query. The documentation for this is pretty extensive, and the extension has a lot of other neat functions. We will see how to speed up such queries using an index later in this section.
Levenshtein Matching
The Levenshtein distance is the distance between two words, i.e., the minimum number of single-character edits required for both the strings/words to match. To use this functionality, we need to enable another extension called fuzzystrmatch.
CREATE EXTENSION fuzzystrmatch; Let's match all of the even types which have a Levenshtein distance of less than 4 from the same string drot.
SELECT * FROM storm_events WHERE levenshtein(event_type, 'Drot') < 4
Notice that we also get the results pertaining to the event type Heat.
Phonetic Match
The fuzzystrmatch extension has another cool feature where we can search for text which does not have similar spelling but sounds the same.
SELECT DISTINCT(event_type) FROM storm_events WHERE DIFFERENCE(event_type, 'he') > 2This will give us all events sounding like he.

Indexing for Faster Speed
There are specialized indexes that we can use to speed up our trigram queries.
CREATE INDEX trgm_idx on storm_events using gin(event_type gin_trgm_ops);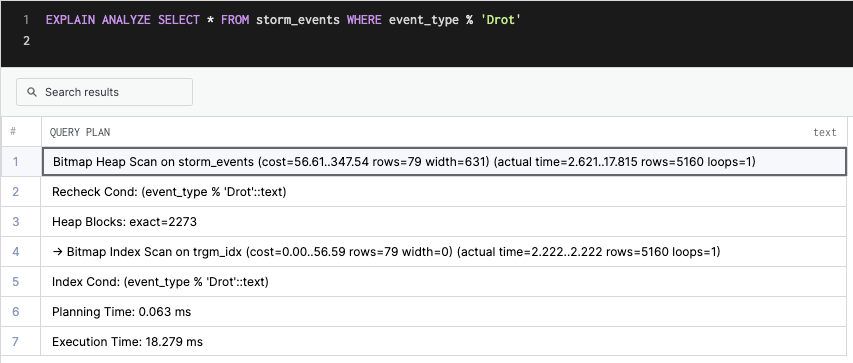
We can see a significant speedup. However, the query takes slightly longer since there are a lot of rows returned (5160).
Postgres Fuzzy Search Tradeoffs
PostgreSQL has a lot of advanced extensions and indexes to speed up the same. But one should keep in mind that these have their own limitations in terms of speed and might not work with languages other than English/multi-byte encoding, such as UTF-8. However, these fill the critical gap where the functionalities mentioned are necessary, but we cannot go for a full-fledged search solution such as Solr/Elasticsearch.
Closing Thoughts
Let's summarize what we have learned thus far:
- Direct string match.
- Pattern ops for
LIKEandRegexqueries. - Trigram fuzzy search.
- Levenshtein Matching.
- Phonetic Match.
There are a lot more capabilities with regards to search that we haven't seen in this article, such as a full-text search for text, ts_vector and jsonb data types which will be explored in an upcoming article.
Published at DZone with permission of Everett Berry. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments