A Robust Distributed Payment Network With Enchanted Audit Functionality - Part 1: Concepts
In this post, I'll review CQRS, event sourcing, graph database concepts necessary to build a distributed robust payment network system with enchanted audit functionality.
Join the DZone community and get the full member experience.
Join For FreeWe would like to build a simple distributed robust Qiwi-like payment network system with enchanted audit and monitoring functionality. Specifically, we would like to allow an external agency to trace money transfers between "related" accounts and users. Also, the agency should be able to restore the whole transaction history of every account.
The post is organized as follows. First, I elaborate on the functional requirements for our system. Next, I briefly discuss the Domain-Driven Design methodology. Then I define and discuss the CQRS and Event Sourcing concepts. Finally, I discuss how graph databases can efficiently detect cycles in directed graphs.
This system is actually implemented with Spring Boot, Axon, Neo4j in Part 2.
Functional Requirements
For simplicity, we assume that all users who participate in these scenarios are authorized:
- Users should be able to create their accounts, where money is stored, but no more than 1 per user (for simplicity).
- Users should be able to deposit money on their accounts and transfer money between accounts.
- The system should be failure-tolerant. If a component fails during a transaction, the system should be able to roll back the failed transaction. Also, the system should continue to operate if some of its parts are down. To make this work, the accounts should be stored in a separate database. Every service should have multiple instances running simultaneously. Money is transferred by a separate service that stores every transaction in still another database.
- The system should be scalable. As there are more and more accounts and more and more transactions, the system should be able to easily handle and load-balance more and more instances of the services.
- The system needs to be upgradable as new software technologies come out. This means the parts of the system can be upgraded separately.
- All actions to modify money accounts are stored in the transfer service database; it should be possible to restore the current state of every money account by "summing up" the action records.
- Every money account can be explicitly blocked by the external authority. No transfer is possible from or to a blocked account.
- Money accounts can be "related" - the accounts belong to relatives, long-term friends, etc.
- There should be an efficient way to detect a situation when money is transferred between "related" accounts.
Let's see how to attack these requirements.
Solution
1. Domain Model
We follow the methodology of domain-driven design. For this, we need to partition the domain model of our system into domains and specify how the domains interact with each other. Our simplified payment network has a simple domain model:
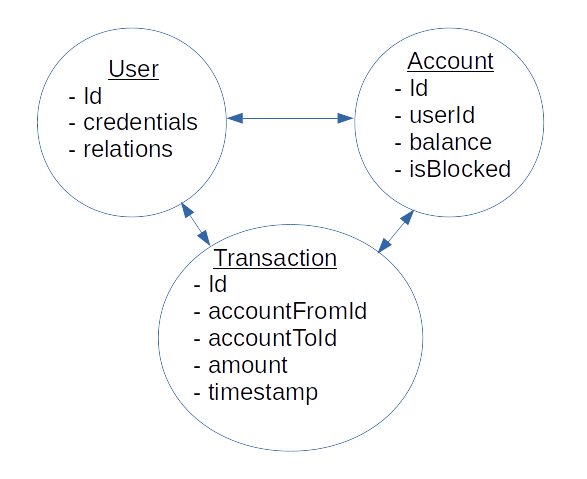 Fig 1. The domain model of our simplified payment network.
Fig 1. The domain model of our simplified payment network.
It is pretty obvious how to partition these domains and how they interact with each other. To use this domain partition in a software system, we need to recall the Command Query Responsibility Segregation (CQRS) and the Event Sourcing patterns.
2. Command Query Responsibility Segregation and Event Sourcing Patterns
According to the Axon website, the CQRS architecture pattern splits processing operations (command side) and answering questions (query side). This kind of segregation gives the following benefits:
- Every component has a single purpose (either a command or a query).
- We can separately deploy the command and the query sides.
- We can persist data in different ways.
Let's elaborate on what these terms are.
The Command model (СM or Write Model) handles the expressions of intent (the command). Upon receiving the command the model decides if the model's state should be changed, along with side effects (if necessary).
The Query model (QM) (“Projection” or “View Model” or “Read Model”) deals with requests for information and doesn't change any state, doesn't decide to make such changes. The query model only stores the current state of the system. To fulfill this task, the query model can have materialized views, NoSQL databases, etc. The QM does all the CRUD operations on these data sources.
The Command and Query models are synchronized by means of events (Fig 3). Events are objects that describe something that has occurred in the application. The Command model publishes an event upon handling a command. Then the Query model handles the event and updates its views, databases, etc. The Command model can update its state upon receiving its own event.

Another pattern we need in this work is the Event Sourcing pattern. The pattern stores data so that all the past changes are kept, instead of just the current state. The current state (or Materialized state) is reconstructed based upon a full history of events, where each event is a change in our application Fig 4 A. The events are stored in the event store. The event store is a single source of truth in our application. It works great as an audit log.
Typically the CM in CQRS is not stored other than by a sequence of events. The QM is constantly updated to contain a certain representation of the current system state; the representation is based on these same events.

Instead of reconstructing the entire CM, we separate the CM into an Aggregate. The Aggregate is the part of CM that needs to be strongly consistent and is tied to the Domain Model. To reload the Aggregate state, we need to reload all the events. To reduce the load, we take snapshots after a certain amount of events; the snapshot represents the correct state of the aggregate at that time. Next time we replay the events after that snapshot Fig 4 B.
Let's summarize what we got so far. The Read Model (or Query Model ) contains the current state of the system. The Write Model (or Command Model) is basically the Aggregate plus the Event Store; the model contains the current state and all the previous events of the system. Let's see how these patterns work in our system.
3. CQRS and ES in Our System
Our domain model prescribes 3 microservices in our system: the User, Account, and Transaction. However, to simplify our presentation and to reduce the number of "moving parts", we don't treat the User domain separately from the Account domain (Fig 5). Indeed, there is a one-to-one correspondence between the User and his/her Account. Also, the only User domain field we need to detect cycles is the relations one; we accommodate this field into the Account read model.
Notice that in addition to the domain services, there is an Orchestrator - a special service that coordinates scenarios that involve other services. The Orchestrator also interacts with the command, event, query buses.

As it should be in a CQRS system, our Account and Transaction aggregates accept commands and issue events; the Account and Transaction presentation layers, along with the Orchestrator, issue commands. The Orchestrator and the read models also accept events.
Let's see how these pieces of software work dynamically. For a command scenario, we have:
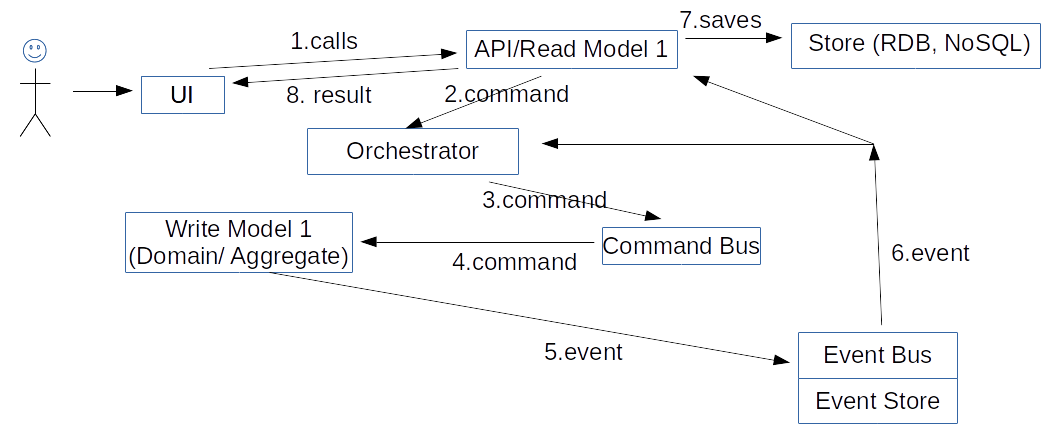
The user calls the Read Model 1, the model issues a command to the Orchestrator, the Orchestrator issues another command to the Aggregate (Write Model 1). The Aggregate issues an event to change its own state and to update the Read Model 1. Also, this event is handled by the Orchestrator; the Orchestrator issues still another command, etc.
A query scenario works like this:
 The user calls the Read Model 1 to get information (query). The Query is handled in the Query Handler. Then the result is returned to the user by the Read Model 1.
The user calls the Read Model 1 to get information (query). The Query is handled in the Query Handler. Then the result is returned to the user by the Read Model 1.
By and large, this is how CQRS and ES patterns work in our system. Let's see how to approach the last functional requirement: to efficiently detect cycles.
4. Graph Databases and Cycle Detection Algorithm
According to the Neo4j website:
A graph database stores nodes and relationships instead of tables, or documents. Data is stored just like you might sketch ideas on a whiteboard. Your data is stored without restricting it to a pre-defined model, allowing a very flexible way of thinking about and using it.
With this kind of data presentation, cycles can be detected in O(|V|+|E|) time via a two-colored Depth First Search algorithm (see, for example, this post or algorithm textbooks), where |V| is the number of vertexes and |E| is the number of edges of the graph. In our case |V| is the number of accounts, |E| is the number of transactions and relations. This algorithm detects cycles far more efficiently than a usual JOIN-based search of a relational database.
Conclusions
In this post, I reviewed the concepts and architectural approaches needed to build a simplified Qiwi-like payment network for the network to be robust and upgradable. The concepts include CQRS, ES, a Graph database. Also, we briefly discussed how to detect cycles.
Hope to see you in Part 2, where I present a Spring Boot, Axon, Neo4j implementation of the ideas of this post.
Acknowledgment
I would like to thank my mentor Sergey Suchok for his help on this post.
Opinions expressed by DZone contributors are their own.
Comments