A VLDB 2022 Paper: The Technologies Behind OceanBase’s 707 Million tpmC in TPC-C Benchmark Test
This presentation introduces the architecture of OceanBase, a distributed database system, and how the TPC-C benchmark test was performed.
Join the DZone community and get the full member experience.
Join For FreeTransaction Processing Performance Council Benchmark C (TPC-C) benchmark test is by far the most credible and authoritative yardstick of the functionality and performance of online transaction processing databases in the database industry worldwide. On May 20, 2020, the TPC published the TPC-C benchmark test results of OceanBase — 707 million transactions per minute (tpmC), with the system costs per tpmC further reduced to RMB 3.98. That was the second TPC-C challenge taken by OceanBase after it hit 60.88 million tpmC on its debut in the benchmark test in October 2019.
At the 48th International Conference on Very Large Databases (VLDB 2022), a database summit that just ended this September, OceanBase Senior Database Researcher Xu Quanqing presented a paper titled “OceanBase: A 707 Million tpmC Distributed Relational Database System," which introduces the architecture of OceanBase, a distributed database system, and how the TPC-C benchmark test in 2020 was performed.
What’s so special about the TPC-C benchmark test that attracted OceanBase to set new world highs twice in a row in two years?
TPC-C Benchmark Test Scenario: The Best Test Range for Transactional Databases
The TPC-C benchmark test scenario is a highly abstract representation of a real-world production system, which is more complex.
Five types of transactions are designed in the test model:
- No more than 45% of new order transactions
- No less than 43% of payment transactions
- No less than 4% of order status transactions
- No less than 4% of delivery transactions
- No less than 4% of stock-level transactions
The top two types of transactions simulate order creation and payment transactions in the production system. No matter how simple it seems, this TPC-C model is a great abstraction of the actual online transaction processing and is applicable to various modern industries, such as e-commerce, banking, transportation, communications, and government and enterprise services.
In addition, the TPC has specified stringent rules for the test. Therefore, like the Double 11 Shopping Festival, the TPC-C benchmark test is also a great test range that provides an opportunity for OceanBase to try out and sharpen its products under challenging circumstances.
Requirements of the TPC-C Benchmark Test on Transaction Processing and Performance Jitter
Many database vendors run TPC-C datasets with general benchmarking tools such as BenchmarkSQL and OLTPBench and claim that their products are tested in strict compliance with the TPC-C specifications.
However, TPC does not recognize their test results, because the results are not audited by TPC-authorized auditors.
The TPC-C benchmark test undergoes a strict audit process. Before they can start the performance test, vendors have to pass the functionality verification that checks whether their databases meet requirements on atomicity, consistency, isolation, and durability (ACID) properties of transactions. In other words, databases failing the ACID verification do not qualify for the TPC-C benchmark test. For example, some vendors build “distributed” databases simply by stacking multiple standalone databases together. Such databases without the native distributed architecture, although each component database meets ACID requirements, are incapable of handling these key properties as a whole and therefore cannot participate in the official TPC-C benchmark test to produce convincing performance results.
Specifically, the TPC-C benchmark test puts high requirements on the following two aspects of a database system:
1. Transaction Processing Capability
As a benchmark test for online transaction processing (OLTP) systems, TPC-C requires that the database under test must be ACID compliant in terms of transactions. To pass the test, a database must be capable of serializable isolation, the strictest transaction isolation level, and withstand any single point of failure.
Obviously, those are the basic requirements for an OLTP database.
The TPC-C benchmark test also requires the database to process at least a certain quantity of distributed transactions; to be more specific, 10% of new order transactions and 15% of payment transactions in a distributed environment, which may be distributed across a maximum of 15 nodes.
ACID properties of transactions are tested separately:
- In the atomicity test, payment transactions are committed and rolled back to confirm whether the database supports transaction atomicity.
- In the consistency test, the database must ensure data consistency in the first four out of the 12 scenarios designed. Each scenario is essentially a large complex SQL transaction. For a distributed database, the key is to ensure global consistency of data at any given time.
- In the isolation test, the database must ensure that all transactions other than those of the stock-level type are isolated up to the highest serializable level, which needs to be verified in nine scenarios designed.
- In the durability test, the database must save the results of write transactions to the disk within a certain period of time, even in the worst possible circumstances, such as the permanent failure of a part of the storage medium.
It is extremely challenging for a distributed database to pass the ACID verification. The serializable isolation level in particular is hard to achieve. This is one of the reasons why few distributed databases can make it through the official TPC-C benchmark test.
2. Run For at Least 2 Hours With Jitters Less Than 2%
Continuous and stable database operation is required in the TPC-C benchmark test. To pass the test, a database must run with stable performance for at least 8 hours, excluding the ramp-up and ramp-down durations, and the cumulative performance variation must not exceed 2% through the measurement interval, which is not less than 2 hours. This requires a distributed system to be highly available and stable.
As a matter of fact, computer systems tend to experience significant performance jitters and may crush under an extreme workload which, however, is not allowed in a real-world production environment.
Therefore, the TPC-C specifications above are quite practical. Some may ask, is it possible for a database to generate a transient performance spike somehow and get a great score for high performance? This is a complete breach of TPC-C specifications as it does not guarantee the steady state of the database over a prolonged period of time, much less the 2%-limit on the cumulative performance jitters.
Technologies That Support the Performance of 707 Million tpmC With 1,500 Servers Running
A globally recognized test on OLTP systems, the TPC-C benchmark test has stringent requirements for the database systems under test. OceanBase, a distributed database system, is no exception. Most challenges confronting OceanBase in the test are about its “native” features, such as distributed transaction processing, data consistency, high availability, and linear scaling. From this perspective, the record high 707 million tpmC in turn proved that OceanBase deals with these challenges quite well.
The extraordinary performance essentially relies on the architectural and engineering choices and breakthroughs made by the OceanBase technical team. As mentioned above, the TPC-C benchmark test is a great test range for database performance enhancement. In preparation for the test, the team invested a huge amount of effort to optimize the transaction processing engine, storage engine, and SQL engine. Those optimizations are very adaptable to the highly abstract TPC-C benchmark test scenarios.
1. Strong Data Consistency Guaranteed by the Native Distributed Architecture
OceanBase uses the Paxos distributed consensus protocol, one of the fundamentals that empower the distributed architecture of OceanBase. Essentially, this protocol ensures that unreliable members in a system can also provide reliable services. The fault of a single node has no impact on the system operation as long as the majority of nodes are healthy.
Paxos Protocol Guarantees Strong Consistency Among Replicas and Zero Data Loss (RPO = 0)
OceanBase makes full use of the Paxos protocol and combines it with write-ahead logging (WAL). Every time new redo logs are written to the disk, the logs are synchronized, with strong data consistency, to the majority of replicas, including the leader and several followers in the same Paxos group. This mechanism brings two benefits:
- If any minority replicas in the Paxos group fail, the remaining healthy majority replicas ensure that the latest redo logs are available, thus guaranteeing a zero recovery point objective (RPO) that means no data loss.
- The failure of minority followers in the Paxos group does not affect the strong data consistency among the remaining majority replicas at all.
In addition, various built-in data verification mechanisms of OceanBase can automatically detect errors such as inter-replica data inconsistencies, network errors, silent data corruption, and table-index inconsistencies, to ensure data consistency across multiple replicas.
In a word, the Paxos protocol ensures strong data consistency across multiple replicas in OceanBase and zero data loss (RPO = 0) in case of failure. There is no need to worry about the performance of applications.
Automatic Load Balancing Ensures High Performance Based on Linear System Scaling
With system availability and data consistency guaranteed, the cluster of a distributed system can be scaled in and out as needed with the help of automatic load balancing to implement the performance that matches the cluster scale.
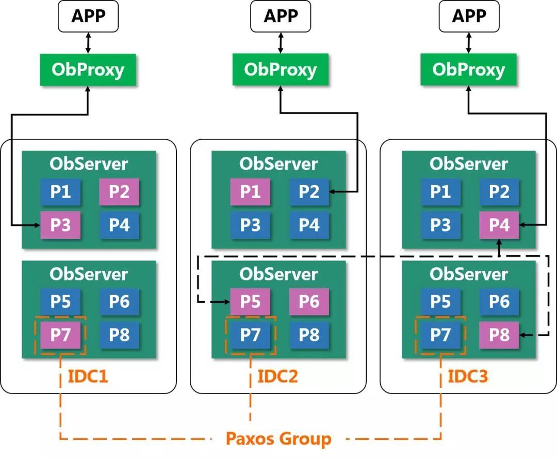
In OceanBase, a partition or subpartition (if tables are subpartitioned) is the basic unit for data distribution. A non-partitioned table itself is taken as a partition. The load balancing of OceanBase is related to partitions.
Each partition has at least three copies (or replicas) in the cluster. One of the replicas is the leader and the other two are followers. By default, data is read from and written to the leader. The default zone that hosts the leader is determined by the settings of the Primary Zone and Locality parameters of the table.
Since the leader location is internal OceanBase information that is transparent to the client, an OBProxy is provided to forward client requests. The OBProxy is a reverse proxy in OceanBase. It only routes SQL requests from the client to the zone where the leader is hosted. Unlike an HAProxy, the OBProxy does not and need not balance the load. However, as the OBProxy is stateless, users can deploy multiple OBProxies and add a load balancer to ensure load balancing and high availability of OBProxies.
2. Stability and Availability Guaranteed by a Native Distributed System
A big challenge proposed by the TPC-C benchmark test is that the performance curve must be smooth throughout the stress test, with no greater than 2% fluctuation. This is hard for a conventional database because it requires fine-grained control over all background tasks and no backlog of foreground requests due to resource overuse by a background task.
This challenge is even more severe for OceanBase because it uses a storage engine based on a log-structured merge tree (LSM tree) that requires periodic compactions. Data compaction is a highly weighted background task that consumes a lot of CPU and disk resources, and inherently causes an impact on foreground user queries and data writes. To address this issue, the OceanBase team has optimized the system to smooth out the performance impacts of background tasks.
Flexible Compaction Strategies Balance Read and Write Performance
The LSM tree-based storage engine first writes data to a MemTable in memory and then merges the data with that in an SSTable on disk to release the memory. This process is called data compaction. To improve the data write performance, an LSM tree-based storage system usually distributes SSTables on multiple layers. When the number or size of SSTables on a layer reaches the specified threshold, they are merged into an SSTable in the next layer. This hierarchical SSTable structure does ensure efficient data write but slows down the query performance significantly if too many SSTables exist. OceanBase also adopts such a structure but supports more flexible compaction strategies to keep a moderate number of SSTables and achieve balanced read and write performance.
Isolation Between Foreground and Background Resources Ensures Stable Read and Write Performance
To reduce the impacts of data compaction and other resource-consuming background tasks on user queries and data writes, OceanBase isolates the CPU, memory, disk, and network resources for foreground tasks from those for background tasks. Specifically, background tasks and user requests are processed by threads from different pools and thread pools are isolated based on their CPU affinity. The memory is divided into different spaces to cache foreground and background requests separately. The deadline algorithm is employed to control the disk input/output operations per second (IOPS) of background tasks. To optimize bandwidth usage, remote procedure calls (RPCs) of background tasks and those of user requests are forwarded to different queues, and the traffic of background RPCs is controlled.
Paxos Protocol and Multi-type Replicas Implement Service High Availability (RTO < 30S)
OceanBase ensures the high availability of system services based on the majority consensus built by the Paxos protocol.
As per the Paxos protocol, a leader can be elected when the majority of replicas reach a consensus. Minority replicas are not eligible to elect a leader.
In addition, if the leader fails, a new leader can be elected from the remaining followers to take over the service as long as the majority of them reach a consensus. The old leader cannot be elected as it is apparently not a member of the majority.
It is clear that the Paxos protocol plays a dominant role in maintaining high system availability:
- Technically, it guarantees that the system has only one leader at any given time, making split-brain impossible.
- As split-brain is no longer a concern, followers can automatically trigger the election of a new leader to replace the current leader that fails. The process is performed without user intervention.
In this way, the recovery time objective (RTO) is reduced to less than 30 seconds.
3. SQL Engine Optimization Improves Read and Write Performance
In a client-server model, an SQL statement goes through a long processing cycle after it is sent from the client. It is transmitted, optimized, and executed before the result is returned to the client. However, it is often that an SQL statement is executed only to update a single field. In this case, the execution step takes a very short period of time. A great deal of time is consumed in the interaction with the client, resulting in the waste of resources and time. So, how do we solve this problem? The answer is stored procedure.
Stored Procedures Reduce Network Overhead for Transactions
A stored procedure is a procedure-oriented programming language provided by the database. Users can use this language to encapsulate the logic of an application into a procedure, which is stored in the database and can be called at any time.
In this way, a task used to take several application-database interaction cycles can be completed in a single cycle, saving the time consumed in network transmission and queuing.
Assuming that the average network overhead for a transaction is 30%, it means that the CPU utilization is 30% for data sending, receiving, and parsing. This 30% CPU utilization, saved in the test achieving 707 million tpmC, can be translated into an amazing amount of system processing capacity.
Stored procedures also help reduce the transaction response time, shortening the critical section of the transaction lock in the database kernel. This finally increases the system CPU utilization and the overall throughput.
Stored procedures also play a significant role in cutting down the wait time of the application.
Cross-Platform Compiled Execution of Stored Procedures Improves Execution Efficiency
As an advanced procedure-oriented language, stored procedures must be translated into CPU-friendly machine code for execution. Compiled execution and interpreted execution are two typical methods used in this process. Generally speaking, compiled execution features full code optimization and more efficient execution compared with interpreted execution.
OceanBase implements a compiler based on the well-developed low-level virtual machine (LLVM) compiler framework. The compiler translates stored procedures into executable binary code in the way of just-in-time (JIT) compilation, improving the execution efficiency by several orders of magnitude.
During the compilation, the LLVM framework converts stored procedures into intermediate machine-independent code, making it possible to compile the stored procedures for execution across platforms. The built-in optimization process of the LLVM framework ensures that users get correct and efficient executable code on platforms built on different hardware.
Batch Processing of DML Statements Reduces Time Required for Generating the Execution Plan
Batch processing of DML statements is another crucial feature that makes OceanBase excel in the TPC-C benchmark test. It is also known as array binding in Oracle.
The execution process of an SQL statement in the database can be roughly divided into the plan generation and execution phases. Although SQL execution plans are cached, it is still time-consuming to hit an appropriate plan in the cache during the whole execution process. How do we solve this problem? The answer is array binding.
Array binding comes into play when the execution plans of a group of SQL statements are exactly the same, except for the execution parameters. In that case, a batch-processing procedure can be created based on specific syntax. As a result, only one plan is generated.
Array binding allows the database to find the plan, execute it, and then re-bind the parameters before the next execution. This is quite similar to the FOR loop in C language, where the loop repeatedly assigns the values instead of redefining the data structure.
To use array binding, users need to trigger it by specifying the FORALL keyword in the stored procedure. Array binding was used several times in the TPC-C benchmark test to improve the system processing capacity, and the results were great.
Prepared Statement and Cache of Execution Plans
The prepared statement protocol is a binary protocol that greatly reduces the request interaction costs of a system. In OceanBase, the prepared statements protocol is used not only in the application-database interactions but also by the stored procedure engine to call the SQL engine. After a stored procedure prepares an SQL statement, it obtains a unique ID. In each subsequent execution afterward, the system needs only to pass this ID and the parameters required. The system can then find the corresponding stored procedure or SQL plan from the cache and start the execution. Compared to SQL text-based interactions, this process saves a great deal of CPU overhead on statement parsing.
OceanBase caches the executable code of stored procedures and SQL execution plans so that executable objects can be retrieved from the cache by stored procedures and SQL statements with different parameters in dozens of microseconds. This significantly reduces latency and CPU consumption caused by recompilation.
4. Advanced Data Compression Technology Reduces Storage Costs
In this TPC-C benchmark test, OceanBase not only achieved a high performance of 707 million tpmC, but also further reduced the system costs per tpmC to RMB 3.98, making the product the most cost-effective choice for building a distributed database system.
In addition to the distributed architecture that allows middle-end hardware to cope with massive OLTP tasks, OceanBase has also adopted innovative data compression means to slash storage costs.
Data compression is key to reduce the space required for massive data storage. OceanBase implements a distributed storage engine featuring a high compression ratio. Thanks to the adaptive compression technologies, this LSM tree-based storage engine balances the system performance and compression ratio in a creative manner, which is impossible in a conventional database that stores data in fixed-size chunks. Moreover, data and logs are separately stored in the system to further reduce storage costs.
Variable and Fixed-Length Data Compression
To reduce storage costs, OceanBase uses compression algorithms that can achieve a high compression ratio and decompress data fast. In view of the structural characteristics of the LSM tree, OceanBase separates the storage spaces for data read and write, and supports row-level data updates. The updated data is stored in memory and then written to the disk in batches. Therefore, OceanBase achieves a write performance comparable to an in-memory database and stores data at costs not more than a disk-resident database. As the system does not suffer the performance bottleneck of random disk write and storage fragmentation as in a B-tree structure, it writes data faster than a conventional database that updates data blocks in real-time.
Storage Compression Based on Data Encoding
OceanBase adopts hybrid row-column storage where disk data blocks are organized by column. To be specific, it develops an encoding method that performs encoding compression on rows and columns by using dictionary, delta, and prefix encoding algorithms before compressing the data by using general algorithms. This further improves the compression ratio.
Low-Cost Storage Based on Data-Log Separation
The classic Paxos protocol requires a system to run with three or five replicas. As OceanBase separates user data from logs, the logs can be stored with, for example, three or five replicas, while the user data can be stored with two to four replicas. This data-log separation mechanism costs 20% to 40% less in user data storage while providing the same system availability.
For the OceanBase team, the score of 707 million tpmC in the TPC-C benchmark test not only testifies to the arduous work over the past 12 years but also sets the ground for us to make more and better technical innovations in the years ahead. As mentioned above, the TPC-C benchmark test is a test range. It encourages the team to keep upgrading OceanBase as a truly scalable distributed database system that is highly available and delivers strong performance.
Published at DZone with permission of Jamie Liu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments