Accidental Complexity Is Killing Your Testing Efforts and IT Budget
This article sets out different symptoms of accidental complexity, discussing how they derail your transformation initiatives.
Join the DZone community and get the full member experience.
Join For FreeYou’re working hard to transform your ways of working with a range of different goals. Common aims of digital transformations include:
- To become more Agile;
- To deliver faster through DevOps;
- To migrate all of your systems to the cloud;
- To enable regular change.
Whatever your desired outcome, there’s one common problem that most (everybody really) ignore. Yet, overlooking this problem ultimately means that the initiative will fail, become delayed, cost too much, or generally become severely hampered going forward.
This perennial (and perennially ignored) problem is “accidental complexity." This includes the accidental complexity already inherent in the way you make changes today or the accidental complexity that you’ll introduce in the future because of how you choose to make changes tomorrow.
“ While essential complexity is inherent and unavoidable, accidental complexity is caused by the chosen approach to solve the problem.”
Hugo Sereno Ferreira, "Incomplete by Design: Thoughts on Agile Architectures" (Agile Portugal: 2010).
Organizations rarely have the opportunity to start fresh when it comes to IT systems. Any Agile transformation — which is fundamentally a move to small, iterative, emergent change — is completed within brown-field architectures. These inevitably have accidental complexity built in.
This article sets out different symptoms of accidental complexity, discussing how they derail your transformation initiatives. My previous blog then offers inspiration for how you can solve this accidental complexity.
Too Many UI Tests
Because interfaces aren’t particularly well understood or documented, organizations are forced back to creating tests that focus on the user interface. This over-focus on UI testing is inefficient and costly while undermining our ability to test early and iteratively. It further tends to have low overall coverage, exposing systems to bugs.
Combinatorial Explosions — Subjective Coverage
Because the understanding of our system is at the e2e user flow level, we have a multiplying explosion of business logic:
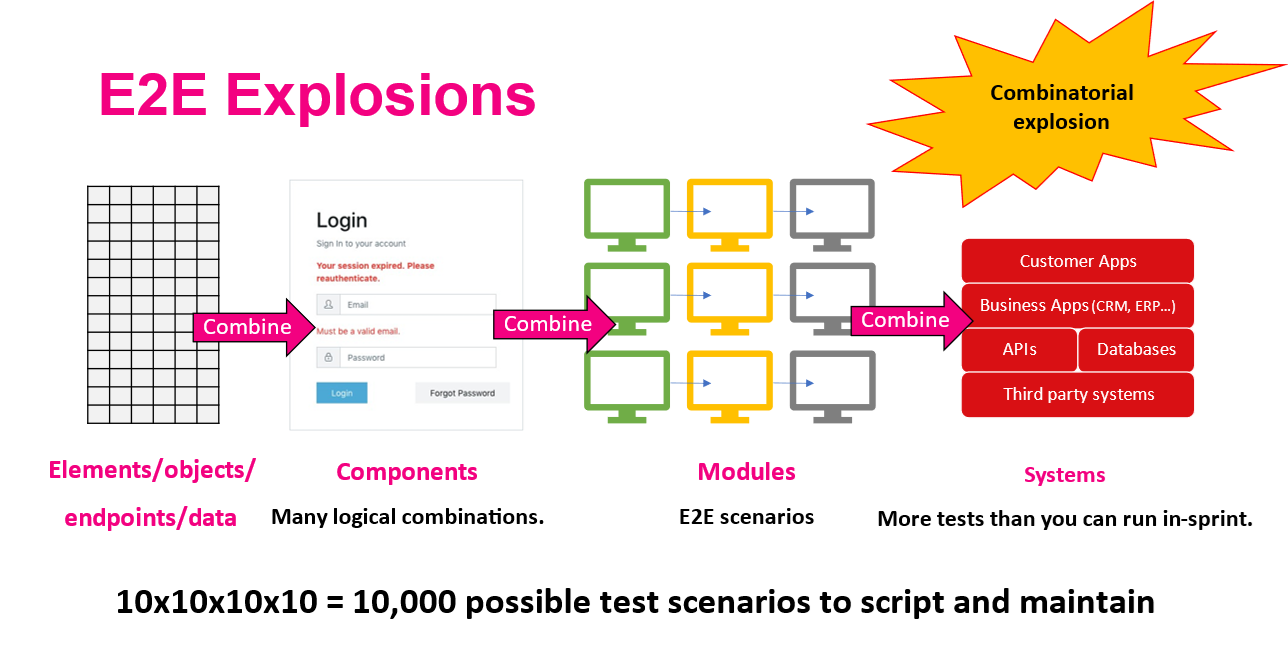
This “combinatorial explosion” is complex beyond human comprehension and is impossible to test against within a reasonable timeframe. In this scenario, the only way to achieve a valuable outcome in testing is to apply a risk-based approach. Yet, this is rarely recognized, or risk is based on an SME's opinion of what is “enough” testing.
Bloated Regression Test Pack With Lots of Duplication
This combinatorial explosion multiplies complexity in your testing but also in your ability to understand your systems. The problem simply becomes too big to understand. We are all taught to break problems down into smaller parts, but this seems to allude to many test approaches.
Huge Data Requirements
The large volume of tests needed to traverse the multiple systems in e2e journeys proliferates the demand for test data. Test data becomes embroiled in complexity, not just because the data required for the test isn’t well understood but also because of the systems of record for which these data items reside.
These systems are themselves under constant change, during which accidental complexity is playing its part. The systems are often poorly understood and poorly documented. Provisioning data for testing, in turn, isn’t the transactional request you thought it was. It risks massive complexity, massive labor, errors, and bottlenecks:
Huge Test Environment Requirements
The snowball of complexity continues to grow: Because I need e2e tests, I need e2e environments.
Testing and development, in turn, need numerous channels, middleware, and systems of record. Often, these will be legacy (mainframe) systems that you can’t build overnight. In fact, organizations have often lost the ability and knowledge to build these systems from the ground up. As a consequence, our only choice left is to use the finite number of fully integrated e2e environments available in the organization.
Yet, even one of these environments will cost millions in infrastructure alone and the same multiple times over in resources to maintain. And that’s not the only problem. Organizations have many teams making changes, and they all need to test e2e. Teams queue for environments, creating a huge bottleneck that drains the organization’s change budget.
Test Drift From the System Under Test
A separation between what is being tested and how the system actually works will inevitably occur if you don’t have effective means to refactor what you are testing in line with what is being tested. Very rarely will you see a team talk about how they refactor test assets because most don’t do it. This not only leads to test bloat but creates outdated and invalid tests and misalignment in what your test efforts cover.
Organizations Are Much More Than a Structure Chart
The problems discussed so far are much more systemic than testing. Accidental complexity additionally stems from organizations and their structures. Challenges include:
- Organizations are siloed, and so are IT change teams. Conway’s law tells us that these silos create an architecture where interfaces are not well understood or maintained. Teams don’t talk to each other unless they have to….
- IT change creates “layering” in the understanding of how systems work. As systems grow, they become increasingly complex, with more unknowns.
The three ways of DevOps talk to Flow, Feedback, and Experimentation/Learning. Flow talks about “Never allowing local optimization to create global degradation.” This should cause teams to rethink the way in which they approach change, but it rarely seems to [1].
This quote indicates the need for collaboration across teams. Such collaboration is blocked by the “pizza box-sized team,” who carry on working in a silo, chuck their work over the fence, and find problems during large end-to-end integration testing events. Whilst a team can work in a silo as much as they can, they inevitably need to integrate the system they are working on with the rest of the organization.
This choice of approach might have been taken as the path of least resistance to get started. It might even have been taken in the name of experimentation or a “start-up” initiative within a larger organization. Whatever the rationale, it likely did not consider the accidental complexity such an approach creates or contributes to within the wider organization.
You might see testing as the barometer of an organization’s maturity when making change. If systems are testable, change is understood and observable. If quality and risk are discussed, you have a healthy ecosystem. If all of this seems too hard, you will unfortunately continue down the increasing spiral of complexity.
Can't Change, Won't Change
“Culture eats strategy for breakfast.” — Peter Drucker
Whilst you will undoubtedly recognize many of the points raised in this article, the biggest challenge isn’t knowing how to change but rather wanting to change.
Many organizations work to a certain drumbeat. The innovators go off and get the latest tech, not yet realizing they are just building the same problems with a flashier tool. Then you have the laggards who are stuck in the way of working from yesteryear. They will say, “We did Agile before it was Agile,” and yearn to go back to a time when there was even less documentation and even less change or version control.
Each has some good practices, but both create more accidental complexity and optimize locally, not globally, across the organization. So, how will you face your organization's accidental complexity?
“Accidental complexity is when something can be scaled down or made less complex, not lose any value, and likely add value because it's been simplified.”
Kristi Pelzel, “Design Theory: Accidental and Essential Complexity” (Medium: 2022)
References
[1] Gene Kim, “The Three Ways: The Principles Underpinning DevOps” by Gene Kim (IT Revolution: 2012).
Published at DZone with permission of Rich Jordan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments