Active-Active Application Architectures With MongoDB (Part 1)
The first post in this two-part series describes the database capabilities required by modern multi-data center applications.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Determining the best database for a modern application to be deployed across multiple data centers requires careful evaluation to accommodate a variety of complex application requirements. The database will be responsible for processing reads and writes in multiple geographies, replicating changes among them, and providing the highest possible availability, consistency, and durability guarantees. But not all technology choices are equal. For example, one database technology might provide a higher guarantee of availability while providing lower data consistency and durability guarantees than another technology. The tradeoffs made by an individual database technology will affect the behavior of the application upon which it is built.
Unfortunately, there is limited understanding among many application architects as to the specific tradeoffs made by various modern databases. The popular belief appears to be that if an application must accept writes concurrently in multiple data centers, then it needs to use a multi-master database - where multiple masters are responsible for a single copy or partition of the data. This is a misconception and it is compounded by a limited understanding of the (potentially negative) implications this choice has on application behavior.
To provide some clarity on this topic, this post will begin by describing the database capabilities required by modern multi-data center applications. Part 2 of this series will describe the categories of database architectures used to realize these requirements and summarize the pros and cons of each. Finally, Part 2 will look at MongoDB specifically and describe how it fits into these categories. It will list some of the specific capabilities and design choices offered by MongoDB that make it suited for global application deployments.
Active-Active Requirements
When organizations consider deploying applications across multiple data centers (or cloud regions) they typically want to use an active-active architecture. At a high-level, this means deploying an application across multiple data centers where application servers in all data centers are simultaneously processing requests (Figure 1). This architecture aims to achieve a number of objectives:
- Serve a globally distributed audience by providing local processing (low latencies)
- Maintain always-on availability, even in the face of complete regional outages
- Provide the best utilization of platform resources by allowing server resources in multiple data centers to be used in parallel to process application requests.
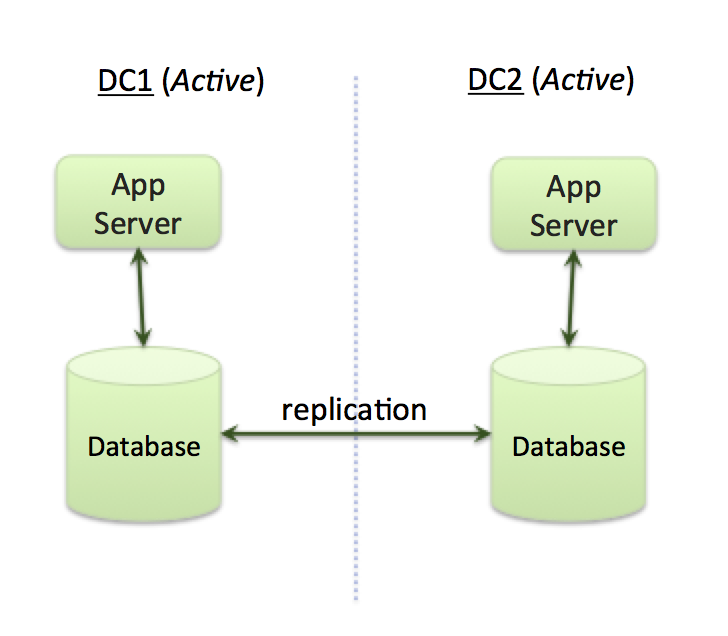
Figure 1 - Active-Active Application Architecture
An alternative to an active-active architecture is an active-disaster recovery (also known as active-passive) architecture consisting of a primary data center (region) and one or more disaster recovery (DR) regions (Figure 2). Under normal operating conditions, the primary data center processes requests and the DR center is idle. The DR site only starts processing requests (becomes active), if the primary data center fails. (Under normal situations, data is replicated from primary to DR sites, so that the the DR sites can take over if the primary data center fails).
The definition of an active-active architecture is not universally agreed upon. Often, it is also used to describe application architectures that are similar to the active-DR architecture described above, with the distinction being that the failover from primary to DR site is fast (typically a few seconds) and automatic (no human intervention required). In this interpretation, an active-active architecture implies that application downtime is minimal (near zero).
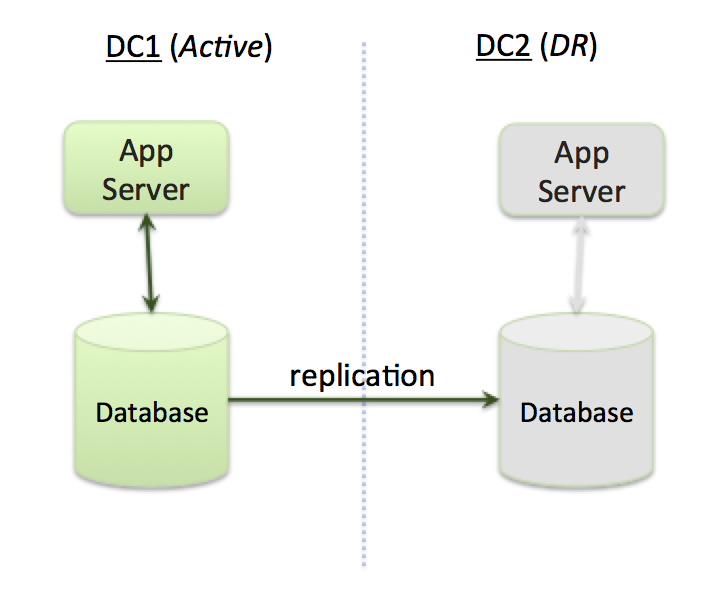
Figure 2 - Active-DR architecture
A common misconception is that an active-active application architecture requires a multi-master database. This is not only false, but using a multi-master database means relaxing requirements that most data owners hold dear: consistency and data durability. Consistency ensures that reads reflect the results of previous writes. Data durability ensures that committed writes will persist permanently: no data is lost due to the resolution of conflicting writes or node failures. Both these database requirements are essential for building applications that behave in the predictable and deterministic way users expect.
To address the multi-master misconception, let's start by looking at the various database architectures that could be used to achieve an active-active application, and the pros and cons of each. Once we have done this, we will drill into MongoDB's architecture and look at how it can be used to deploy an Active-Active application architecture.
Database Requirements for Active-Active Applications
When designing an active-active application architecture, the database tier must meet four architectural requirements (in addition to standard database functionality: powerful query language with rich secondary indexes, low latency access to data, native drivers, comprehensive operational tooling, etc.):
- Performance - low latency reads and writes. It typically means processing reads and writes on nodes in a data center local to the application.
- Data durability - Implemented by replicating writes to multiple nodes so that data persists when system failures occur.
- Consistency - Ensuring that readers see the results of previous writes, readers to various nodes in different regions get the same results, etc.
- Availability - The database must continue to operate when nodes, data centers, or network connections fail. In addition, the recovery from these failures should be as short as possible. A typical requirement is a few seconds.
Due to the laws of physics, e.g., the speed of light, it is not possible for any database to completely satisfy all these requirements at the same time, so the important consideration for any engineering team building an application is to understand the tradeoffs made by each database and selecting the one that provides for the application's most critical requirements.
Let's look at each of these requirements in more detail.
Performance
For performance reasons, it is necessary for application servers in a data center to be able to perform reads and writes to database nodes in the same data center, as most applications require millisecond (a few to tens) response times from databases. Communication among nodes across multiple data centers can make it difficult to achieve performance SLAs. If local reads and write are not possible, then the latency associated with sending queries to remote servers significantly impacts application response time. For example, customers in Australia would not expect to have a far worse user experience than customers in the eastern US where the e-commerce vendors primary data center is located. In addition, the lack of network bandwidth between data centers can also be a limiting factor.
Data Durability
Replication is a critical feature in a distributed database. The database must ensure that writes made to one node are replicated to the other nodes that maintain replicas of the same record, even if these nodes are in different physical locations. The replication speed and data durability guarantees provided will vary among databases, and are influenced by:
- The set of nodes that accept writes for a given record
- The situations when data loss can occur
- Whether conflicting writes (two different writes occurring to the same record in different data centers at about the same time) are allowed, and how they are resolved when they occur
Consistency
The consistency guarantees of a distributed database vary significantly. This variance depends upon a number of factors, including whether indexes are updated atomically with data, the replication mechanisms used, how much information individual nodes have about the status of corresponding records on other nodes, etc.
The weakest level of consistency offered by most distributed databases is eventual consistency. It simply guarantees that, eventually, if all writes are stopped, the value for a record across all nodes in the database will eventually coalesce to the same value. It provides few guarantees about whether an individual application process will read the results of its write, or if value read is the latest value for a record.
The strongest consistency guarantee that can be provided by distributed databases without severe impact to performance is causal consistency. As described by Wikipedia, causal consistency provides the following guarantees:
- Read Your Writes: this means that preceding write operations are indicated and reflected by the following read operations.
- Monotonic Reads: this implies that an up-to-date increasing set of write operations is guaranteed to be indicated by later read operations.
- Writes Follow Reads: this provides an assurance that write operations follow and come after reads by which they are influenced.
- Monotonic Writes: this guarantees that write operations must go after other writes that reasonably should precede them.
Most distributed databases will provide consistency guarantees between eventual and causal consistency. The closer to causal consistency the more an application will behave as users expect, e.g.,queries will return the values of previous writes, data won't appear to be lost, and data values will not change in non-deterministic ways.
Availability
The availability of a database describes how well the database survives the loss of a node, a data center, or network communication. The degree to which the database continues to process reads and writes in the event of different types of failures and the amount of time required to recover from failures will determine its availability. Some architectures will allow reads and writes to nodes isolated from the rest of the database cluster by a network partition, and thus provide a high level of availability. Also, different databases will vary in the amount of time it takes to detect and recover from failures, with some requiring manual operator intervention to restore a healthy database cluster.
We'll continue tomorrow with Part 2 of this series.
Published at DZone with permission of Jay Runkel. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments