Active Learning and Human-in-the-Loop for NLP Annotation and Model Improvement
A practical guide to using active learning and human-in-the-loop workflows for efficient NLP annotation, model training, and continuous improvement.
Join the DZone community and get the full member experience.
Join For FreeNatural language processing (NLP) models depend heavily on data, but obtaining high-quality labeled data at scale is one of the biggest hurdles. It quickly becomes clear that throwing more raw data at an NLP problem doesn't really help much - it’s the labeled data that really drives improvement. This is where active learning and a human-in-the-loop approach become invaluable. They help us prioritize which data to label, involve human expertise at critical points, and continuously improve models in production.
In this article, we’ll talk about what active learning is, how to implement a human-in-the-loop workflow for NLP annotation, and why this approach accelerates model improvement.
The Data Annotation Challenge in NLP
Collecting large volumes of text data is easier than ever now, but labelling that data for supervised learning remains difficult and expensive. Not all data points are equally useful for learning. Some examples are far more informative than others. In traditional machine learning, we would randomly label a big dataset and train a model, treating all those examples equally. In practice, that means a lot of time and money spent labeling data that might not even help the model much. Instead, we need to identify and label the right data, those data points that will most improve the model.
What Is Active Learning?
Active learning is a data-centric machine learning approach where the algorithm itself chooses which data points to learn from next. It’s often described as a form of semi-supervised learning that keeps a human in the loop. The key idea is to maximize the information gained from as few labeled examples as possible, instead of treating all data points equally.
In an active learning setup, we start with a small labeled dataset to train an initial model. This model is then used to evaluate or “score” a large pool of unlabeled data. Based on the model’s scores or confidence levels, the algorithm selects a subset of unlabeled examples that it finds most valuable or confusing. Those are sent to a human annotator for labeling. The newly labeled data is added to the training set, and the model is retrained. This cycle repeats iteratively. By doing this, the model focuses labeling effort on data that will most improve its performance, rather than expending effort on redundant or easy cases.
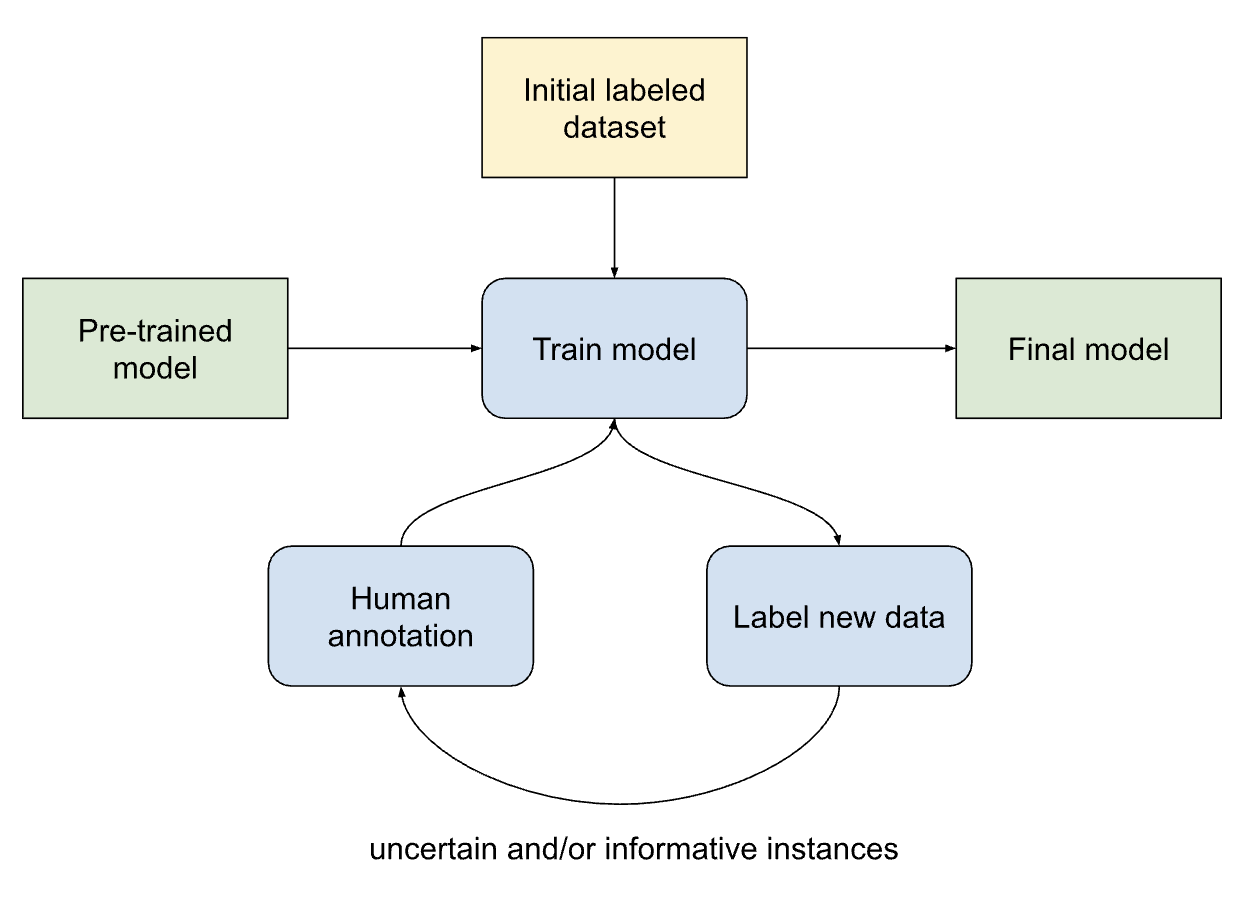
This approach yields a powerful win-win: the model improves faster with fewer labels, and humans spend their valuable time only on examples the model struggles with, rather than labeling everything under the sun. In fact, active learning is particularly useful when labeled data is limited or expensive to obtain, allowing the algorithm to focus on the most important data points first.
Human-in-the-Loop: Integrating Expert Feedback
When we refer to human-in-the-loop (HITL), we mean involving people directly in the model’s training and refinement process - not just during the initial setup. In active learning, this usually means a person steps in to label the data points that the model isn’t sure about. But more broadly, humans can provide feedback at various stages: verifying model predictions, correcting errors, and guiding the model’s evolution. This collaboration leverages the strengths of both the machine (speed, scalability) and the human (judgment, domain expertise).
Why involve humans in the loop? There are several compelling benefits:
- Efficiency and focus: Humans label only the critical examples identified by the model. This targeted labeling means we gain maximum information from each human annotation, avoiding wasted effort on redundant data.
- Improved accuracy with fewer labels: By always feeding the model the most informative new examples, we can achieve higher accuracy with far fewer labeled instances than random sampling would require. For example, a study on Named Entity Recognition showed that using active learning (uncertainty sampling) achieved an F1 score of 0.91 with the same labeling budget that yielded 0.85 F1 under random sampling. A more sophisticated strategy, like query-by-committee, reached about 0.92 F1 – a significant boost in model performance without extra data.
- Transparency and insight: Involving humans makes the model’s behavior more transparent. As we label model-flagged examples, we get to see what the model is unsure about. This provides insight into the model’s knowledge, doubts, and weaknesses. It’s a great way to understand failure modes: for instance, if the model keeps asking for help on financial texts in a sentiment analysis task, it hints that it struggles with that domain.
- Continuous improvement: A human-in-the-loop approach recognizes that models don’t have to be perfect from the start. Instead of building a flawless model in one go, we can launch something that’s good enough and improve it over time with feedback. This makes the initial training easier and allows the model to adapt to real-world data as it changes. It’s especially helpful in NLP systems where language keeps evolving and new cases keep popping up.
Active Learning Strategies for NLP
A core question in active learning is: how does the model decide which examples to ask humans to label? This choice is determined by the query strategy. There are a few key strategies that tend to work well in NLP tasks:
- Uncertainty sampling: This is perhaps the most common strategy. The model queries examples for which it has the least confidence in its predictions. For classification tasks, uncertainty can be measured by metrics like the lowest predicted probability (least confidence), the smallest margin between top predictions, or the highest entropy. If a text classification model outputs probabilities [0.4, 0.35, 0.25] for classes A, B, C, it’s pretty uncertain (entropy is high) because two classes are nearly tied. Such an example would be a prime candidate for human labeling. By focusing on uncertain cases, we address the model’s weakest areas first, leading to faster improvements.
- Diversity sampling: Another strategy is to select examples that are as diverse as possible, covering different regions of the data distribution. This helps ensure the model isn’t just learning from a narrow slice of data. Diversity sampling is especially useful if your data is imbalanced or broad. For instance, when building a language model from social media data, you would want a mix of topics and styles. By labeling diverse examples, we expose the model to a wide range of scenarios, improving its generalization.
- Random sampling: Random selection doesn’t guarantee the most informative samples, but it’s easy to implement and can be combined with other methods. On its own, pure random sampling is typically less efficient. However, a bit of randomness can be injected to avoid bias. For example, if uncertainty sampling keeps selecting very similar uncertain examples, adding some random samples ensures a broader coverage.
- Query by committee: This involves training an ensemble (committee) of models and having them “vote” on unlabeled instances. Cases where the models disagree the most are sent for labeling. The disagreement (measured by metrics like vote entropy or KL divergence) among model predictions is a strong signal of uncertainty from the model’s perspective. However, this can be more computationally expensive since it involves training multiple models, but it can pay off in catching nuances a single model might miss.
Using a combination of the above strategies is common in real-world pipelines.
Implementing an Active Learning Loop
Let’s outline how you could implement an active learning loop for an NLP task like text classification. We’ll use pseudocode to illustrate the process:
# Assume we have:
# model: an NLP model (e.g., a text classifier) with methods model.train() and model.predict_prob()
# X_train, y_train: initially small labeled dataset
# X_pool: large pool of unlabeled examples
for iteration in range(max_iterations):
# 1. Train or fine-tune the model on the current labeled dataset
model.train(X_train, y_train)
# 2. Use the model to compute prediction probabilities on the unlabeled pool
y_prob = model.predict_prob(X_pool) # returns a list of probability distributions
# 3. Compute an uncertainty score for each unlabeled example
uncertainties = [compute_uncertainty(probs) for probs in y_prob]
# 4. Select the top N most uncertain examples
query_indices = argsort(uncertainties)[-N:] # indices of N highest uncertainty samples
query_examples = [X_pool[i] for i in query_indices]
# (Optional) You could also ensure diversity among query_examples here
# 5. Send these examples for human labeling (human-in-the-loop)
new_labels = human_label(query_examples) # this is the human annotation step
# 6. Incorporate the newly labeled examples into the training set
X_train.extend(query_examples)
y_train.extend(new_labels)
# 7. Remove the labeled examples from the unlabeled pool
X_pool = np.delete(X_pool, query_indices)
# 8. Repeat: Next iteration will retrain the model with expanded training data
# until we run out of budget or the model’s performance meets our target.In practice, there are libraries and tools to support active learning. For example, modAL is a modular active learning framework for Python that can plug into scikit-learn or PyTorch models to help manage the selection strategies and looping. There are also annotation tools, like Prodigy and Label Studio, which support human-in-the-loop workflows.
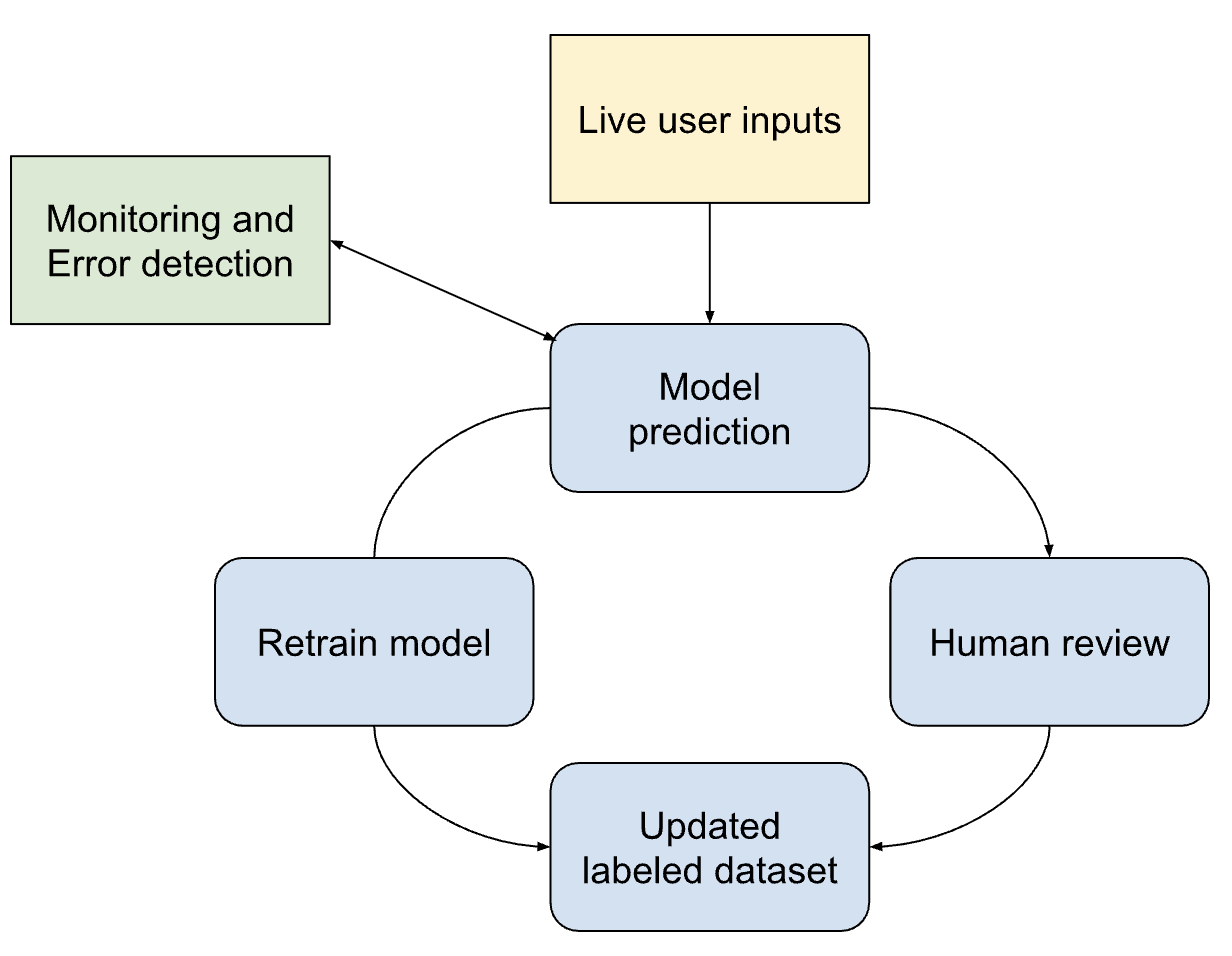
Beyond Training: HITL for Model Maintenance
Active learning is more than a training technique; it's a way to keep models improving even after deployment. In real-world NLP systems, data shifts happen constantly, like new slang or trending topics. As the model encounters unfamiliar examples, its performance can drop.
Hence, it's also critical for catching bias or systemic errors. If a moderation model mislabels certain slang as offensive, human reviewers can catch and fix that. Over time, this process keeps the model aligned with the real world.
Best Practices and Considerations
Implementing active learning in an NLP project does introduce some complexity. Here are a few tips and lessons learned from experience:
- Start with a solid model: Active learning works best when your model is already somewhat capable. Begin with a small, randomly labeled dataset or fine-tune a pre-trained model to give it a solid foundation.
- Pick the right uncertainty metric: For classification tasks, use entropy or margin-based methods. For sequence tasks, look at token-level confidence. The goal is to find a signal that truly reflects model confusion.
- Keep batches small and iterative: Label small groups of data, retrain, and check progress after each round. Avoid labeling too much at once, or you risk wasting effort on easy examples.
- Support human annotators: Good instructions matter. Show model feedback when possible to guide annotators, and watch for fatigue. Rotate hard and easy examples, or use multiple reviewers to keep quality high.
- Automation vs. human effort trade-off: Active learning is great when data is plentiful but labels are scarce. If your dataset is small and easy to label, traditional methods might be enough. The active learning loop adds overhead, so only use it when long-term gains outweigh setup costs.
Conclusion
Progress in NLP isn’t just about building larger models or collecting more data; it's about being selective, intentional, and adaptive. Active learning with a human in the loop gives us a practical way to stay sharp in changing environments. It lets machines ask for help when they need it, and keeps humans in the driver’s seat when it matters most.
Opinions expressed by DZone contributors are their own.
Comments