Unlocking Hidden Value in Dirty Data: A Practical NLP Pattern for Legacy Records
Legacy systems are full of free-text fields where valuable business data goes to die. NLP pipelines turn messy maintenance logs into structured, actionable insights.
Join the DZone community and get the full member experience.
Join For FreeIn the era of Digital Transformation (DX), we are often told that "data is the new oil." However, for many enterprises, that oil is crude, unrefined, and full of sludge.
Consider the automotive, manufacturing, or healthcare industries. For decades, technicians and operators have been typing notes into free-text fields. These millions of records contain critical information about asset health, maintenance history, and compliance. But because they are unstructured, full of typos, and riddled with domain-specific slang, they remain invisible to standard analytics tools.
How do you verify whether a specific safety inspection was actually performed when one record says "chk brk pads" and another says "replaced brake lining"?
Based on a recent case study involving millions of automotive maintenance records, this article outlines a robust, low-resource NLP pattern for structuring this “dirty data” without immediately resorting to expensive large language models (LLMs).
The Problem: The "Free-Text" Trap
When digitizing legacy workflows, we often encounter the "unstructured trap": data is collected, but it lacks a schema. In the context of maintenance records, the challenges are specific and difficult:
- Inconsistent character sets: Users might type "10mm" (half-width) in one record and "10 mm" (full-width) in another.
- Domain slang: Standard dictionaries don’t recognize that "O-Filter," "Elem," and "Element" all refer to an oil filter.
- Typos and noise:“Repaired” vs. "repairrd."
- Implicit context: A note saying “Brakes” might mean checked brakes, repaired brakes, or brakes need attention.
To automate verification (for example, "Was the 12-month safety inspection actually completed?"), we need a pipeline that can see through this noise.
The Architecture: A Similarity-Based Pipeline
The solution isn’t to build a chatbot, but a verification engine. We compare messy user input against a gold-standard definition of what the task should look like.
Here is the high-level architecture:
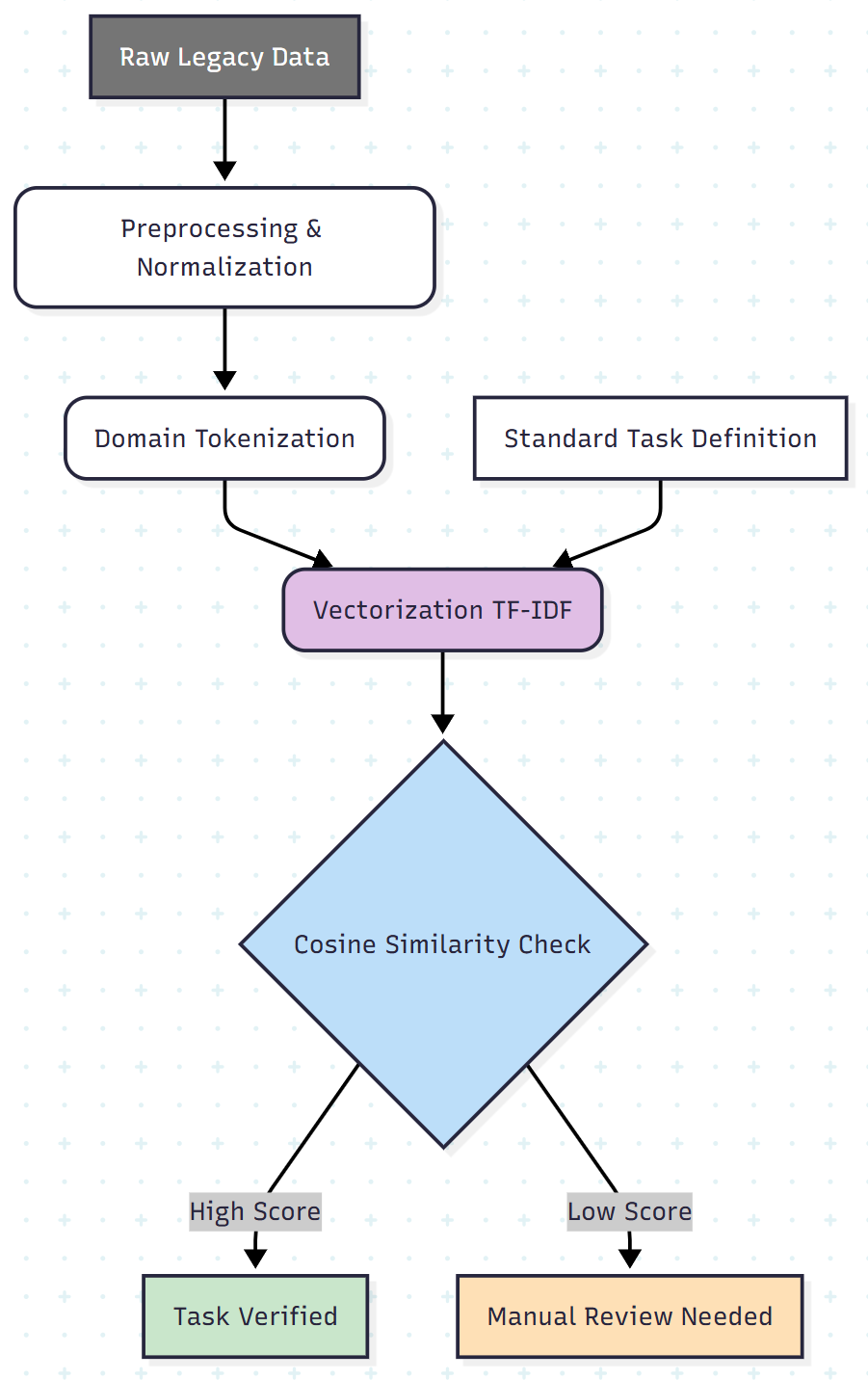
Step 1: Aggressive Normalization
Before any AI touches the data, character sets must be normalized. This is particularly important in global systems that accept various Unicode formats, which are common in Asian or legacy mainframe environments.
We use NFKC (Normalization Form KC) to standardize characters, converting full-width characters, compatibility characters, and visually distinct symbols into their standard equivalents.
Python implementation:
import unicodedata
def normalize_text(text):
# Normalize unicode characters (e.g., full-width to half-width)
normalized = unicodedata.normalize('NFKC', text)
# Standardize common variations via simple string replacement
# Example: Standardizing brackets
normalized = normalized.replace("【", "[").replace("】", "]")
# Lowercase for consistency
return normalized.lower()
raw_input = "12-month Inspection" # Messy full-width
print(normalize_text(raw_input))
# Output: "12-month inspection"Step 2: Domain-Specific Tokenization
Off-the-shelf tokenizers (such as NLTK or standard spaCy models) often fail on technical jargon. They assume grammatical structure, while maintenance logs frequently lack grammar altogether.
To address this, we build a custom dictionary and synonym replacement table.
- Discovery: Run frequency analysis on raw text to identify the top 5,000 terms.
- Mapping: Manually map variations to canonical terms.
| Raw Term | Canonical Term |
| chk | check |
| repl | replace |
| brk | brake |
| elem | element |
Step 3: Vectorization with TF-IDF
Once the text is cleaned, we need to understand the relative importance of words. Simple keyword matching fails because common words (e.g., "the," "and," "vehicle") appear everywhere but hold no discriminatory power.
TF-IDF (Term Frequency–Inverse Document Frequency) assigns higher weight to rare, specific terms (such as "caliper" or "manifold") and lower weight to ubiquitous ones.
This allows the system to distinguish between "replaced brake caliper" and "checked brake light," even though both contain the word "brake."
Step 4: Cosine Similarity for Verification
This is the core logic. To determine whether a maintenance task was performed, we represent both the official task description and the user record as vectors and calculate the cosine similarity between them.
- 1.0: Perfect match
- 0.0: No relation
We can define thresholds such as:
- Score > 0.6: High confidence (task performed)
- Score 0.2–0.6: Ambiguous (requires human review)
- Score < 0.2: Not performed
Python example:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# The "Gold Standard" description of the task
standard_task = ["replace engine oil filter element"]
# Actual messy logs from technicians
user_logs = [
"chngd oil and elem", # Log A
"wiper blade replaced", # Log B
"eng oil filter repl" # Log C
]
# Initialize Vectorizer
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(standard_task + user_logs)
# Calculate similarity between Standard Task (index 0) and logs
standard_vec = tfidf_matrix[0:1]
log_vecs = tfidf_matrix[1:]
similarities = cosine_similarity(standard_vec, log_vecs)
print(similarities)
# Output will show High scores for Log A and C, Low score for Log BResults and Challenges
In real-world implementations, this approach often exposes uncomfortable truths about data quality. In the underlying study, accuracy improved significantly by refining the synonym table.
However, two edge cases remain common:
- Negation: "Did not replace filter" closely resembles "replace filter" in a bag-of-words model. This requires explicit negation handling during preprocessing.
- Contextual ambiguity: "Bumper" may mean "Repaired Bumper" or just "Bumper Inspection." This is often addressed by pairing nouns with action verbs such as check, replace, or repair.
Conclusion
You don't always need a neural network to solve natural language problems. For legacy data migration and verification, a pipeline built on Unicode normalization, domain dictionaries, and TF-IDF similarity offers a transparent, explainable, and lightweight solution.
By converting free-text fields into structured confidence scores, organizations can finally unlock the historical data buried in their systems — paving the way for predictive maintenance and genuine digital transformation.
Opinions expressed by DZone contributors are their own.
Comments