Adaptive Sampling in an IoT World
Reduce power usage and bandwidth utilization with Adaptive Sampling techniques for IoT applications.
Join the DZone community and get the full member experience.
Join For FreeThe Internet of Things (IoT) is now an omnipresent network of connected devices that communicate and exchange data over the internet. These devices can be anything from industrial machinery monitoring, weather and air quality monitoring systems, and security cameras to smart thermostats and refrigerators to wearable fitness trackers. As the number of IoT devices increases, so does the volume of data they generate. A typical application of this data is to improve the performance and efficiency of the systems being monitored and gain insights into their users' behavior and preferences.
However, the sheer volume makes it challenging to collect and analyze such data. Furthermore, a large volume of data can overwhelm both the communication channels and the limited amounts of power and processing on edge devices. This is where adaptive sampling techniques come into play. These techniques can reduce workload, maximize resource utilization requirements, and improve the accuracy and reliability of the data.
Adaptive Sampling
Adaptive sampling techniques "adapt" their sampling or transmission frequency based on the specific needs of the device or changes in the system of interest. For example, consider a device on a limited data plan, a low-power battery, or a compute-restricted platform.
Examples:
- A temperature monitoring sensor may collect data more frequently when there are rapid changes in temperature and less frequently when the temperature remains stable.
- A security camera captures images at a faster frame rate or higher resolution when there is some activity in the field of view.
- An air particulate meter increases its sampling rate when it notices the air quality deteriorating.
- A self-driving car constantly senses the environment but may send special edge cases back to a central server for edge case discovery.
What and Where to Sample
Your expected resource utilization improvements guide what to and where to sample. There are two sites to implement sampling: At measurement or transmission.

Sampling at measurement:
- The edge device will only measure (or update measurement frequency) when an algorithm (either running on the edge device or on a server) deems fit.
- Reduces power and computing.
- Periodically improves network bandwidth utilization.
Sampling at transmission:
- The edge device measures continuously and processes this with some algorithm running locally. If the sample is high entropy, upload data to the cloud/ server.
- Power and compute at measurement unaffected.
- Reduces network bandwidth utilization.
Identifying Important and Useful Data
We have often heard the term "data, data, data." But is all data equal? Not really. Data is most useful when it brings information. This is true even for Big Data applications that are admittedly data-hungry. For example, Machine Learning and Statistical systems all need "high quality" data, not just large quantities.
So how do we find high-quality data? Entropy!
Entropy
Entropy is the measurement of uncertainty in the system. In a more intuitive explanation, entropy is the measure of "information" in a system. For example, a system with a constant value or constant rate of change (say temperature). In optimal working conditions, there is no new information. You will get the expected measurement every time you sample; this is low entropy.
On the other hand, if the temperature changes "noisily" or "unexpectedly," the entropy in the system is high; there is new and interesting information. The more unexpected the change, the larger the entropy and the more important that measurement.
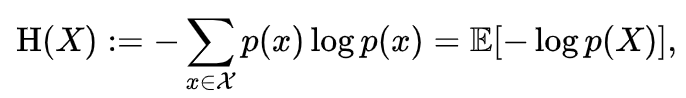
When the probability of occurrence 'p(x)' is low, entropy is high, and vice versa. A measurement probability of 1 (something we really expect is going to happen) yields 0 entropy, and rightly so.
This principle of "informational value" is central to adaptive sampling.
Some State of the Art Techniques
The basic logic flow in all adaptive techniques is:
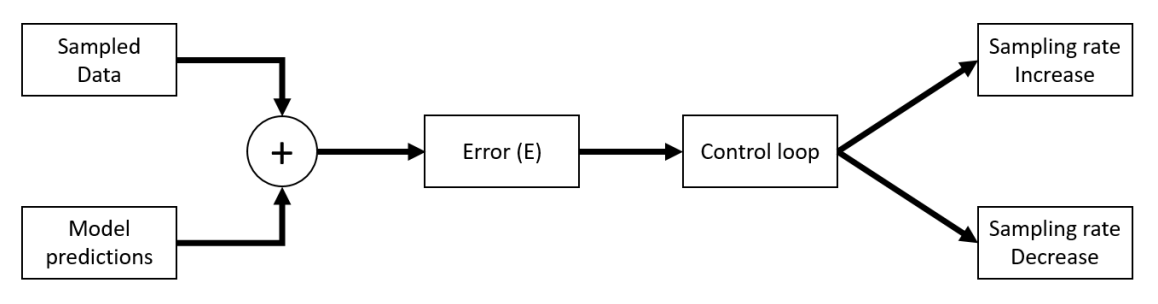
These "Model Prediction" algorithms analyze past data and identify patterns that help to predict if a high entropy event is likely to occur, allowing the system to focus its data collection efforts. The magic lies in how well we can model our predictions.
Adaptive Filtering methods:
- These methods apply filtering techniques on measurements to estimate measurements in the next time steps.
- These could be FIR (Finite Impulse Response) or IIR (Infinite Impulse Response) techniques like:
- Weighted moving average (can be made more expressive with probabilistic or exponential treatment)
- Sliding window-based methods
- They are relatively low in complexity but may have a non-trivial memory footprint to buffer past measurements.
- Need small amounts of data for configuring.
Kalman Filter methods:
- Kalman Filters are efficient and have small memory footprints.
- They can be relatively complex and hard to configure but work well when tuned correctly.
- Need small amounts of data for configuring.
Machine Learning methods:
- Using past collected data, we can build machine learning models to predict the next state of the system under observation.
- These are the more complex but also generalize well.
- Depending on the task and complexity, large amounts of data may be needed for training.
Major Benefits
- Improved efficiency: By collecting and analyzing data from a subset of the available data, IoT devices can reduce workload and resource requirements. This helps improve efficiency and performance and reduces data collection, analysis, and storage costs.
- Better accuracy: By selecting the data sources that are most likely to provide the most valuable or informative data, adaptive sampling techniques can help to improve the accuracy and reliability of the data. This can be particularly useful for making decisions or taking actions based on the data.
- Greater flexibility: Adaptive sampling techniques allow IoT devices to adapt to changes in the data sources or the data itself. This can be particularly useful for devices deployed in dynamic or changing environments, where the data may vary over time.
- Reduced post-processing complexity: By collecting and analyzing data from a subset of the available data sources, adaptive sampling techniques can help to reduce the complexity of the data and make it easier to understand and analyze. This can be particularly useful for devices with limited processing power or storage capacity or teams with limited data science/ engineering resources.
Potential Limitations
- Selection bias: By selecting a subset of the data, adaptive sampling techniques may introduce selection bias into the data. This can occur if the models and systems are trained on a specific type of data, which is not representative of the overall data population, leading to inaccurate or unreliable conclusions.
- Sampling errors: There is a risk of errors occurring in the sampling process, which can affect the accuracy and reliability of the data. These errors may be due to incorrect sampling procedures, inadequate sample size, or non-optimal configurations.
- Resource constraints: Adaptive sampling techniques may require additional processing power, storage capacity, or bandwidth, which may not be available on all IoT devices. This can limit adaptive sampling techniques on specific devices or in certain environments.
- Runtime complexity: Adaptive sampling techniques may involve the use of machine learning algorithms or other complex processes, which can increase the complexity of the data collection and analysis process. This could be challenging for devices with limited processing power or storage capacity.
Workarounds
- Staged deployment: Instead of deploying a sampling scheme on all devices, deploy on small but representative test groups. Then the "sampled" data from these groups can be analyzed against the more expansive datasets for biases and domain mismatches. Again, this can be done in stages and iteratively, ensuring our system is never highly biased.
- Ensemble of Sampling techniques: Different devices can be armed with slightly different sampling techniques, varying from sample sizes and windows to different algorithms. Sure, this increases the complexity of post-processing, but it takes care of sampling errors and selection biases.
- Resource constraints and Runtime complexity are hard to mitigate. Unfortunately, that is the cost of implementing better sampling techniques.
- Finally, test, test, and more tests.
Takeaways
- Adaptive Sampling can be a useful tool for IoT if one can model the system being observed.
- We briefly introduced a few modeling approaches with varying complexities.
- We discussed some benefits, challenges, and solutions for deployment.
Opinions expressed by DZone contributors are their own.
Comments