Error Budgets 2.0 Agentic AI for SLO-Apprehensive Deployments
The article introduces error budgets 2.0, a new approach that uses agentic AI to make deployments SLO-aware and proactive rather than reactive.
Join the DZone community and get the full member experience.
Join For FreeService level objectives (SLOs) and error budgets are key in site reliability engineering (SRE). They help teams balance reliability with innovation, ensuring users get a stable service while developers can safely deliver new features
But in practice, administering error budgets inside CI/CD channels is hard:
- Teams frequently notice error budget burn after an outage.
- Deployment scripts are not apprehensive of SLOs.
- Rollback opinions still calculate heavily on manual intervention and judgment.
Agentic AI — intelligent agents that do not just run scripts but can reason about pretensions, constraints, and pitfalls. Applied to error budgets, agentic AI introduces error budgets 2.0 SLOs, apprehensive deployments that acclimate in real-time.
Why Error Budgets Need AI
Traditional error budget workflows are fundamentally reactive:
- A burn-rate alert fires.
- SREs investigate.
- Humans debate whether to halt releases.
This process lags behind the speed and complexity of modern cloud-native deployments. By the time a human team reacts, customer experience may already be degraded.
Agentic AI introduces a proactive model:
- Continuous burn-rate monitoring: AI agents track error budgets in real time, not just after alerts trigger.
- Adaptive release governance: Rollout decisions (continue, pause, or rollback) can be made based on live SLO health signals.
- Automated mitigation: AI can suggest or even trigger mitigation strategies — such as scaling, traffic shaping, or safe rollback — without waiting for human intervention.
In essence, AI transforms error budgets from a reactive guardrail into a dynamic control system that keeps pace with today’s rapid release cycles.
What Error Budgets 2.0 Looks Like
The coming elaboration of error budgets moves beyond static dashboards that rely on mortal interpretation. AI-driven agents become active actors in the release channel:
- Pre-deployment: Ensure the remaining error budget is sufficient to authorize a release, avoiding potentially unstable deployments.
- During deployment: Keep checking in real time for quiet periods, errors, and gaps, and compare them with SLOs as updates go live.
- Post-deployment: Adjust the pace of the rollout or initiate a rollback when burn rates surpass the set limit.
Error Budgets 2.0 arae self-managing, adaptive, and embedded directly within the CI/CD workflow. They shift error budgets from an unresistant monitoring tool into an active safety medium that governs trustworthiness in real time.
Diagram: AI Agents in an SLO-Aware Pipeline
![AI agent monitoring error budgets]()
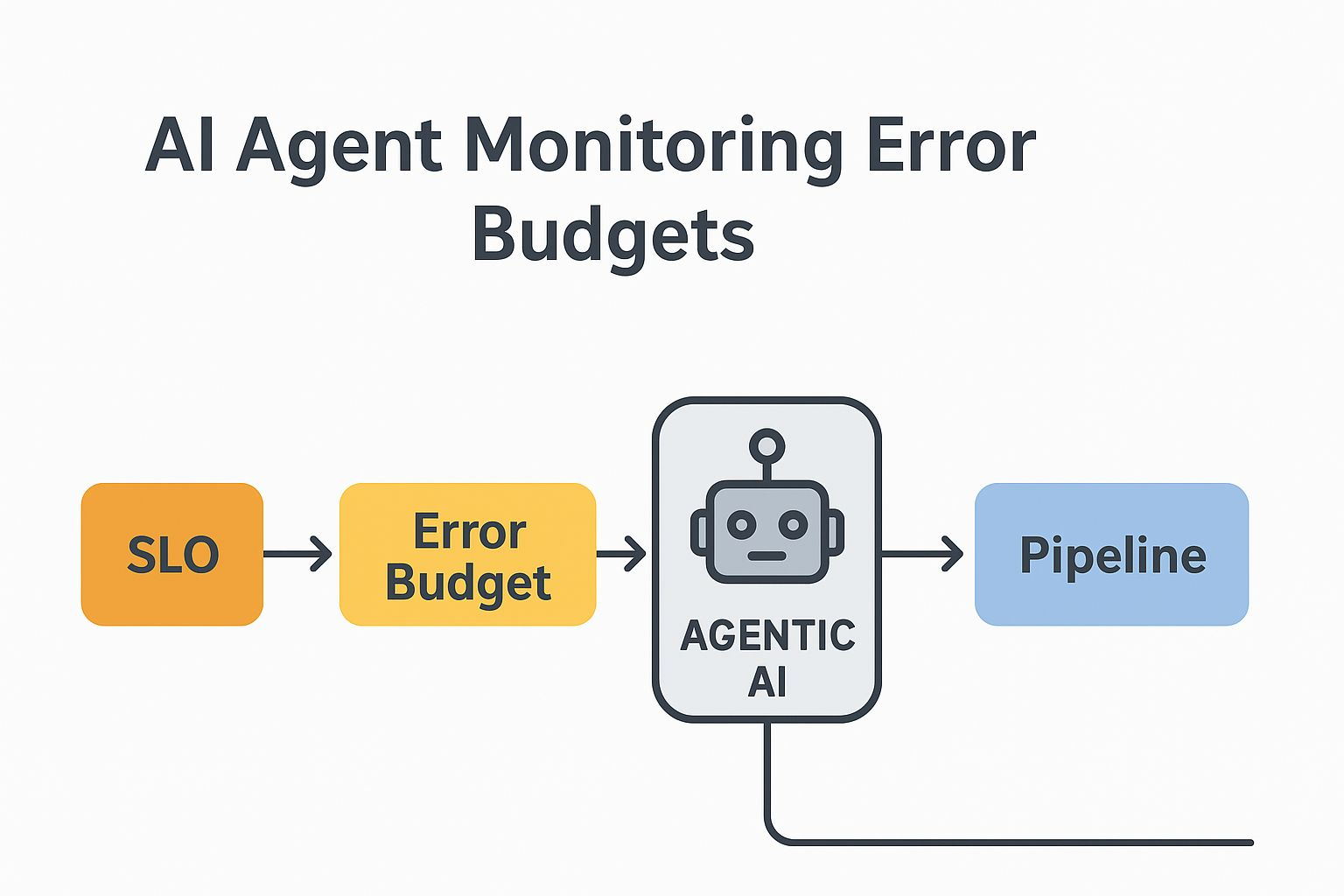
The above diagram shows how service reliability is safeguarded during deployments by placing an AI agent between error budgets and the release pipeline. The process is anchored by the service level objective (SLO), which sets the intended reliability level for the system. From the SLO, an error budget is derived, representing the acceptable margin for failure. This budget is then fed into an agentic AI system, illustrated with a robot icon, which acts as a gatekeeper. The AI evaluates the current error budget status and determines whether a deployment should continue, be blocked, or rolled back.
Based on this decision, control flows into the pipeline, where the deployment either proceeds or halts. This setup emphasizes the role of AI in continuously monitoring SLOs and error budgets to enforce safe, automated, and reliability-aware deployments.
Example: AI Agent Monitoring Error Budgets
# ai_slo_agent.py
import json
import logging
logging.basicConfig(level=logging.INFO)
def check_error_budget(burn_rate, remaining_budget, config):
if remaining_budget < config["min_budget_percent"]:
logging.warning("Error budget exhausted. Blocking deployment.")
return "block"
if burn_rate > config["max_burn_rate"]:
logging.warning("Burn rate too high. Triggering rollback.")
return "rollback"
logging.info("Within thresholds. Continuing deployment.")
return "continue"
# Example config (could be loaded from a file or API)
config = {
"min_budget_percent": 5,
"max_burn_rate": 2
}
burn_rate = 2.5
remaining_budget = 12 # percent
decision = check_error_budget(burn_rate, remaining_budget, config)
print(f"Deployment decision: {decision}")WARNING:root:Burn rate too high. Triggering rollback.
Deployment decision: rollbacksteps:
- name: Load Config
run: curl -s http://slo-config-service/config.json -o config.json
- name: Deploy Canary
run: deploy_canary.sh
- name: SLO Check
run: |
decision=$(python ai_slo_agent.py --config config.json)
if [[ "$decision" == "block" ]]; then
echo "❌ Error budget exhausted. Blocking deployment."
exit 1
elif [[ "$decision" == "rollback" ]]; then
echo "⚠️ High burn rate. Triggering rollback."
rollback.sh
exit 1
fiA Day in the Life of an SLO-Apprehensive Deployment
- Code is committed. An AI agent evaluates the current error budget — with 20 percent still available, the deployment is approved to proceed.
- Canary rollout begins. Canary rollout begins. Activity spikes, and the burn rate rises to 2.3 — a clear sign of higher risk.
- AI agent intervenes. Detecting the violation, driving an automatic rollback, and filing an incident ticket with logs and traces attached
- Programmers fix and retry. After the error budget returns to acceptable levels, the AI agent greenlights the continuation of the rollout.
Outcome releases come safer, outages are shorter, and responsible governance happens in real time — without breaking down delivery.
Challenges Ahead
Trust and Explainability
For AI-driven chaos testing and release decisions to be adopted widely, engineers must understand the rationale behind automated actions. Black-box recommendations (e.g., blocking a release) can erode confidence unless accompanied by clear, interpretable explanations supported by evidence such as error budget trends or anomaly detections.
Dynamic Policies
Cloud-native systems are heterogeneous, and resilience requirements vary across services. Relying on a uniform policy, like fixed burn rate thresholds, fails to address dynamic system needs. The challenge lies in defining and enforcing service-specific adaptive policies that balance availability, performance, and business impact in real time.
Cultural Shift
The transition from dashboard-driven manual decisions to autonomous AI-assisted operations is as much a cultural transformation as it is a technical one. Teams must gradually develop confidence in AI recommendations, establish new review practices, and redefine operational roles around human-in-the-loop oversight and governance.
The Road Ahead
Error budgets 2.0 mark a shift from reactive firefighting to proactive, AI-driven reliability enforcement. With agentic AI at the core:
- SLO-aware by default: Deployments automatically evaluate their impact based on live error budget metrics.
- Invisible rollbacks: Mitigation happens before customers ever notice an outage.
- Built-in balance: Innovation velocity and user trust are managed automatically, not manually debated.
As systems scale, success won’t come from adding more dashboards. It will come from smarter agents that guard reliability in real time — turning error budgets into an active control system for modern delivery.
Reference Repo Structure
The following repo structure shows how to organize the AI SLO agent inside a DevOps project:
error-budgets-ai/
├── ai_slo_agent.py # Core AI agent for error budget checks
├── pipeline.yaml # Example CI/CD pipeline integration
├── requirements.txt # Dependencies (e.g., prometheus-api-client, requests)
├── README.md # Documentation for setup and usage
└── tests/
└── test_agent.py # Unit tests for AI agent logicSample test for the AI SLO agent:
# tests/test_agent.py
from ai_slo_agent import check_error_budget
def test_block_when_budget_low():
assert check_error_budget(burn_rate=1.0, remaining_budget=3) == "block"
def test_rollback_when_burn_high():
assert check_error_budget(burn_rate=3.0, remaining_budget=15) == "rollback"
def test_continue_when_safe():
assert check_error_budget(burn_rate=1.0, remaining_budget=20) == "continue"References
- S. Nigam, “Redefining Error Budgets and SLOs for Enterprise Systems: Toward Adaptive Reliability Management,” White Paper, 2025
- C. Bronsdon, “AI Agent Reliability Strategies That Stop AI Failures Before They Start,” Galileo.ai, Jul 2025
Opinions expressed by DZone contributors are their own.
Comments