Token Attribution Framework for Agentic AI in CI/CD
A practical framework for tracking attribution, setting budgets, and circuit-breaking spending on LLM in your CI/CD pipeline by using an OpenTelemetry implementation.
Join the DZone community and get the full member experience.
Join For FreeThe Silent Killer No One Mentions Until the Bill Comes
Most papers about "agentic AI in production" stop where the problem starts: price. Interacting with Claude or GPT requires a natural pace setter: you, reading the generated text. Take the same agent out of chat mode and drop it into CI/CD, nightly batch, webhook handling; the pacing goes away, and you're running the thing purely on computer time, at computer prices.
The numbers look even scarier when you dig deeper. ReAct-style looped execution prepends all outputs to the following prompts, meaning you consume tokens at roughly O(n²). A PR review agent in a loop of three steps, which costs $0.04 in local development, can rack up a charge of $0.40+ once it gets stuck in its looping process. With hundreds of PRs a week, that could easily amount to five-figure surprises in your bill.
But not only that, with that kind of bill, you don't know which particular agent, which repo, which user, or which prompt you spent the money on. The invoice provided by your vendor simply says "API usage." Since you won't be able to attribute the charges properly, the only recourse is a blunt measure such as "ban Sonnet in CI." Such a measure would render useless all the valuable agents you had.
This paper proposes an attribution-based architecture, a thin layer between you and your LLM vendor that adds proper deployment-aware attribution to each API call, enforces budget limits at proper levels, and cuts the looping processes off before they start racking up charges. The source code is written in Python and framework agnostic. It employs OpenTelemetry's gen_ai.* semantics, allowing you to send the telemetry anywhere.
Architecture
The design has four layers. Each one fails closed by default.
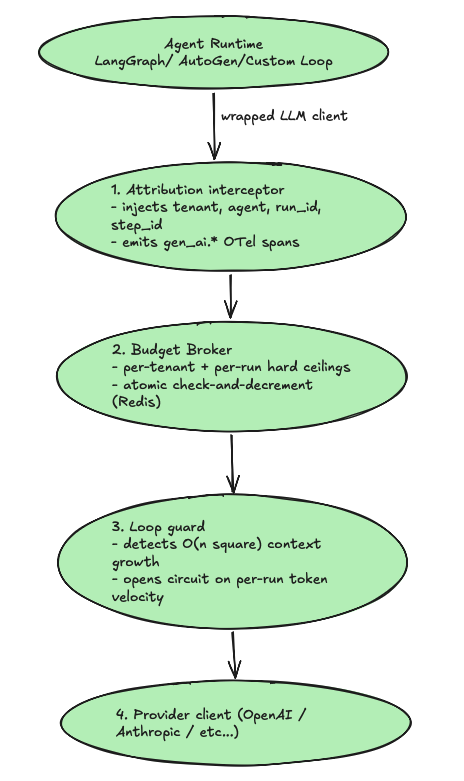
"Why not use observability as a gateway?" Because LangSmith, Helicone, Langfuse, and Arize Phoenix observe costs retroactively. None of them intercepts in the execution path. They alert you about the $437 weekend, but they don't prevent it. Prevention involves enforcing costs asynchronously before the inference API call is made outside the VPC.
The Cost Attribution Context
The outbound API calls from an agent must include a context object. This is the only decision that matters, and yet it's the one most often missed by teams.
# attribution.py
from dataclasses import dataclass, field, asdict
from typing import Optional
import contextvars
import uuid
@dataclass(frozen=True)
class CostContext:
"""Travels with every LLM call. Used for budgets, traces, and chargeback."""
tenant_id: str # business unit / team / customer
agent_id: str # logical agent name, e.g. "pr-reviewer"
agent_version: str # prompt+code hash, lets you A/B prompts
run_id: str # one full agent invocation (a "task")
step_id: str # individual reasoning step inside the run
parent_run_id: Optional[str] = None # for hierarchical agents
repo: Optional[str] = None # CI metadata
pr_number: Optional[int] = None
triggered_by: Optional[str] = None # user, scheduler, webhook, ...
labels: dict = field(default_factory=dict)
_current_context: contextvars.ContextVar[Optional[CostContext]] = \
contextvars.ContextVar("cost_context", default=None)
def new_run(tenant_id: str, agent_id: str, agent_version: str, **kw) -> CostContext:
return CostContext(
tenant_id=tenant_id,
agent_id=agent_id,
agent_version=agent_version,
run_id=str(uuid.uuid4()),
step_id="0",
**kw,
)
def child_step(ctx: CostContext, step_label: str) -> CostContext:
return CostContext(**{**asdict(ctx), "step_id": f"{ctx.step_id}.{step_label}"})
def set_current(ctx: CostContext):
_current_context.set(ctx)
def get_current() -> Optional[CostContext]:
return _current_context.get()Since the 'step_id' is represented using a dot notation '0.plan.2.tool.web_search', one single tracing query can compute the cost of a certain step ("what was the planning cost last week for all the PR reviewers?") without having to process free-text tags.
The Attribution Interceptor
The interceptor adds instrumentation around the LLM client, resulting in emitting spans for each request according to the OpenTelemetry conventions for GenAI services ('gen_ai.system', 'gen_ai.request.model', 'gen_ai.usage.input_tokens', etc). What really makes the difference is the additional namespace of 'cost.*'.
# interceptor.py
import time
from opentelemetry import trace
from opentelemetry.trace import Status, StatusCode
from attribution import get_current
tracer = trace.get_tracer("agentic-cost-gateway")
# Provider price tables in USD per 1M tokens (input, output).
# Keep this in config — prices move quarterly.
PRICE_TABLE = {
"claude-sonnet-4-7": (3.00, 15.00),
"claude-haiku-4-5": (0.80, 4.00),
"gpt-4o": (2.50, 10.00),
"gpt-4o-mini": (0.15, 0.60),
}
def estimated_cost_usd(model: str, input_tokens: int, output_tokens: int) -> float:
p_in, p_out = PRICE_TABLE.get(model, (0.0, 0.0))
return (input_tokens * p_in + output_tokens * p_out) / 1_000_000
class AttributedLLMClient:
"""Wraps a raw provider SDK and emits attributed OTel spans."""
def __init__(self, raw_client, system_name: str):
self._raw = raw_client
self._system = system_name # "anthropic", "openai", ...
def chat(self, *, model: str, messages: list, **kw) -> dict:
ctx = get_current()
if ctx is None:
raise RuntimeError(
"No CostContext set. Wrap your agent loop in `set_current(new_run(...))`."
)
with tracer.start_as_current_span("gen_ai.chat") as span:
span.set_attribute("gen_ai.system", self._system)
span.set_attribute("gen_ai.request.model", model)
span.set_attribute("gen_ai.operation.name", "chat")
# Business attribution.
span.set_attribute("cost.tenant_id", ctx.tenant_id)
span.set_attribute("cost.agent_id", ctx.agent_id)
span.set_attribute("cost.agent_version", ctx.agent_version)
span.set_attribute("cost.run_id", ctx.run_id)
span.set_attribute("cost.step_id", ctx.step_id)
if ctx.repo:
span.set_attribute("cost.repo", ctx.repo)
if ctx.pr_number:
span.set_attribute("cost.pr_number", ctx.pr_number)
t0 = time.monotonic()
try:
resp = self._raw.chat(model=model, messages=messages, **kw)
except Exception as e:
span.set_status(Status(StatusCode.ERROR, str(e)))
span.set_attribute("cost.outcome", "provider_error")
raise
latency_ms = (time.monotonic() - t0) * 1000
usage = resp.get("usage", {})
in_tok = usage.get("input_tokens", 0)
out_tok = usage.get("output_tokens", 0)
cost = estimated_cost_usd(model, in_tok, out_tok)
span.set_attribute("gen_ai.usage.input_tokens", in_tok)
span.set_attribute("gen_ai.usage.output_tokens", out_tok)
span.set_attribute("gen_ai.response.finish_reasons",
resp.get("finish_reason", "stop"))
span.set_attribute("cost.usd", cost)
span.set_attribute("cost.latency_ms", latency_ms)
span.set_attribute("cost.outcome", "ok")
return respOne line of the trace from a PR cost analysis would then look like the following in any backend that supports OTel tracing (Jaeger, Tempo, Honeycomb, Datadog, ClickStack, etc.):
agent.run cost.run_id=abc123 cost.usd=0.41
├── gen_ai.chat step_id=0.plan model=claude-sonnet-4-7 cost.usd=0.04
├── gen_ai.chat step_id=0.tool.diff model=claude-haiku-4-5 cost.usd=0.01
├── gen_ai.chat step_id=0.review.1 model=claude-sonnet-4-7 cost.usd=0.18
└── gen_ai.chat step_id=0.review.2 model=claude-sonnet-4-7 cost.usd=0.18You will be able to ask "what agent/which repo cost us the most last week?" with one question, and you'll get a structured response, not a regular expression search through log entries.
The Budget Broker
This broker makes sure that there are hard limits set before the call leaves your network. The challenge is doing the checking and decrementing atomically for multiple worker agents; race conditions translate into dollars lost here. Redis and a Lua script do the job in one shot.
# budget_broker.py
import redis
from dataclasses import dataclass
# Atomic: read current spend, compare to limit, increment if room.
# Returns 1 if approved, 0 if over budget. The increment uses a tentative
# token estimate; the interceptor reconciles to actuals after the call.
RESERVE_LUA = """
local key = KEYS[1]
local limit = tonumber(ARGV[1])
local request = tonumber(ARGV[2])
local ttl = tonumber(ARGV[3])
local current = tonumber(redis.call('GET', key) or '0')
if current + request > limit then
return 0
end
redis.call('INCRBY', key, request)
redis.call('EXPIRE', key, ttl)
return 1
"""
RECONCILE_LUA = """
local key = KEYS[1]
local delta = tonumber(ARGV[1])
local new = redis.call('INCRBY', key, delta)
if new < 0 then
redis.call('SET', key, '0')
end
return new
"""
@dataclass
class Budget:
scope_key: str # e.g. "tenant:platform-team:run:abc123"
limit_tokens: int
ttl_seconds: int = 3600
class BudgetBroker:
def __init__(self, redis_url: str):
self.r = redis.Redis.from_url(redis_url)
self._reserve = self.r.register_script(RESERVE_LUA)
self._reconcile = self.r.register_script(RECONCILE_LUA)
def reserve(self, b: Budget, estimated_tokens: int) -> bool:
ok = self._reserve(
keys=[b.scope_key],
args=[b.limit_tokens, estimated_tokens, b.ttl_seconds],
)
return bool(ok)
def reconcile(self, scope_key: str, actual_minus_estimate: int):
"""Called after the response. Positive delta = we under-estimated."""
self._reconcile(keys=[scope_key], args=[actual_minus_estimate])Wire the broker into the interceptor:
# in AttributedLLMClient.chat, before calling self._raw.chat:
estimated_in = estimate_tokens(messages) # tiktoken or anthropic-tokenizer
estimated_out = kw.get("max_tokens", 1024)
estimated_total = estimated_in + estimated_out
# Two-level budget: per-run AND per-tenant-per-day.
run_key = f"tenant:{ctx.tenant_id}:run:{ctx.run_id}"
day_key = f"tenant:{ctx.tenant_id}:day:{date.today().isoformat()}"
if not broker.reserve(Budget(run_key, RUN_LIMIT, ttl_seconds=3600),
estimated_total):
span.set_attribute("cost.outcome", "run_budget_exceeded")
raise BudgetExceeded(f"Run {ctx.run_id} hit per-run ceiling")
if not broker.reserve(Budget(day_key, TENANT_DAILY_LIMIT, ttl_seconds=86400),
estimated_total):
# Refund the run reservation we just took.
broker.reconcile(run_key, -estimated_total)
span.set_attribute("cost.outcome", "tenant_daily_exceeded")
raise BudgetExceeded(f"Tenant {ctx.tenant_id} over daily limit")
# ... call provider ...
actual_total = in_tok + out_tok
broker.reconcile(run_key, actual_total - estimated_total)
broker.reconcile(day_key, actual_total - estimated_total)There are two important budgets that are broken on different levels:
| budget | CATCHES | FAILURE MODE |
|---|---|---|
| Per-Run |
One agent is hung up in an endless loop |
Terminate the run |
| Tenant per day | One bug found in *all* agents from one team | Stop new runs, notify |
| Agent per hour (optional) | One rogue agent with a buggy version of prompt | Rollback, notify |
The third tier is optional, but affordable; it is the same broker with another key pair, and it will help you spot the regression that was caused by the prompt modification during deployment.
The Loop Guard
Per-run limits prevent the execution of expensive tasks eventually. The loop guard will spot fast-executing tasks — the ReAct loop that started reading each file in the repository, as the planner misunderstood the diff. The indicator that we should track is token velocity per step: if the number of tokens consumed by the task during step n increases by a configured value compared to step n-1, then we break the loop.
# loop_guard.py
from collections import defaultdict
class LoopGuard:
"""Detects pathological context growth across steps within a run."""
def __init__(self, growth_factor_limit: float = 1.6,
absolute_step_limit: int = 50):
self.growth_factor_limit = growth_factor_limit
self.absolute_step_limit = absolute_step_limit
self._last_input_tokens: dict[str, int] = defaultdict(int)
self._step_count: dict[str, int] = defaultdict(int)
def check(self, run_id: str, current_input_tokens: int) -> None:
self._step_count[run_id] += 1
if self._step_count[run_id] > self.absolute_step_limit:
raise CircuitOpen(
f"Run {run_id} exceeded {self.absolute_step_limit} steps"
)
last = self._last_input_tokens[run_id]
if last > 0 and current_input_tokens > last * self.growth_factor_limit:
raise CircuitOpen(
f"Run {run_id}: context grew {current_input_tokens / last:.2f}x "
f"(limit {self.growth_factor_limit}x). Likely loop."
)
self._last_input_tokens[run_id] = current_input_tokens
def end_run(self, run_id: str):
self._last_input_tokens.pop(run_id, None)
self._step_count.pop(run_id, None)A factor of 1.6× is not magic either. It follows from the analysis of well-functioning agents: a properly operating planning-executing loop with the tool's output and reasoning, where input roughly doubles per iteration. A factor of 2× almost certainly implies that the agent has read the same file twice or even loaded the full RAG corpus.
In the multi-process setup, replace the in-memory dict with Redis hash — the same code, the same keys.
Putting It All Together: A Wrapped Agent Loop
# pr_review_agent.py
from attribution import new_run, child_step, set_current
from interceptor import AttributedLLMClient
from budget_broker import BudgetBroker
from loop_guard import LoopGuard, CircuitOpen
broker = BudgetBroker("redis://budget-broker:6379")
guard = LoopGuard(growth_factor_limit=1.6, absolute_step_limit=20)
llm = AttributedLLMClient(raw_anthropic_client, system_name="anthropic")
def review_pr(repo: str, pr_number: int, triggered_by: str) -> dict:
run_ctx = new_run(
tenant_id="platform-team",
agent_id="pr-reviewer",
agent_version="prompt-v7-2026-05-09",
repo=repo,
pr_number=pr_number,
triggered_by=triggered_by,
)
set_current(run_ctx)
try:
# Step 1: plan
set_current(child_step(run_ctx, "plan"))
plan = llm.chat(
model="claude-haiku-4-5", # cheap model for planning
messages=plan_prompt(repo, pr_number),
)
guard.check(run_ctx.run_id, plan["usage"]["input_tokens"])
# Step 2..N: execute reviewers per file
results = []
for i, file_path in enumerate(plan["files_to_review"]):
set_current(child_step(run_ctx, f"review.{i}"))
r = llm.chat(
model="claude-sonnet-4-7", # premium for actual review
messages=review_prompt(file_path),
)
guard.check(run_ctx.run_id,
r["usage"]["input_tokens"])
results.append(r)
return {"plan": plan, "reviews": results}
except CircuitOpen as e:
# Loop guard fired — record but don't crash the pipeline.
return {"status": "circuit_open", "reason": str(e)}
finally:
guard.end_run(run_ctx.run_id)Three big takeaways:
1. Model routing happens at the call site, not the gateway. The difference between a cheap planner on Haiku and an expensive reviewer on Sonnet is the number one opportunity for cost savings. It will always be invisible in daily totals without per-call attribution.
2. Failure events get logged, not bubbled up to a panic alert. Circuit open is an outcome, not an exception. CI Bot writes a comment ("Review skipped — agent circuit opened, run abc123"), and then the on-call and pipeline get notified.
3. Full cost attribution survives failures. The OTel span representing a failed task will have a 'cost.outcome="run_budget_exceeded"' attribute in addition to all the regular call site attributions. So those expensive failures can go right into your dashboard.
Querying the Data
When every span is attributed, getting the right dashboard query takes three layers. With ClickHouse (or any columnar DB where you've put OTel):
Cost per agent, last 7 days, with growth rate:
SELECT
SpanAttributes['cost.agent_id'] AS agent,
SpanAttributes['cost.agent_version'] AS version,
sum(toFloat64OrZero(SpanAttributes['cost.usd'])) AS usd_total,
count() AS calls,
round(usd_total / calls, 4) AS usd_per_call
FROM otel_traces
WHERE Timestamp > now() - INTERVAL 7 DAY
AND SpanName = 'gen_ai.chat'
GROUP BY agent, version
ORDER BY usd_total DESC;Top 10 most expensive runs, with the step that did the damage:
WITH run_costs AS (
SELECT
SpanAttributes['cost.run_id'] AS run_id,
SpanAttributes['cost.agent_id'] AS agent,
SpanAttributes['cost.repo'] AS repo,
sum(toFloat64OrZero(SpanAttributes['cost.usd'])) AS usd
FROM otel_traces
WHERE Timestamp > now() - INTERVAL 1 DAY
GROUP BY run_id, agent, repo
ORDER BY usd DESC
LIMIT 10
)
SELECT
r.run_id, r.agent, r.repo, r.usd,
argMax(SpanAttributes['cost.step_id'],
toFloat64OrZero(SpanAttributes['cost.usd'])) AS top_step
FROM run_costs r
JOIN otel_traces t ON SpanAttributes['cost.run_id'] = r.run_id
GROUP BY r.run_id, r.agent, r.repo, r.usd
ORDER BY r.usd DESC;Budget rejection rate by tenant (the canary):
SELECT
SpanAttributes['cost.tenant_id'] AS tenant,
countIf(SpanAttributes['cost.outcome'] = 'run_budget_exceeded') AS run_kills,
countIf(SpanAttributes['cost.outcome'] = 'tenant_daily_exceeded') AS tenant_kills,
count() AS total_calls
FROM otel_traces
WHERE Timestamp > now() - INTERVAL 1 DAY
GROUP BY tenant
HAVING run_kills + tenant_kills > 0
ORDER BY run_kills DESC;The fact that budgets are rejected is what's making them effective, so having any rejection rate is good. A rejection rate greater than ~5% probably means either that your budgets are too tight, or your agents have a bug – either of which would be worth investigating.
What This Gives You
- A clear solution to "what's causing such a high bill?" Your query above will have you sorted within seconds.
- Per-version A/B testing on cost. Upgrading the 'agent_version' in a prompt version update will enable you to compare cost-per-task between v6 and v7.
- Separation of failure modes. Provider unavailability, budget exceedance, and loop guard are each represented as their own 'cost.outcome'.
- Vendor independence. Your infrastructure uses one gateway, through which all providers are accessed, instrumented via OpenTelemetry.
What This Doesn't Fix
- Semantic caching (which reduces costs by reusing near-duplicate prompts). This should live alongside the rest of the instrumentation, although it requires its own design.
- Prompt-version A/B for quality, which requires evaluations against ground truth outside of the system — it's not enough to attribute cost per prompt.
- Cross-region fallback. The architecture outlined here has a single point of failure in the Redis budget store. Actual implementations may opt for Redis Cluster or regional brokers for each data plane.
The Takeaway
What you learn from the real-world incidents that motivate this architecture is that your agents will spend whatever budget they can, as long as there's nothing stopping them, and whatever attribution they like best. Both of these are choices in system architecture, not monitoring capabilities.
Opinions expressed by DZone contributors are their own.
Comments