The Aggregate Reference Problem
How can one aggregate reference another aggregate’s data while preserving strict ownership boundaries? That is the aggregate reference problem.
Join the DZone community and get the full member experience.
Join For FreeDomain-driven design requires that each aggregate be owned by a single bounded context. Only the owning context may modify it, enforce its invariants, or expose its behavior. However, aggregates rarely exist in isolation. Consider a course management system divided into separate bounded contexts:
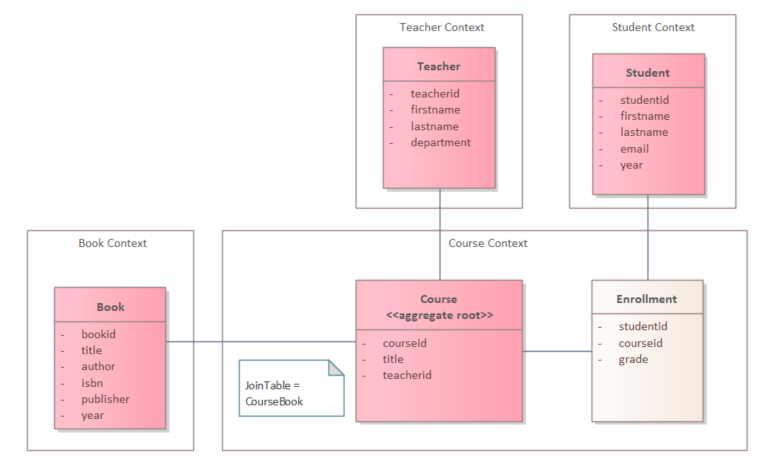
- Course context owns Course and Enrollment.
- Student context owns Student.
Enrollment must reference a Student.
From a database perspective, this is simple: a foreign key from enrollment.student_id to student.id. From a domain perspective, it is not. The moment Enrollment needs more than just the identifier, for example, the student's name for query projection or display, it must access data owned by another context.
This creates a structural problem:
- Enrollment must reference Student for relational integrity.
- Enrollment must not own or mutate Student.
- Course context must not depend on Student contexts internal implementation.
- Yet relational queries across these entities must remain efficient.
The difficulty is not technical in isolation. JPA can join tables. The database can enforce foreign keys. The difficulty is architectural: How can one aggregate reference another aggregate’s data while preserving strict ownership boundaries? That is the aggregate reference problem.
The Guest Entity Pattern
The aggregate reference problem assumes a shared relational database within a single operational boundary. It applies to systems where bounded contexts are separated by ownership and write control, not by physical database instances. In such environments, relational integrity and transactional consistency remain desirable architectural properties. Within that constraint, there is a structural option that is often overlooked:
Two different entity classes can map to the same database table.
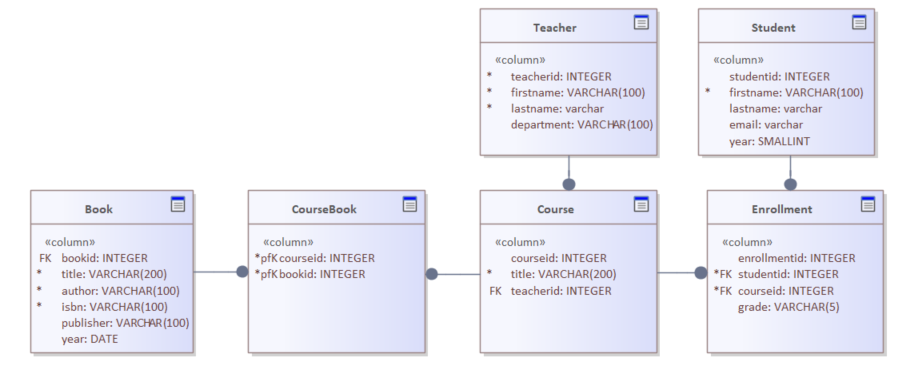
Java Persistence API (JPA) does not require a one-to-one relationship between Java entity classes and physical tables. Multiple entity classes may map to the same table, as long as they are defined in separate bounded contexts or persistence units.
This capability can be used to preserve aggregate ownership boundaries while maintaining relational integrity.
Core Idea
The owning bounded context defines the full entity. For example Student context defines:
@Entity
@Table(name = "student")
public class Student {
@Id
private Long id;
private String firstName;
private String lastName;
private String email;
// getters and setters
}This entity represents the student table completely within its owning context. The course context does not use this class. Instead, it defines its own entity that maps to the same table:
@Entity
@Table(name = "student")
public class StudentGuest {
@Id
private Long id;
private String firstName;
private String lastName;
protected StudentGuest() {}
public Long getId() { return id; }
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
// no setters
}Both classes map to the same physical table. The difference is not in the database; the difference is in perspective.
The Read-Only Perspective
StudentGuest represents the student table as seen from another bounded context. It is not a partial implementation of Student, it is not a DTO, it is not a copy. It is a read-only projection of externally owned data.
This is enforced structurally:
- No setters
- No domain behavior
- No navigation to other external entities
Course context can:
- Reference a student
- Read selected attributes
- Use those attributes in queries
Course context cannot:
- Modify student data
- Extend the student model
- Traverse deeper into the student’s object graph
The type encodes ownership boundaries.
Referencing the Guest
Enrollment references StudentGuest using a standard JPA association:
@Entity
@Table(name = "enrollment")
public class Enrollment {
@Id
private Long id;
@ManyToOne(optional = false, fetch = FetchType.LAZY)
@JoinColumn(name = "student_id", nullable = false)
private StudentGuest student;
// other fields
}From the database perspective:
- enrollment.student_id is a foreign key to student.id
- Referential integrity is enforced normally
From the architectural perspective:
- Course context has relational access
- Student context retains full ownership
- No cross-context mutation is possible
Why This Works
This structure provides four key properties:
- Single source of truth: Both entities map to the same rows; no duplication exists.
- Database-level integrity: Foreign key constraints remain intact.
- Compile-time boundary enforcement: The absence of mutating methods makes cross-context writes explicit rather than accidental.
- Efficient relational queries: JPA joins function normally.
Example:
SELECT e
FROM Enrollment e
JOIN FETCH e.student
WHERE e.student.lastName = :nameThis produces a standard SQL join against a single database with no service calls, no replication, and no synchronization.
Structural Consequence
Ownership is encoded in the type system. Student represents the entity within its owning context, and StudentGuest represents the same table viewed from outside that context.
The distinction is not runtime-based; it is structural and enforced at compile time, and this is the defining characteristic of the Guest Entity pattern.
Aggregates, Invariants, and Ownership
In DDD, aggregate boundaries exist to protect invariants.
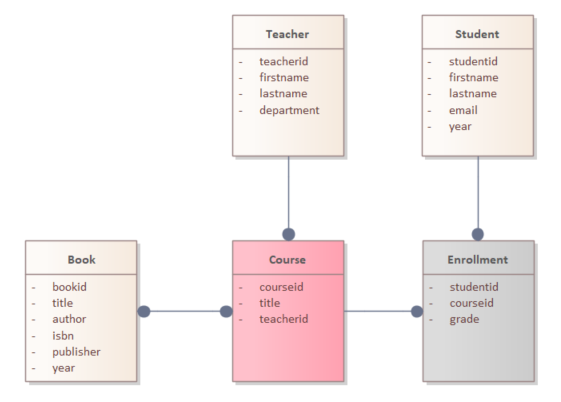
An invariant is a business rule that must hold true within a transactional boundary.
Each aggregate root is responsible for enforcing the invariants of everything inside its boundary.
In this example:
- Course is the aggregate root.
- Enrollment belongs to the Course aggregate.
- Book, Teacher and Student are the root of a different aggregate in another bounded context.
This means:
- All enrollment rules are enforced by the Course aggregate.
- All student rules are enforced by the Student aggregate.
- Only the owning aggregate root may modify its data.
Ownership is therefore about write control.
- Course context owns the Course aggregate.
- Student context owns the Student aggregate.
Guest Entities preserve this structure.
Course context may reference StudentGuest to read student data needed for enrollment decisions. But it cannot modify Student state. All student changes must go through the Student context, where the Student aggregate protects its invariants.
The database enforces referential integrity between Course and Student. Each aggregate enforces its own business integrity.
The Guest Entity pattern allows relational references without collapsing aggregate ownership.
Aggregates as the Behavioral Boundary
The Guest Entity pattern assumes a clear separation between aggregate logic and persistence mapping.
In this architecture:
- The aggregate root defines behavior and enforces invariants.
- Entity classes represent database structure.
- Lifecycle operations are orchestrated explicitly by the aggregate root.
- No business rules are embedded in JPA annotations or entity setters.
This distinction matters.
If entity classes contain domain logic or enforce invariants directly, duplicating them across contexts would create semantic conflicts.
In the Guest pattern, entities are structural persistence representations. The aggregate root remains the only behavioral boundary.
Because of this:
- A StudentGuest does not compete with Student.
- It does not represent a second aggregate.
- It is a read-only structural projection used for relational reference.
The aggregate model remains singular and authoritative within its bounded context.
Conclusion
The Guest Entity pattern is not a universal architectural rule. It only makes sense within a shared relational database, where multiple bounded contexts map to the same physical tables. It does not attempt to solve distributed data management, geographic scaling, or independent database ownership. In those environments, other patterns are more appropriate.
What it does address is a more specific tension: how to preserve aggregate ownership and invariant protection while still benefiting from relational integrity and efficient joins.
A shared database does not automatically collapse bounded contexts. What collapses them is uncontrolled write access, shared mutable entity models, and implicit lifecycle behavior. By separating the full entity in the owning context from a read-only projection in non-owning contexts, the write path remains singular and explicit. The database enforces referential integrity, while aggregates enforce business integrity.
No data is duplicated. No remote lookups are required for relational queries. No cascade rules silently cross boundaries. Cross-context interactions remain explicit application-level decisions rather than ORM side effects.
The core insight is simple: relational references and aggregate ownership are not the same thing. A foreign key does not imply shared responsibility. Ownership is defined by who is allowed to change state.
The aggregate reference problem is ultimately about write control. The Guest Entity pattern resolves it by making that control structural and visible in the type system, without abandoning the strengths of a relational database.
Opinions expressed by DZone contributors are their own.
Comments