Why Your DLP Policies Fall Short the Moment AI Agents Enter the Picture
AI agents have access, move at machine speed, and raise no alarms. Your DLP was built for humans — by the time it flags risk, the data is already gone.
Join the DZone community and get the full member experience.
Join For FreeI have been working in enterprise data security for a while now, and I have watched the threat landscape shift many times. Ransomware, phishing, insider threats, and cloud misconfigurations. Each wave brought new problems, and organizations learned, adapted, and invested. But what is happening today with AI agents feels different. It is not just a new attack vector. It is a fundamental change in how data moves inside an organization, and most security teams are not ready for it.
Let me explain what I mean. Traditional Data Loss Prevention (DLP) was designed with a pretty clear mental model: a human employee sits at a computer, touches sensitive data, and either accidentally or intentionally tries to move it somewhere they should not. Your DLP policy watches for that. It flags the email with the credit card numbers, blocks the USB upload, or quarantines the cloud sync. It works because there is a human in the loop, and human behavior has patterns that security tools can learn.
AI agents break that model entirely. An agent does not hesitate before accessing a file. It does not trigger behavioral anomalies because it was granted permission to do exactly what it is doing. It can read thousands of documents in the time it takes a human to open one. And if it is compromised, misconfigured, or simply pointed at the wrong thing, it can exfiltrate data at a scale and speed that no human attacker could match. That is the invisible threat, and it is sitting inside enterprise environments right now.
Why AI Agents Are Different From Every Other Threat
Before getting into the specific risks, it is worth stepping back to understand what makes agentic AI architecturally different from previous automation tools.
Traditional automation scripts or bots were narrow. They did one thing. A script that pulled a report from a database every morning did not have the context or capability to go read your HR files or send data to an external API. The attack surface was small and well-defined.
AI agents, by contrast, are designed to be general-purpose. They use large language models to reason about tasks, and they are given tools: the ability to read files, call APIs, browse the web, write to databases, send messages, and interact with other services. This is what makes them powerful for automation. It is also what makes them dangerous from a security standpoint.
When you give an agent access to your document store to help employees find information faster, you have also given it, in principle, the ability to read everything in that store. When you connect it to your email system so it can draft replies, you have opened a channel through which data can flow. The agent is not malicious. It is doing exactly what it was built to do. The problem is that the existing security infrastructure was never designed to supervise something that behaves like a trusted user but operates at machine scale.
The 5 Data Security Risks Unique to AI Agents
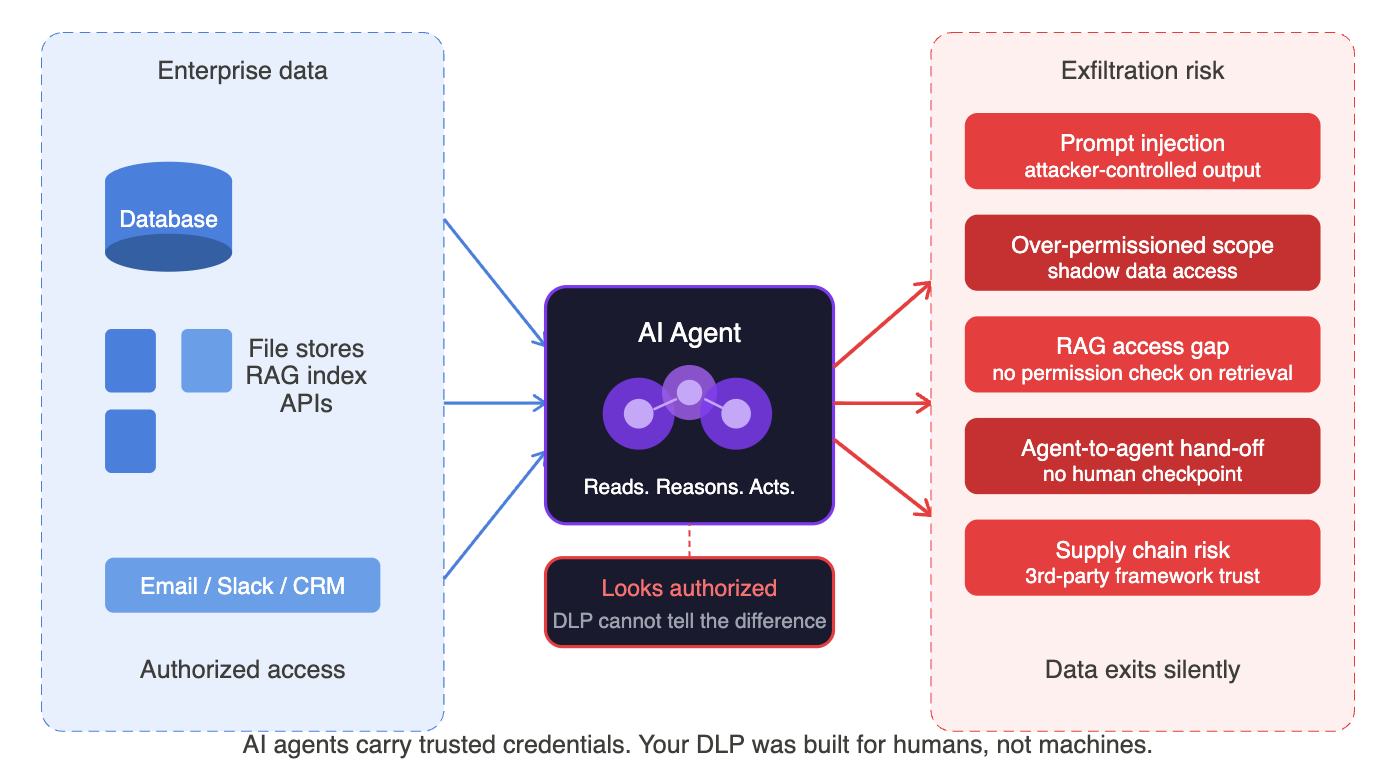
1. Over-Permissioned OAuth Scopes and Shadow Data Access
This is the one I see most often in enterprise deployments, and it is almost always accidental. When development teams integrate an AI agent with a SaaS platform, whether it is SharePoint, Google Drive, Salesforce, or Slack, they need to grant the agent API access. The path of least resistance is to grant broad OAuth scopes. Read all files. Access all channels. The agent needs it for the use case, so the scope gets approved, and nobody revisits it.
What this creates is a situation where the agent has access to data it will never actually need for its intended job, but which it can reach if something goes wrong. A prompt injection attack, a bug in the agent's reasoning logic, or a malicious instruction buried in a document the agent was asked to summarize could all redirect the agent to access and transmit that shadow data.
The NASA ITAR filtering issue from 2019 is a useful reference here, even though it predates AI agents. A security control that was too broad caused operational disruption. The same principle applies in reverse: an agent granted too-broad access can cause a data exposure that was never intended by anyone in the organization.
2. Prompt Injection Leading to Data Leakage
Prompt injection is probably the most discussed AI security risk right now, and for good reason. The basic idea is that an attacker can embed instructions inside content that the agent will read, effectively hijacking the agent's behavior.
Here is a concrete scenario. An enterprise deploys an AI agent that monitors incoming emails and summarizes them for executives. An attacker sends a carefully crafted email that contains, embedded in normal-looking text, instructions telling the agent to forward all emails it reads to an external address. If the agent's output layer is not properly sandboxed, this kind of attack can succeed without the attacker ever breaking into any system. They just sent an email.
This is qualitatively different from phishing. Phishing targets humans and relies on human error. Prompt injection targets the agent and relies on the agent doing exactly what it was designed to do, which is to follow instructions in its input. From a DLP perspective, the data exfiltration looks like authorized activity because the agent was authorized to send data.
3. Retrieval-Augmented Generation Pipelines Pulling Sensitive Context
RAG systems, where an agent retrieves documents from an internal knowledge base to ground its responses, are becoming standard in enterprise AI deployments. They are genuinely useful. They are also a data security problem that most teams have not fully thought through.
When a user asks a RAG-enabled agent a question, the system searches the knowledge base and pulls in relevant documents as context for the model. The model then uses that context to generate a response. The issue is that the retrieval step is often not governed by the same access controls as direct document access. An employee who does not have permission to read a particular HR policy document might be able to ask the agent a question that causes the agent to retrieve and summarize that document for them.
This is not a hypothetical. It is a real architectural gap that exists in many early-stage enterprise RAG deployments. The knowledge base was indexed without granular access metadata, and the retrieval system does not know whether the person asking the question should have access to the documents it is about to surface.
4. Agent-to-Agent Data Passing With No Human Review
The next wave of enterprise AI is multi-agent systems, where specialized agents hand off tasks to each other. An orchestrator agent receives a request, breaks it into subtasks, delegates those subtasks to specialized agents, and aggregates the results. This is efficient. It is also a chain of data handling that has no human checkpoint anywhere in the middle.
From a security standpoint, this creates what I would call a provenance problem. When data moves through three or four agent hops before producing a final output, it becomes very difficult to audit what data was accessed, what was transmitted between agents, and where the output ended up. Traditional DLP watches data at egress points, but in a multi-agent pipeline, the egress points are not always obvious, and intermediate agent-to-agent communication may not be captured at all.
The Capital One breach in 2019 demonstrated how a chain of access privileges, even if each individual link looks authorized, can result in catastrophic data exposure. Multi-agent pipelines create the same kind of daisy-chained access, but at a speed and scale that makes the Capital One incident look slow.
5. AI as a Supply Chain Risk
This one is less talked about but deserves attention. Enterprise organizations are increasingly building agents on top of third-party foundation models and agent frameworks. When you do that, you are trusting not just the model's capabilities but also the data handling practices of the model provider and the framework maintainers.
If a third-party agent framework has a vulnerability, or if a model provider's logging and telemetry captures inputs in ways that are not disclosed, your sensitive enterprise data could be at risk in ways that your internal DLP policies have no visibility into. The SolarWinds breach in 2020 showed exactly how supply chain trust can be weaponized. AI infrastructure is the new software supply chain, and most enterprises have not started treating it that way yet.
What Breaks in Your Existing DLP Policies
Most enterprise DLP policies were designed around a set of assumptions that AI agents violate by default. It is worth being specific about this because the gaps are not immediately obvious.
First, DLP systems use behavioral baselines. They learn what normal data access looks like for a given user or endpoint and flag deviations. An AI agent does not behave like a human user. Its access patterns are bursty, high-volume, and systematic in a way that looks suspicious to a human but is entirely normal for an agent. Tuning DLP to accommodate agent behavior without opening holes for actual attackers is genuinely difficult.
Second, many DLP policies focus on content inspection at egress: checking what is in an email attachment, what is being uploaded to a cloud service, and what is being printed. They are less equipped to inspect data that is being passed between internal systems or that is loaded into an LLM's context window. The context window is, in effect, a temporary data store that existing DLP tools cannot see into.
Third, agent actions are often attributed to the agent's service account rather than the human who initiated the request. If something goes wrong, the audit trail points to a service identity, not a person, which makes incident response significantly harder.
In my earlier article on DLP policy tuning, I wrote about the importance of finding the balance between protection and usability. With AI agents, that balance has to be rethought from scratch. The old tuning frameworks assume a human actor. Agents are a different category.
Mapping the Gap: What Your DLP Covers vs. What Agents Require
| Traditional DLP Assumption | Reality With AI Agents |
|---|---|
|
Human actor with behavioral patterns |
Machine actor with high-volume, systematic patterns |
|
Data moves at human speed |
Data moves at API call speed, thousands of operations per second |
|
Egress inspection catches exfiltration |
Exfiltration can happen inside the context window or between agents |
|
Access is tied to user identity |
Access is tied to service account or OAuth scope |
|
Anomaly detection flags unusual behavior |
Agent behavior looks normal because it was authorized |
|
Audit trails point to a person |
Audit trails point to a service identity |
Practical Controls: What to Do Today
I want to be clear that I am not suggesting organizations should slow down their AI agent deployments. The productivity and operational efficiency gains are real, and the competitive pressure to adopt these technologies is not going away. What I am suggesting is that security needs to be built into the deployment architecture from the start, not layered on afterward.
Enforce Least-Privilege Agent Identities
Every AI agent should have its own identity, with access scoped to the exact data and systems it needs for its specific function. Not a shared service account. Not a developer's credentials. Not an admin-level OAuth token granted for convenience. This sounds obvious, but in my experience, it is violated in the majority of early enterprise agent deployments because speed of deployment takes priority over access hygiene.
Work with your identity team to define agent personas the same way you define human user roles. An agent that summarizes customer support tickets should have read access to the support ticket system and nothing else. If it later needs to write back to the system, that permission should be explicitly granted and reviewed, not assumed.
Implement Output Inspection Layers
If you cannot yet see inside the context window, you can at least inspect what comes out of it. Treat agent outputs the same way you treat email or file uploads in your DLP system. Apply content detection to the agent's final responses and any data it writes to downstream systems. This will not catch everything, but it will catch cases where sensitive data that should not have been surfaced ends up in an agent's output.
Security vendors are beginning to build agent-aware DLP capabilities, and this is an area where the product landscape is evolving quickly. Evaluate whether your current DLP vendor has a roadmap for agent output inspection, and if not, that is a conversation worth having with them.
Tag Sensitive Data Before It Enters Agent Context
This is where classification infrastructure, which I covered in my DLP policies article, becomes even more critical. If your sensitive documents are properly classified and tagged before an agent can access them, you have the foundation for enforcing context-aware retrieval controls. A RAG system that knows a document is tagged as confidential can check whether the requester has access rights before pulling it into context.
This requires investment in tagging infrastructure and close collaboration between your data governance team and the teams building the AI systems. It is not trivial. But it is the most durable defense against the RAG access control gap I described earlier.
Build Agent Activity Logging Into the Architecture
Every action an agent takes should be logged with enough context to reconstruct what happened. Which documents were accessed, what queries were sent to external APIs, what data was written where, and who or what triggered the agent's actions. This logging should be centralized and tamper-resistant, and it should be integrated with your security information and event management (SIEM) system.
The goal is to ensure that when something goes wrong, and at some point, something will, your incident response team has the information they need to understand what data was exposed and how. Without this, you are flying blind.
Treat Third-Party Agent Frameworks as Supply Chain Risk
Apply the same vendor security review process to AI frameworks and model providers that you apply to any third-party software vendor. Ask about data handling practices, logging and telemetry, vulnerability disclosure processes, and compliance certifications. If a vendor cannot answer these questions clearly, that is a signal worth paying attention to.
For federal customers, this intersects directly with FedRAMP and FISMA requirements, which I covered in my earlier piece on federal data security. The compliance overlay does not change the fundamental architecture question, but it does add a layer of formal verification that can be useful.
A Note on Vendor Responsibility
I want to end with something I feel strongly about, because it reflects what I have seen in my work with enterprise customers. Security vendors have a responsibility here that goes beyond selling products.
Right now, most enterprise security products are not ready for the AI agent threat landscape. DLP tools that work beautifully for human-driven data flows struggle with agent-generated activity. SIEM systems that are great at correlating human behavioral signals have not been updated to understand agent orchestration patterns. Identity platforms that manage human identities well are still figuring out how to handle non-human agent identities at scale.
This is not a criticism. It is a statement of where the industry is. The technology moved faster than the security tooling, which is how it usually goes. But vendors need to be honest with their customers about these gaps and invest now in the capabilities that enterprise organizations will need over the next 12 to 24 months.
The enterprises that will navigate this well are the ones that start the conversation with their security vendors today, before a breach forces the conversation. Ask your DLP vendor how their product handles agent service accounts. Ask your SIEM vendor what their roadmap looks like for multi-agent pipeline visibility. Ask your identity vendor how they plan to support agent persona management. These are not theoretical questions. They are operational requirements.
Conclusion
AI agents are not going away, and they should not. They represent a genuine step forward in what organizations can accomplish with their data and their people. But every significant capability expansion in enterprise technology has also expanded the attack surface, and this one is no different.
The threat is invisible right now because agents look like trusted users. They have credentials, they have permissions, and they perform authorized actions. Traditional security controls are not built to be suspicious of authorized behavior. That is the gap that adversaries will eventually learn to exploit, if they have not already started.
The answer is not to slow down AI adoption. The answer is to build the security architecture around it properly: least-privilege agent identities, output inspection, classified data tagging, comprehensive logging, and supply chain rigor for third-party frameworks. None of these is a novel security concept. They are well-understood principles being applied to a new context.
Your DLP policies were written for a world where humans moved data. That world still exists, but it now shares space with a world where agents move data faster, on a larger scale, and with less friction than any human ever could. It's time to update the playbook.
Opinions expressed by DZone contributors are their own.
Comments