AI Coding Agents Have Created a New Problem: The Validation Bottleneck
AI coding agents can refactor a microservice in seconds. So why are developers still spending half their day waiting to find out if their code actually works?
The hard part of software engineering has never been writing the code. It is defining the problem, exploring the solution space, planning an approach, and validating that the result actually works in a real system. Writing code is the mechanical middle step. Coding agents have made that middle step largely autonomous, which should free engineers to spend more time on the high-value work on either side of it.
And in some ways, it has. Agents accelerate exploration. They let developers prototype faster, try more approaches, and iterate on designs that would have taken days to stub out manually. But by increasing the speed of code generation, agents have also increased the volume of changes that need to be verified. Validation is not the high-value part of software engineering, but it is increasingly eating up more developer time than the exploration and problem-solving it was supposed to unlock.
For developers working in enterprise environments with dozens of interconnected services, this gap between generating code and validating it has become the defining frustration of the AI-assisted workflow.
Local Validation Only Gets You So Far
If you are building a standalone app or a simple API, coding agents deliver on the promise. You prompt, the agent writes, you run it locally, and the feedback is immediate. The loop is tight and satisfying.
This is not the case if you are a developer on an enterprise product team that owns one service in a mesh of 30. Your agent rewrites an endpoint handler in seconds. Great. But the service that calls your endpoint belongs to another team. The downstream consumer that reads your events is maintained by a third team. The schema contract sits in a shared registry that nobody wants to touch.
You cannot validate any of this locally. Your only option is to open a pull request, trigger a CI pipeline, wait for a shared staging slot, deploy, and then discover 25 minutes later that your change broke a downstream integration you did not even know about. The agent did its job perfectly. The system around it failed to provide the context the agent needed to do it well.
This is not a tooling inconvenience. It is a structural mismatch between how fast code is now produced and how slowly it is verified.
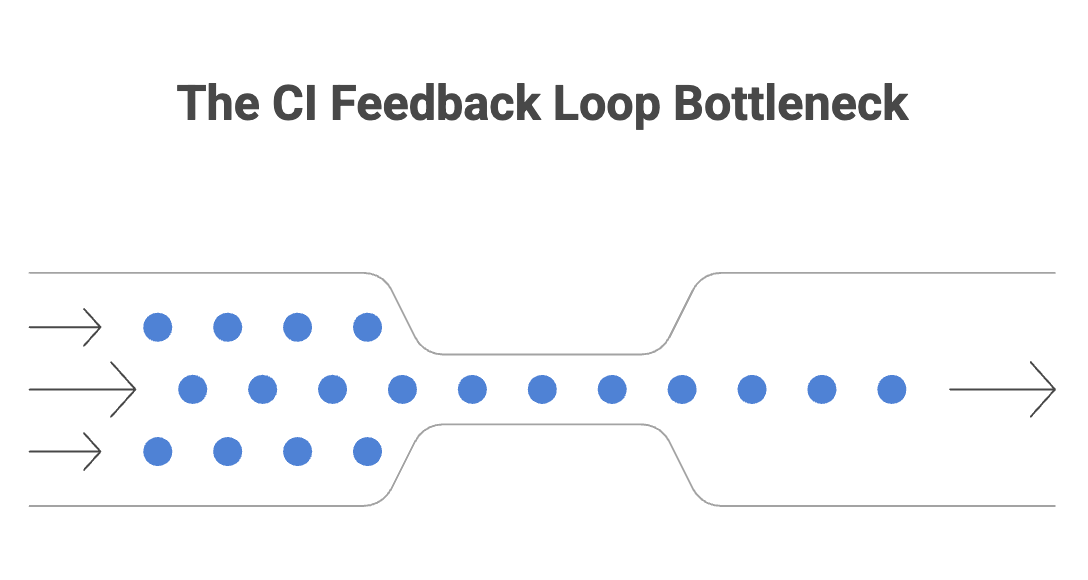
The Math That Breaks the Workflow
The numbers tell the story clearly. If each change requires 30 minutes of validation through a shared staging environment, and an agent-assisted developer is now generating five or six pull requests per day instead of two, the developer spends the majority of their working hours managing a deployment queue. They are not building software. They are babysitting a pipeline.
CI was designed for a world where developers produced a handful of changes per week. It was never architected to absorb the throughput that coding agents now enable. The pipeline becomes a bottleneck not because it is broken, but because it is operating exactly as designed in a context that has changed. Parallel agentic velocity collapses into a linear queue.
The frustration compounds in microservice architectures. A change that looks correct in isolation regularly fails at integration time because the agent has no visibility into how requests flow across service boundaries, how a schema modification affects a downstream consumer, or how a new endpoint behaves when invoked by the actual services that depend on it.
The developer ends up in a loop: the agent generates a PR, the developer interrogates it manually, deploys to staging, waits, finds a side effect that only surfaces under real infrastructure conditions, and starts over.
Validation Before Pull Request, Not After
The industry has talked about shifting left for years. AI coding agents are about to force the issue.
Validation cannot remain a post-commit activity. It needs to happen inside the development loop itself, before a pull request is opened, before CI is triggered, and before a developer context-switches away from the problem.
The goal is to collapse the feedback cycle from "write, commit, open PR, wait for CI, discover failure, fix" into something closer to "write, validate, present a verified result."
This requires two things: on-demand access to realistic infrastructure, and structured tooling that lets agents interact with that infrastructure programmatically.
Cheap, Disposable Environments Change the Calculus
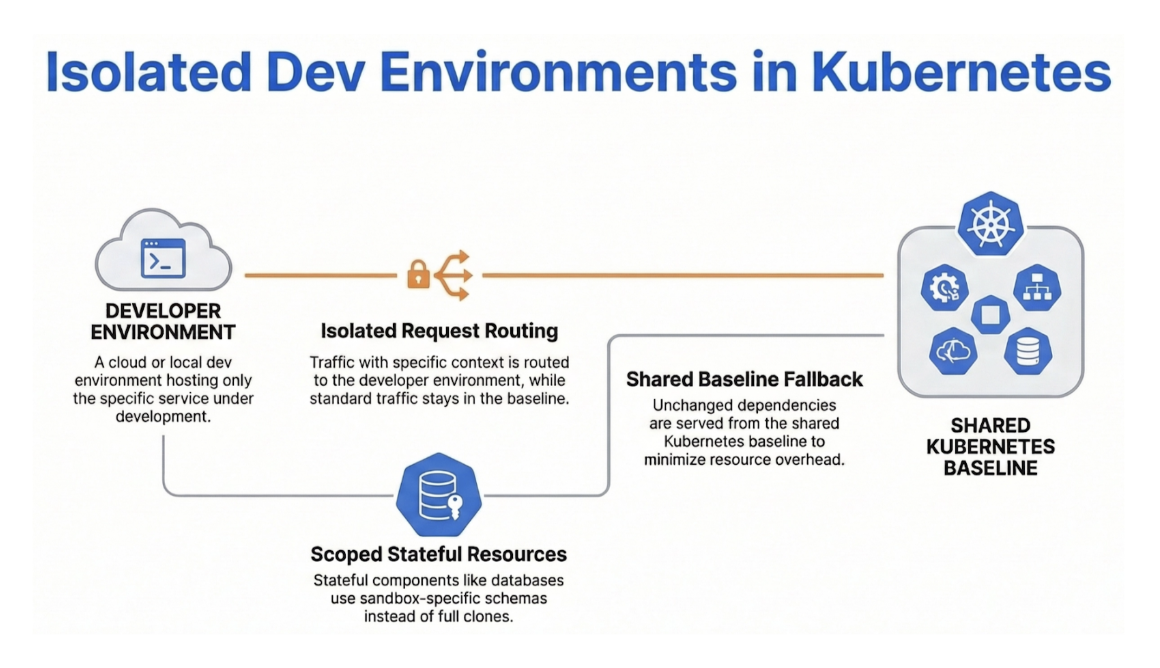
The first piece gives developers and their agents access to environments that reflect the real dependency graph without requiring a full copy of the staging cluster for every change.
This is where Kubernetes-native sandboxing comes in. By leveraging service meshes like Istio or Linkerd, it is possible to create lightweight, ephemeral environments that deploy only the modified service and route targeted requests through it, while all other traffic continues to flow through the shared baseline infrastructure. The cost per environment drops dramatically, and spin-up times shrink from minutes to seconds.
When environments are cheap and disposable, the economics change completely. Environments stop being a scarce resource that developers compete for and become a tool that agents can provision programmatically as part of their standard workflow. An agent can spin up a sandbox, test its change against live versions of every upstream and downstream dependency, and report the results before the developer ever opens a pull request.
Why Infrastructure Access Alone Is Not Enough
On-demand infrastructure is necessary but not sufficient. An agent that can spin up a sandbox still needs a structured way to exercise the code running inside it. And engineering organizations need assurance that agent-driven verification follows the same standards everywhere.
This represents an emerging responsibility for platform engineering teams. Today, they own CI, deployment, and observability. Tomorrow, they will also need to own a validation layer that developers and agents can invoke before code ever reaches a pull request.
What does that validation layer look like? In a distributed system, verifying a change is never a single assertion. It requires orchestrating multiple steps: provisioning infrastructure, sending traffic through the modified service, capturing the response, and comparing it against expected behavior.
The building blocks of this orchestration need three properties. They must produce repeatable results so teams can trust them. They must operate within boundaries that platform owners define. And they must snap together in different combinations so that each team can tailor validation to its own service topology without relying on a one-size-fits-all test suite.
The Solution: Composable Validation for Coding Agents
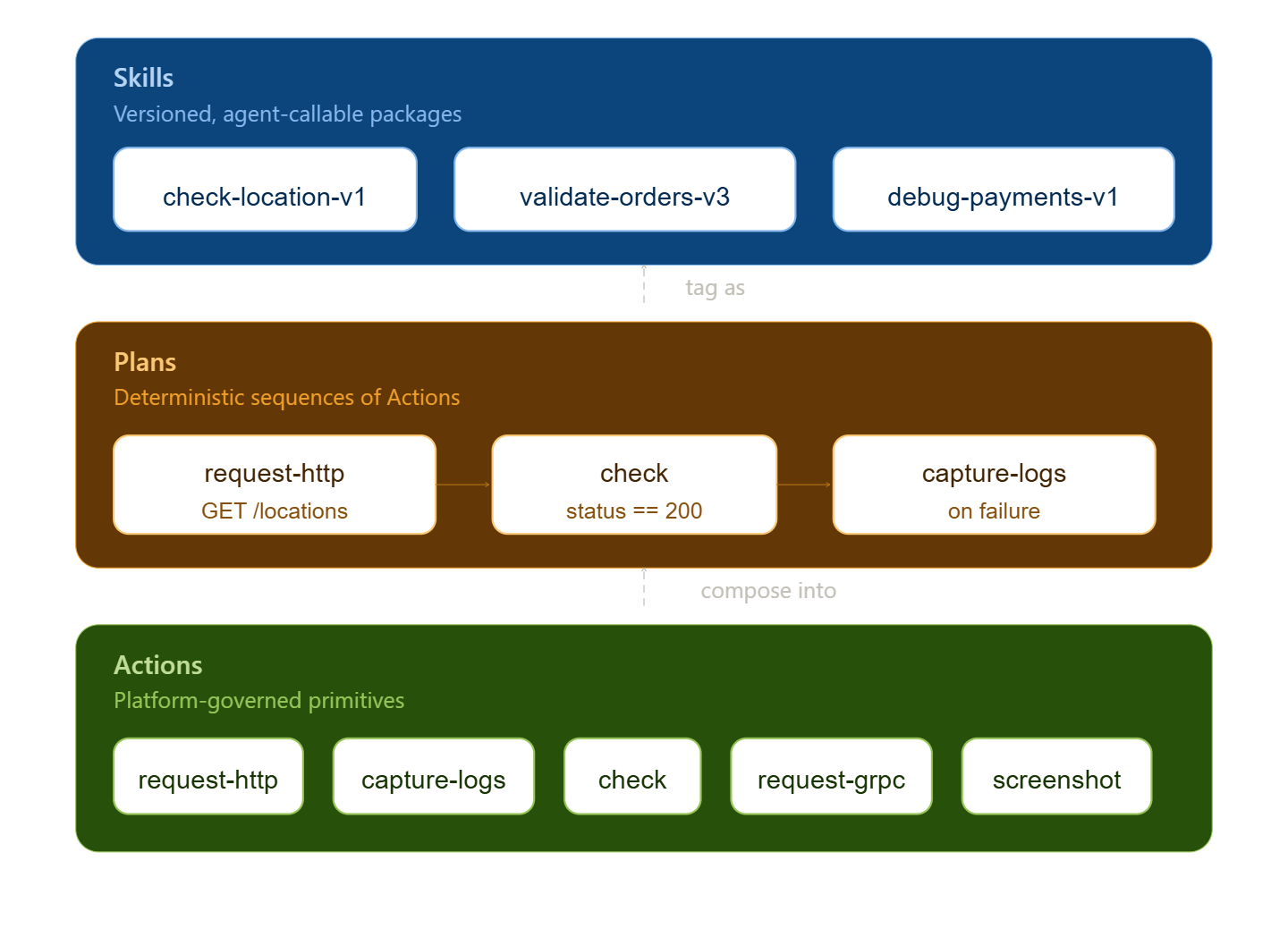
At Signadot, we have been building toward this vision with Signadot Skills. Skills layer a validation framework on top of our ephemeral sandbox infrastructure. The core concept is a library of platform-governed primitives called Actions. Each Action performs a single, well-defined operation: issuing an HTTP call to a sandboxed service, collecting log output, or checking a response payload against an expected format.
Platform teams control every Action individually, so compliance and security policies are baked into the primitives themselves rather than being applied as an afterthought. And because each Action returns a predictable result, developers and agents can chain them into custom verification workflows while the organization maintains a consistent standard for how validation is performed.
In practice, a developer or agent defines a plan: an ordered chain of Actions that exercises a specific behavior end-to-end. Once the plan is ready, it can be tagged with a version and surfaced directly inside the coding agent as a callable skill. From that point on, every time the agent modifies the relevant service, it can execute the plan against a live sandbox and surface the outcome before any human review begins.
The design gives agents enough freedom to self-verify while letting platform teams set the boundaries. We think striking that balance is a prerequisite for enterprises that want agentic development to work at scale.
What the End State Looks Like
For agent-assisted development to work at scale in cloud-native environments, an agent that modifies a service should be able to prove that the change works before a human ever looks at it. Instead of opening a pull request and hoping CI catches any issues, the agent hands the developer a verified result: evidence that the change was exercised against real dependencies, that integration contracts held, and that no downstream regressions appeared.
This does not replace CI. It means that by the time a change enters the CI pipeline, the most important signals have already been collected. Developers shift from waiting in queues to reviewing outcomes. The feedback cycle contracts from hours to minutes.
The promise of AI coding agents was never just faster code output. It was giving engineers more time for the work that actually matters: defining problems, exploring solutions, and making architectural decisions. Right now, the validation burden is clawing back that time. The teams that solve this problem will be the ones that actually realize the productivity gains everyone else is still waiting for.
Learn more about how Signadot's Skills framework works in our architecture blog.
Note: Featured image by Iwona Castiello d'Antonio on Unsplash
Check out the full Signadot article collection here.
Comments