AI Infrastructure Guide: Tools, Frameworks, and Architecture Flows
This guide covers AI infrastructure, from hardware acceleration and model serving to monitoring and security, with tools, patterns, and strategies proven in production.
Join the DZone community and get the full member experience.
Join For FreeBuilding robust AI infrastructure requires understanding both the theoretical foundations and practical implementation details across multiple layers of technology. This comprehensive guide provides the definitive resource for architecting, deploying, and managing AI systems at any scale — from experimental prototypes to enterprise-grade production deployments serving millions of users.
Modern AI applications demand sophisticated infrastructure that can handle the computational intensity of large language models, the complexity of multi-agent systems, and the real-time requirements of interactive applications. The challenge lies not just in selecting the right tools, but in understanding how they integrate across the entire technology stack to deliver reliable, scalable, and cost-effective solutions.
This guide covers every aspect of AI infrastructure, from hardware acceleration and model serving to monitoring and security, with detailed explanations of open-source tools, architectural patterns, and implementation strategies that have been proven in production environments.
This article is part of a series of articles about AI infrastructure. Read the previous article, which introduces you to the layers of AI infrastructure and explores the diverse infrastructure options and tools that are available for deploying and optimizing AI agents and large language models (LLMs).
Layer-by-Layer Infrastructure Analysis
1. Application Gateway Layer
The application gateway layer serves as the front door to your AI infrastructure, handling all external traffic and providing essential cross-cutting concerns like security, rate limiting, and load balancing. This layer is critical for production deployments because it provides the first line of defense against malicious traffic while ensuring optimal distribution of legitimate requests.
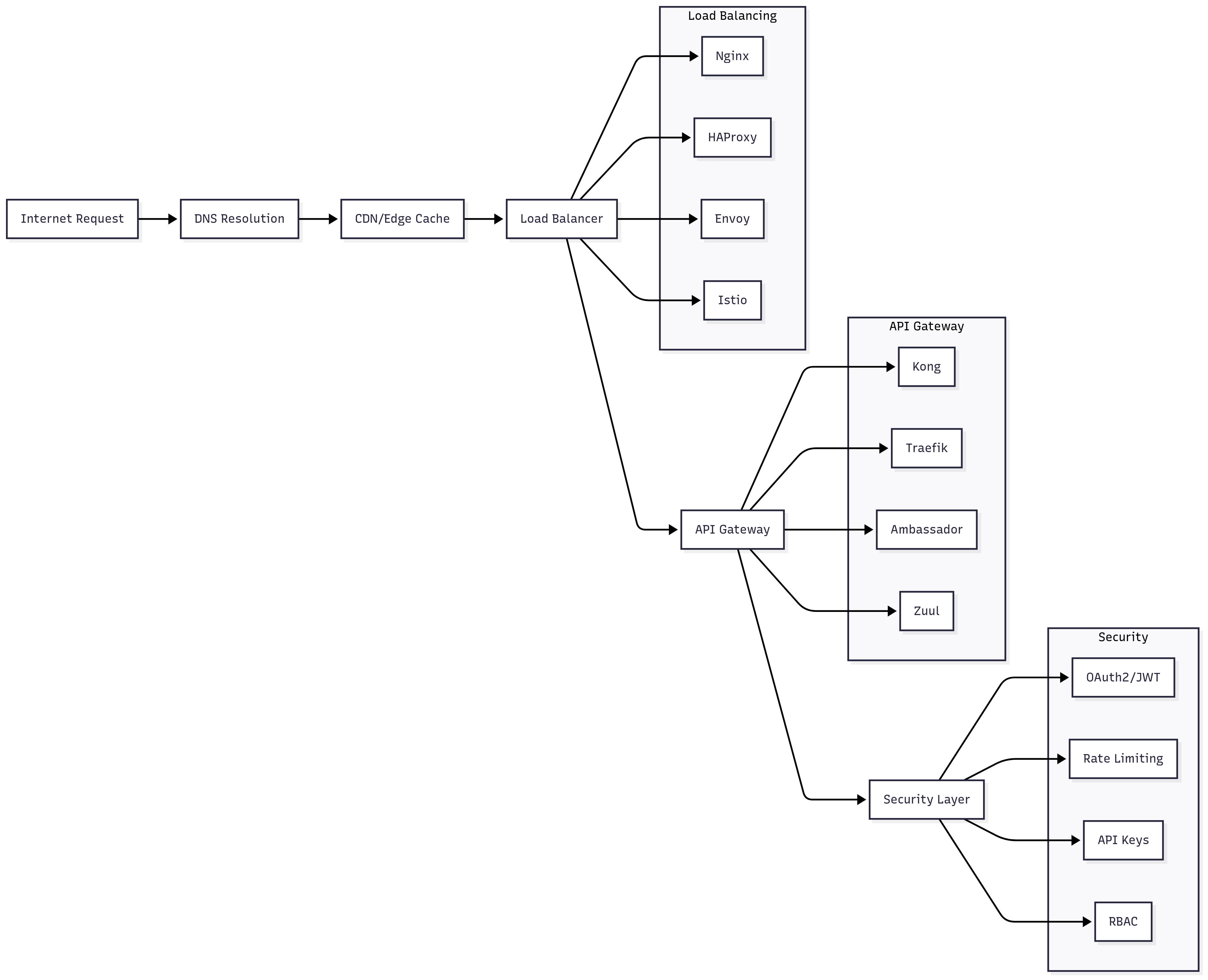
Load Balancing Strategies for AI Workloads
Nginx remains the most popular choice for load balancing due to its proven stability, extensive documentation, and powerful configuration options. For AI workloads, Nginx excels at handling the diverse traffic patterns typical of AI applications, from short API calls to long-running streaming responses. Its upstream module supports sophisticated health checks that can detect when AI services are overloaded or experiencing high inference latency.
Configuration example for AI model serving:
upstream ai_models {
server model-server-1:8000 weight=3 max_fails=3 fail_timeout=30s;
server model-server-2:8000 weight=3 max_fails=3 fail_timeout=30s;
server model-server-3:8000 weight=2 max_fails=3 fail_timeout=30s;
}
server {
location /v1/chat/completions {
proxy_pass http://ai_models;
proxy_read_timeout 300s; # Long timeout for AI inference
proxy_buffering off; # Enable streaming responses
}
}HAProxy provides advanced features particularly useful for AI applications, including connection pooling, circuit breakers, and sophisticated health checks that can monitor AI-specific metrics like inference latency and queue depth. Its statistics interface provides real-time visibility into traffic distribution and backend health.
Envoy has gained popularity in cloud-native environments due to its rich feature set and integration with service mesh technologies. For AI applications, Envoy's dynamic configuration capabilities are particularly valuable, allowing for real-time adjustments to routing rules based on model performance or capacity changes.
API Gateway Selection and Configuration
Kong stands out for AI applications due to its extensive plugin ecosystem, including plugins specifically designed for AI workloads such as rate limiting based on token count, request/response transformation for different model APIs, and comprehensive analytics for AI metrics. Kong's declarative configuration approach makes it easy to manage complex routing rules and security policies across multiple AI services.
Traefik excels in containerized environments with its automatic service discovery capabilities. For AI applications deployed in Kubernetes, Traefik can automatically discover new model services and configure routing rules based on labels and annotations, significantly reducing operational overhead.
Key considerations for AI API gateways include:
- Token-aware rate limiting: Traditional rate limiting based on requests per second may not be appropriate for AI applications, where computational cost varies dramatically based on request complexity
- Streaming response support: Many AI applications require streaming responses, which need special handling at the gateway level
- Model versioning: API gateways should support sophisticated routing rules that can direct traffic to different model versions based on headers, user segments, or experimentation frameworks
2. Service Orchestration Layer
The service orchestration layer manages the complex lifecycle of AI services, handling everything from initial deployment to auto-scaling and rolling updates. This layer is particularly crucial for AI applications because of their unique characteristics: high resource requirements, long startup times, and dynamic scaling needs based on inference demand rather than traditional web traffic patterns.
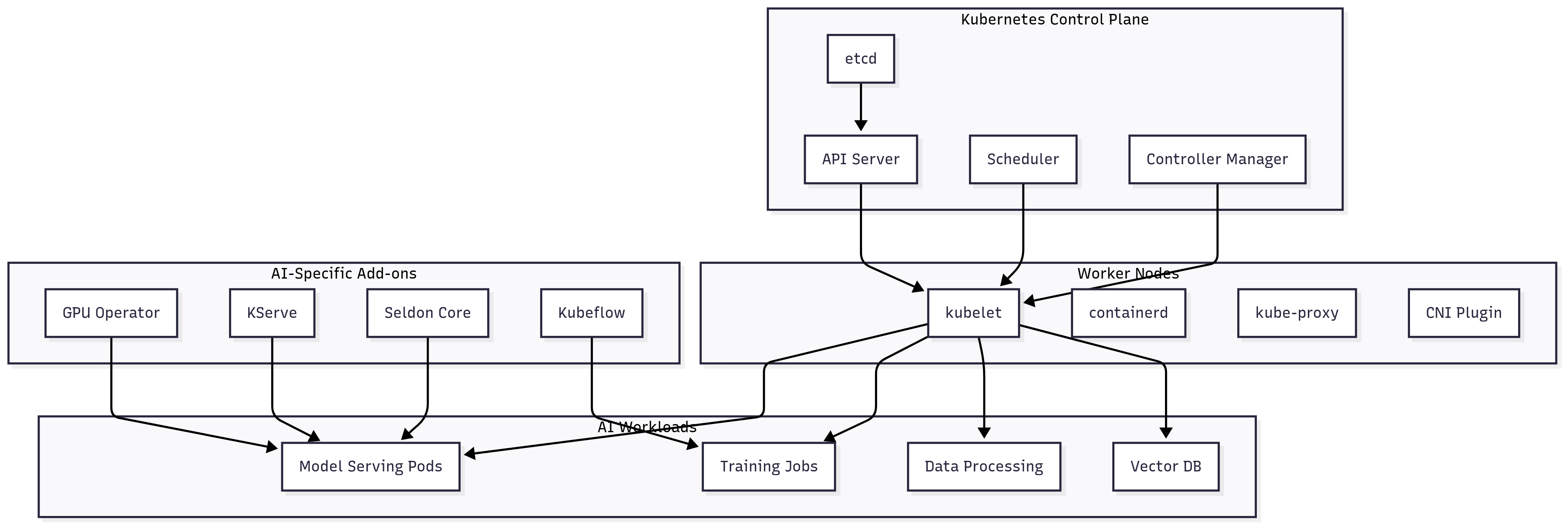
Kubernetes for AI Workloads
Kubernetes has become the de facto standard for orchestrating AI workloads due to its powerful scheduling capabilities, extensive ecosystem, and strong community support. However, AI workloads present unique challenges that require careful consideration of resource management, scheduling policies, and operational practices.
GPU scheduling and management: The NVIDIA GPU Operator simplifies GPU management in Kubernetes clusters by automatically installing and managing the necessary drivers, runtime, and monitoring tools. It supports advanced features like GPU sharing, where multiple containers can share a single GPU, which is particularly useful for inference workloads that don't fully utilize GPU capacity.
Key configuration considerations:
apiVersion: v1
kind: Pod
spec:
containers:
- name: ai-inference
image: ai-model:latest
resources:
limits:
nvidia.com/gpu: 1
memory: 32Gi
requests:
nvidia.com/gpu: 1
memory: 16Gi
env:
- name: CUDA_VISIBLE_DEVICES
value: "0"Resource management: AI workloads require sophisticated resource management strategies that go beyond simple CPU and memory limits. Considerations include:
- Memory overcommitment: AI models often have predictable memory usage patterns, allowing for controlled overcommitment
- Startup time optimization: Large models can take several minutes to load, requiring strategies like model pre-loading and warm pools
- Affinity rules: Ensuring that related services (like model servers and vector databases) are co-located for optimal performance
Advanced Orchestration Patterns
KServe provides a Kubernetes-native platform for deploying and managing machine learning models. It supports advanced features like canary deployments, A/B testing, and automatic scaling based on inference metrics. KServe's abstraction layer allows data scientists to deploy models without deep Kubernetes knowledge while providing platform engineers with fine-grained control over resource allocation and scaling policies.
Seldon Core offers enterprise-grade model serving capabilities with support for complex inference graphs, explainability, and drift detection. Its architecture allows for sophisticated deployments where multiple models can be chained together, with routing decisions made based on real-time performance metrics or business rules.
3. AI Service Layer Architecture
The AI service layer represents the heart of your AI infrastructure, where the actual intelligence resides. This layer encompasses model serving engines, agent orchestration systems, and tool integration frameworks that enable complex AI workflows. The architecture of this layer directly impacts the user experience, system performance, and operational complexity of your AI applications.
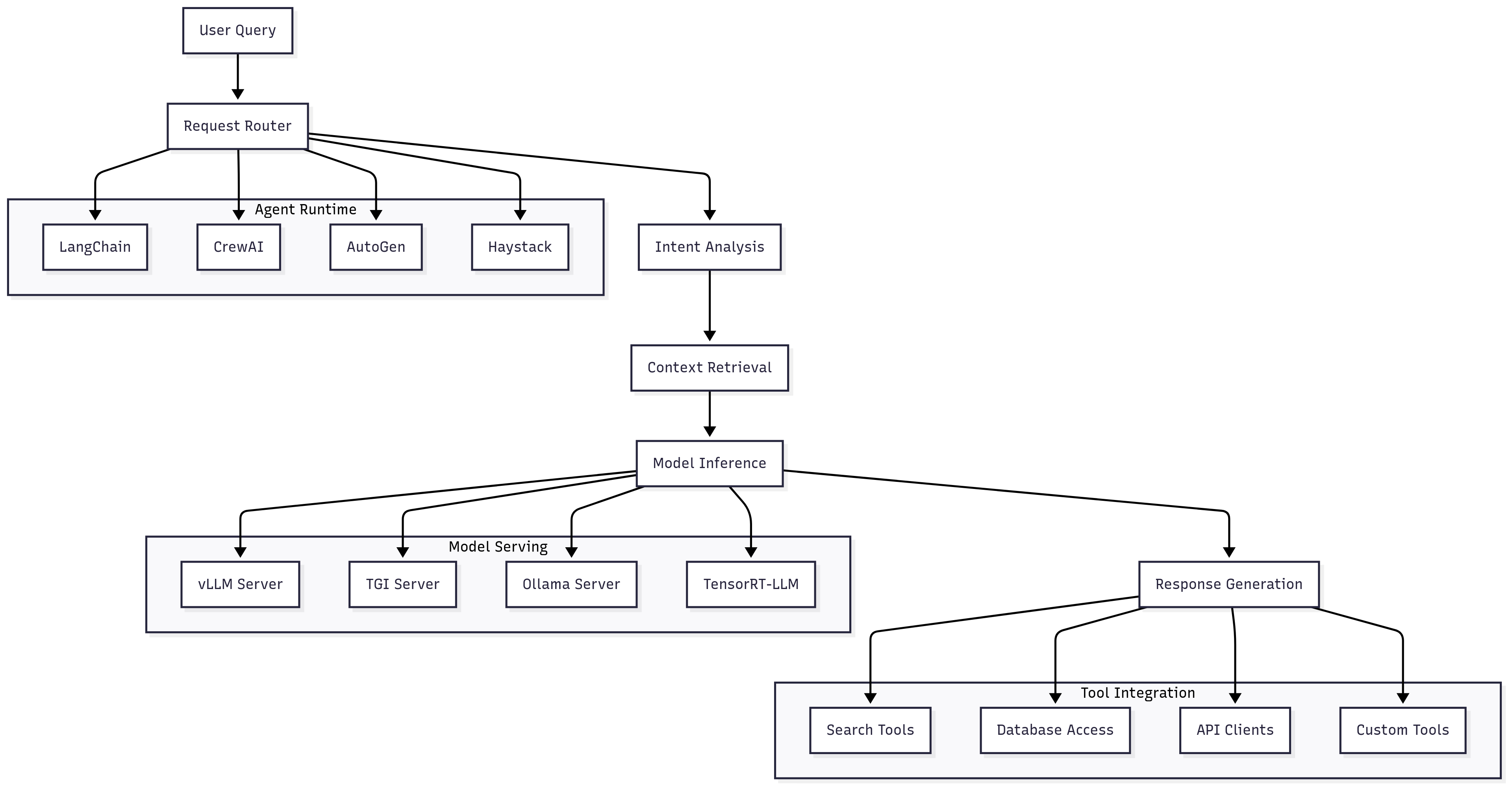
Model Serving Engines Deep Dive
vLLM has emerged as the premier choice for high-throughput LLM inference due to its innovative PagedAttention algorithm and continuous batching capabilities. PagedAttention eliminates memory fragmentation by storing attention keys and values in non-contiguous memory blocks, similar to how operating systems manage virtual memory. This approach can reduce memory usage by up to 50% compared to traditional methods, allowing for higher batch sizes and better GPU utilization.
The continuous batching feature processes requests as they arrive rather than waiting for fixed batch sizes, significantly reducing average latency while maintaining high throughput. For production deployments, vLLM supports tensor parallelism across multiple GPUs, enabling the serving of models too large for single GPU memory.
Configuration example:
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-2-70b-chat-hf",
tensor_parallel_size=4, # Use 4 GPUs
max_model_len=4096,
gpu_memory_utilization=0.9
)
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95,
max_tokens=512
)Text generation inference (TGI) by Hugging Face provides production-ready serving with enterprise features like comprehensive monitoring, streaming responses, and OpenAI-compatible APIs. TGI excels in environments where operational simplicity and monitoring are priorities, offering built-in metrics, health checks, and integration with popular observability tools.
Ollama has gained popularity for edge deployments and development environments due to its simplicity and comprehensive model management capabilities. It automatically handles model downloading, quantization, and optimization, making it ideal for scenarios where ease of use trumps maximum performance.
Agent Orchestration Systems
LangChain provides the most comprehensive ecosystem for building AI agents, with extensive integrations for tools, data sources, and model providers. Its modular architecture allows developers to compose complex workflows from reusable components, while its extensive documentation and community support make it accessible to developers with varying levels of AI expertise.
Key LangChain components for production deployments:
- Chains: Pre-built workflows for common patterns like question-answering and summarization
- Agents: Systems that can reason about tool usage and plan multi-step workflows
- Memory: Persistent storage for conversation history and learned information
- Callbacks: Hooks for monitoring, logging, and custom business logic
CrewAI specializes in multi-agent scenarios where different AI agents collaborate to solve complex problems. Its role-based approach allows for sophisticated team dynamics where agents have specialized capabilities and can delegate tasks to each other. This is particularly valuable for enterprise applications that require complex workflows involving multiple domain experts.
AutoGen by Microsoft provides a framework for conversational AI systems where multiple agents can engage in back-and-forth conversations to solve problems. Its strength lies in scenarios requiring negotiation, debate, or collaborative problem-solving between different AI perspectives.
4. Complete Inference Flow With Tools Integration
Understanding the complete inference flow is crucial for optimizing performance, debugging issues, and designing robust AI systems. The flow encompasses everything from initial request validation to final response delivery, with multiple optimization opportunities at each stage.
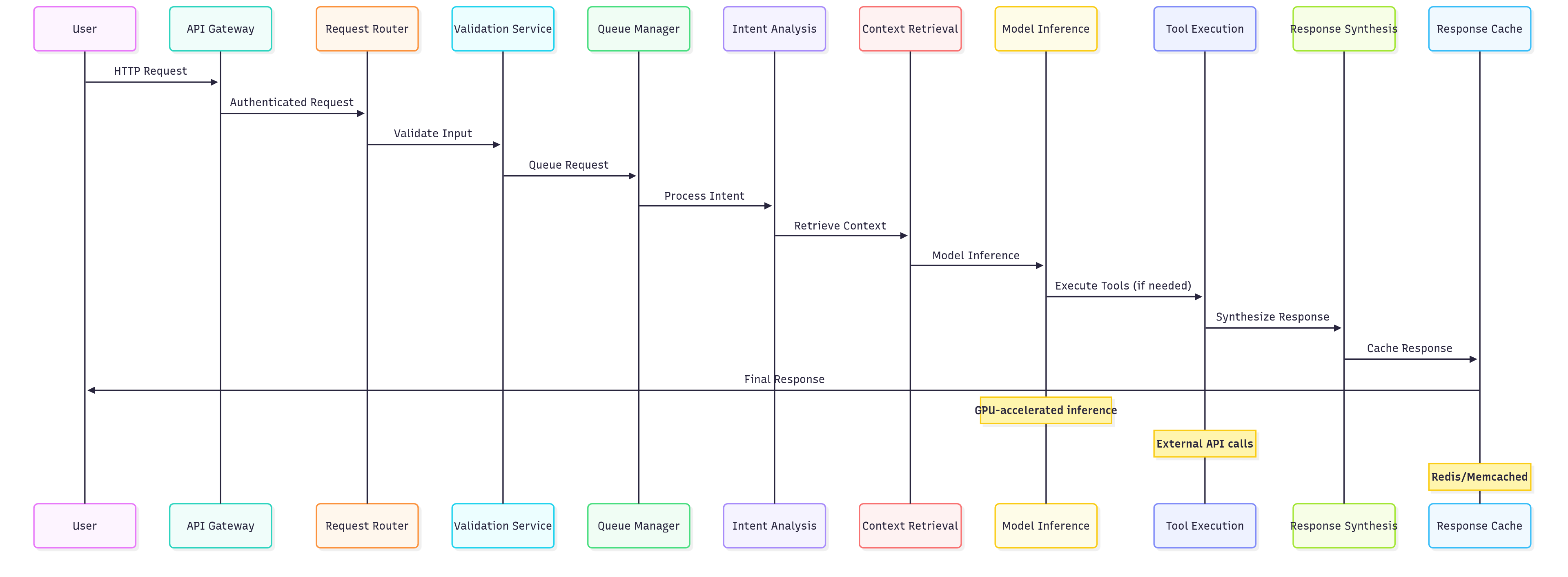
Request Processing Pipeline
The Input Validation stage is critical for both security and performance. For AI applications, validation goes beyond traditional web application concerns to include:
- Token count estimation: Preventing requests that would exceed model context limits
- Content safety: Screening for potentially harmful or inappropriate content
- Format validation: Ensuring requests conform to expected schemas
Pydantic provides excellent support for AI application validation with its powerful type system and validation rules:
from pydantic import BaseModel, Field, validator
from typing import List, Optional
class ChatRequest(BaseModel):
messages: List[dict] = Field(..., min_items=1, max_items=100)
max_tokens: Optional[int] = Field(512, gt=0, le=4096)
temperature: float = Field(0.7, ge=0.0, le=2.0)
@validator('messages')
def validate_messages(cls, v):
total_tokens = estimate_tokens(v)
if total_tokens > 8000:
raise ValueError('Total message tokens exceed limit')
return vContext Retrieval and RAG Implementation
Retrieval-augmented generation (RAG) has become essential for production AI applications, allowing models to access up-to-date information and domain-specific knowledge. The context retrieval stage involves several sophisticated operations:
Vector similarity search: Converting user queries into embeddings and finding semantically similar documents from a vector database. The choice of embedding model significantly impacts retrieval quality, with recent models like OpenAI's text-embedding-3 and open-source alternatives like BGE showing excellent performance.
Hybrid search: Combining vector similarity with traditional keyword search for improved recall. This approach is particularly effective for queries that contain specific terminology or proper nouns that might not be well-represented in vector embeddings.
Reranking: Using specialized models to reorder retrieved documents based on relevance to the specific query. Cross-encoder models like those from the sentence-transformers library can significantly improve retrieval quality at the cost of additional compute overhead.
5. Agent Architecture Flow With Infrastructure
AI agents represent the next evolution of AI applications, moving beyond simple question-answering to complex reasoning and action-taking systems. The infrastructure requirements for agents are more complex than traditional model serving because agents need to orchestrate multiple services, maintain state across long-running conversations, and integrate with external systems.
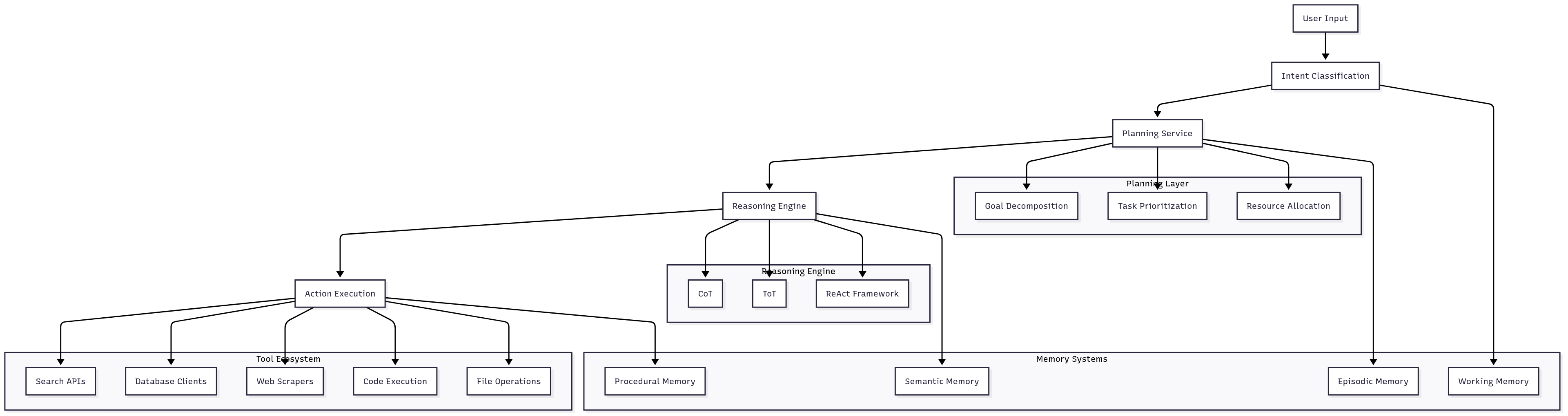
Agent Planning and Reasoning Systems
Planning services are responsible for decomposing complex user requests into manageable subtasks. This involves understanding the user's intent, identifying the necessary steps to achieve the goal, and creating an execution plan that considers available resources and potential failure modes.
Modern planning systems use sophisticated algorithms that combine classical AI planning techniques with LLM-based reasoning. The planning service must consider:
- Task dependencies: Some subtasks must be completed before others can begin
- Resource constraints: Available tools, API rate limits, and computational resources
- Uncertainty handling: Plans must be robust to failures and unexpected situations
- Optimization objectives: Balancing speed, cost, and quality of results
Reasoning engines implement different cognitive architectures for problem-solving:
Chain-of-Thought (CoT) prompting guides the model through step-by-step reasoning, significantly improving performance on complex problems. The infrastructure must support streaming responses to provide users with visibility into the reasoning process.
Tree of Thoughts (ToT) explores multiple reasoning paths simultaneously, maintaining a tree of possible solutions and using search algorithms to find optimal paths. This approach requires more computational resources but can significantly improve solution quality for complex problems.
ReAct (Reasoning and Acting) interleaves reasoning and action-taking, allowing agents to gather information and refine their understanding as they work toward a solution. This approach requires sophisticated state management and tool integration.
Tool Integration Architecture
Tool discovery and registration: Production agent systems need dynamic tool discovery mechanisms that allow new capabilities to be added without system downtime. This typically involves a service registry where tools can register their capabilities, input/output schemas, and operational characteristics.
Tool execution sandboxing: Security is paramount when agents can execute arbitrary tools. Containerization, network isolation, and resource limiting are essential to prevent malicious or buggy tools from compromising system security or stability.
Tool performance monitoring: Each tool integration point should be monitored for performance, reliability, and cost. This data feeds back into the planning system to inform tool selection decisions.
Conclusion
In this article, the second in the series of articles around AI infrastructure, you learnt about a subset of layers in the AI infrastructure stack, from AI gateways to load balancing to service orchestration to AI service layer architecture to the inference and Agent Architecture flow. The next articles in this series cover the key topics around AI infrastructure compute, storage, and observability stacks, including Telemetry, compliance, security, performance, and a further deep dive into optimization. Stay tuned.Opinions expressed by DZone contributors are their own.
Comments