AI Infrastructure for Agents and LLMs: Options, Tools, and Optimization
This article explores the diverse infrastructure options and tools that are available for deploying and optimizing AI agents and large language models (LLMs).
Join the DZone community and get the full member experience.
Join For FreeInfrastructure, whether on cloud, on-premise, or in a hybrid cloud, plays a critical role in implementing the AI architecture. This article is part of a series of articles that explores the diverse infrastructure options available for deploying and optimizing AI agents and large language models (LLMs). It delves into the crucial role infrastructure plays in realizing AI architectures, particularly for inference. We'll examine various tools, including open-source solutions, and illustrate the inference flow with diagrams, highlighting key considerations for efficient and scalable AI deployments.
Modern AI applications demand sophisticated infrastructure that can handle the computational intensity of large language models, the complexity of multi-agent systems, and the real-time requirements of interactive applications. The challenge lies not just in selecting the right tools, but in understanding how they integrate across the entire technology stack to deliver reliable, scalable, and cost-effective solutions.
This guide covers every aspect of AI infrastructure, from hardware acceleration and model serving to monitoring and security, with detailed explanations of open-source tools, architectural patterns, and implementation strategies that have been proven in production environments.
The Critical Role of Infrastructure in AI Architectures
AI architecture defines the blueprint for building and deploying AI systems. Infrastructure provides the foundation upon which this architecture is built. For AI agents and LLMs, infrastructure directly impacts performance, scalability, cost, and reliability. A well-designed infrastructure enables:
- Faster inference: Low latency is crucial for interactive AI agents and real-time applications.
- Scalability: Handling increasing user demand without performance degradation.
- Cost efficiency: Optimizing resource utilization to minimize operational expenses.
- Reliability: Ensuring high availability and fault tolerance.
1. The AI Infrastructure Stack: A Layered Approach
The modern AI infrastructure stack consists of seven interconnected layers, each serving specific functions while maintaining seamless integration with adjacent layers. Understanding this layered architecture is crucial for making informed decisions about tool selection, resource allocation, and operational strategies.
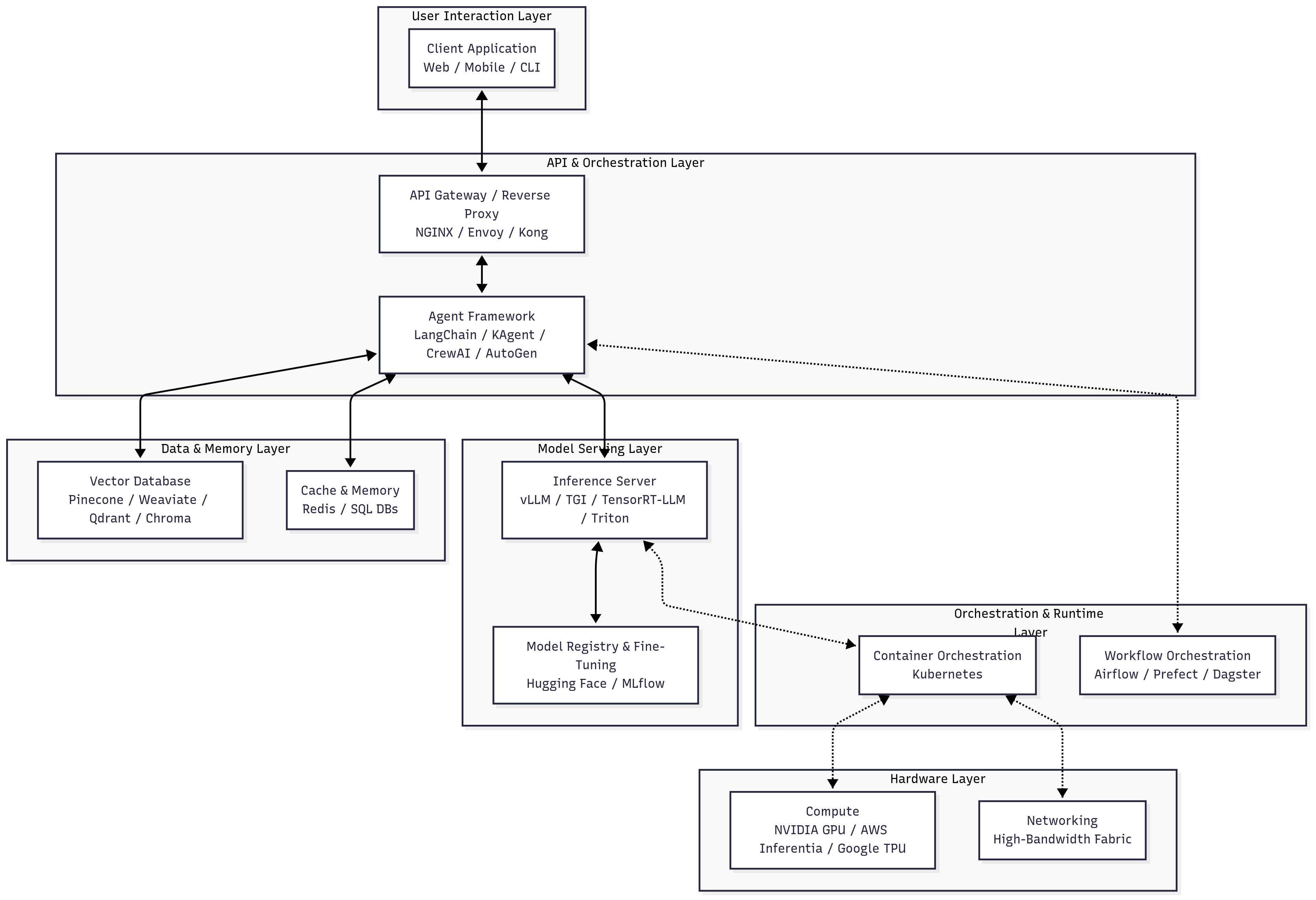
Explanation of Layers and Tools
- User interaction layer: This is the entry point where user requests originate. Clients can be web interfaces, mobile apps, or command-line tools. The key requirement is a stable, low-latency connection to the backend API layer.
- API and orchestration layer: This layer manages user requests and orchestrates complex workflows.
- API Gateway (NGINX, Envoy, Kong): Acts as the single entry point, handling ingress, authentication, rate limiting, and routing.
- Agent Framework (LangChain, KAgent, CrewAI, AutoGen): These frameworks serve as the core logic for AI operations. KAgent is a specialized tool designed for high-efficiency orchestration, enabling dynamic routing and workflow management for AI tasks.
- Data and memory layer: This provides context and persistence, turning stateless models into knowledgeable assistants.
- Vector databases (Pinecone, Weaviate, Qdrant, Chroma): Specialized databases for storing and querying high-dimensional vectors, essential for Retrieval-Augmented Generation (RAG).
- Cache and memory (Redis, SQL DBs): Redis is used for low-latency caching and short-term memory, while SQL databases store long-term memory like conversation history and user preferences.
- Model serving layer: The core of inference, where models are loaded and executed.
- Inference servers (vLLM, TGI, TensorRT-LLM, Triton): Specialized servers optimized for high-throughput, low-latency inference, supporting dynamic batching and quantization.
- Model registry and fine-tuning (Hugging Face, MLflow): Centralized repositories for managing model lifecycles, from training to deployment.
- Orchestration and runtime layer: The foundation that abstracts underlying hardware.
- Container orchestration (Kubernetes): Manages container lifecycles, providing scalability, resilience, and efficient resource utilization.
- Workflow orchestration (Airflow, Prefect, Dagster): Orchestrates complex data and machine learning pipelines, supporting tasks like training jobs and data ingestion.
- Hardware Layer: The physical substrate for computation.
- Compute (NVIDIA GPUs, AWS Inferentia, Google TPUs): Specialized accelerators essential for LLM inference.
- Networking: High-speed interconnects like NVLink and InfiniBand critical for multi-GPU and multi-node communication.
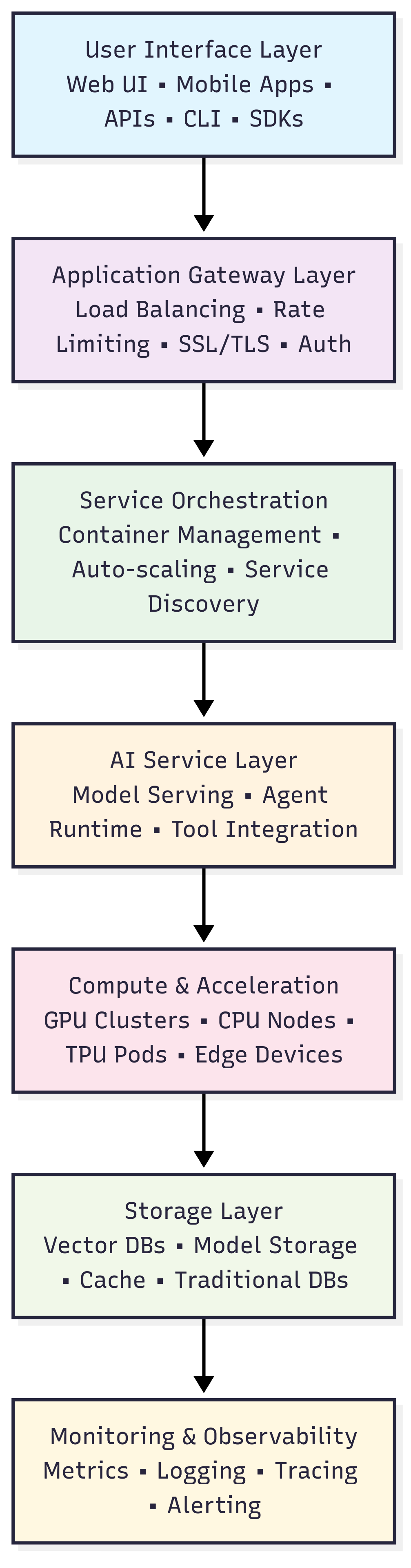
Layer Interdependencies and Data Flow
Each layer in the infrastructure stack has specific responsibilities and interfaces with other layers through well-defined protocols and APIs. The User Interface Layer handles all external interactions, converting user requests into standardized formats that can be processed by downstream services. The Application Gateway Layer provides crucial security, routing, and traffic management functions, ensuring that requests are properly authenticated, authorized, and distributed across available resources.
The Service Orchestration Layer manages the lifecycle of containerized services, handling deployment, scaling, and health monitoring of AI workloads. This layer is particularly important for AI applications because of their dynamic resource requirements and the need for sophisticated scheduling algorithms that consider GPU availability, model loading times, and memory constraints.
The AI Service Layer contains the core business logic for AI applications, including model inference engines, agent orchestration systems, and tool integration frameworks. This layer abstracts the complexity of different AI frameworks and provides consistent APIs for upstream services.
The Compute and Acceleration Layer provides the raw computational power needed for AI workloads, with specialized hardware acceleration for different types of operations. The Storage Layer manages both hot and cold data, including model weights, vector embeddings, and application state. Finally, the Monitoring and Observability Layer provides visibility into system performance, user behavior, and operational health across all other layers.
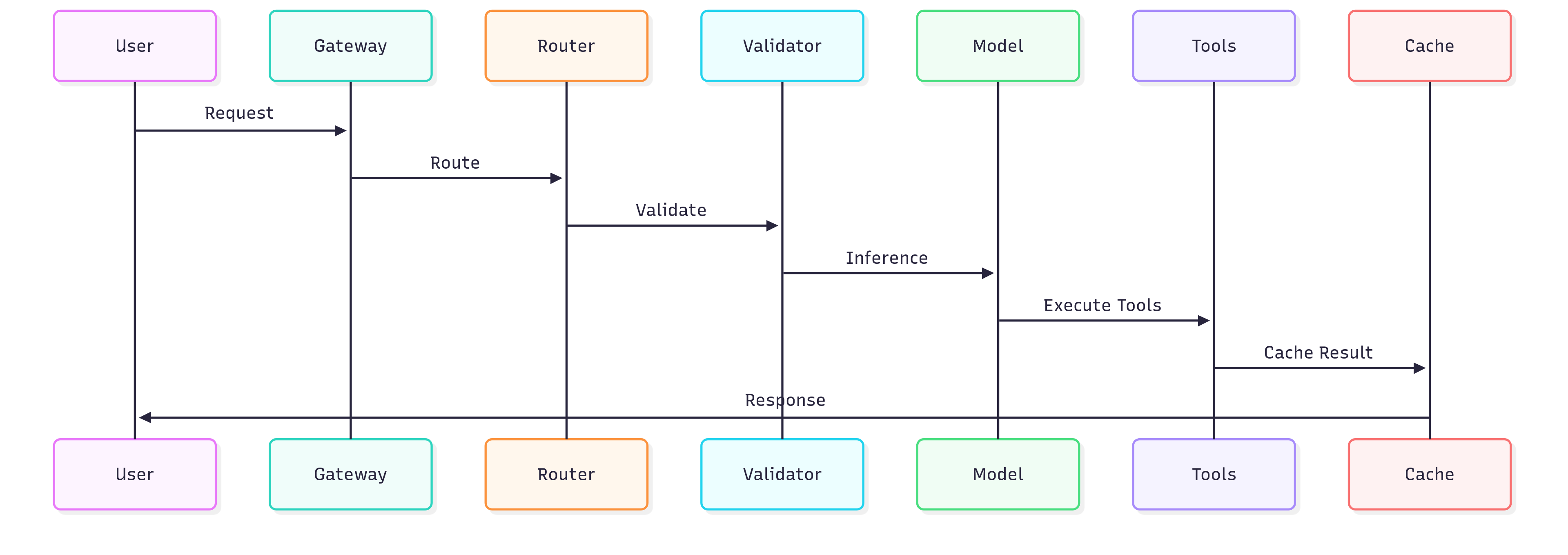
2. The Inference Flow: From User Prompt to AI Response
The journey of a user query through the AI infrastructure involves multiple steps and tools. The following diagram outlines this flow, highlighting key components and their interactions.
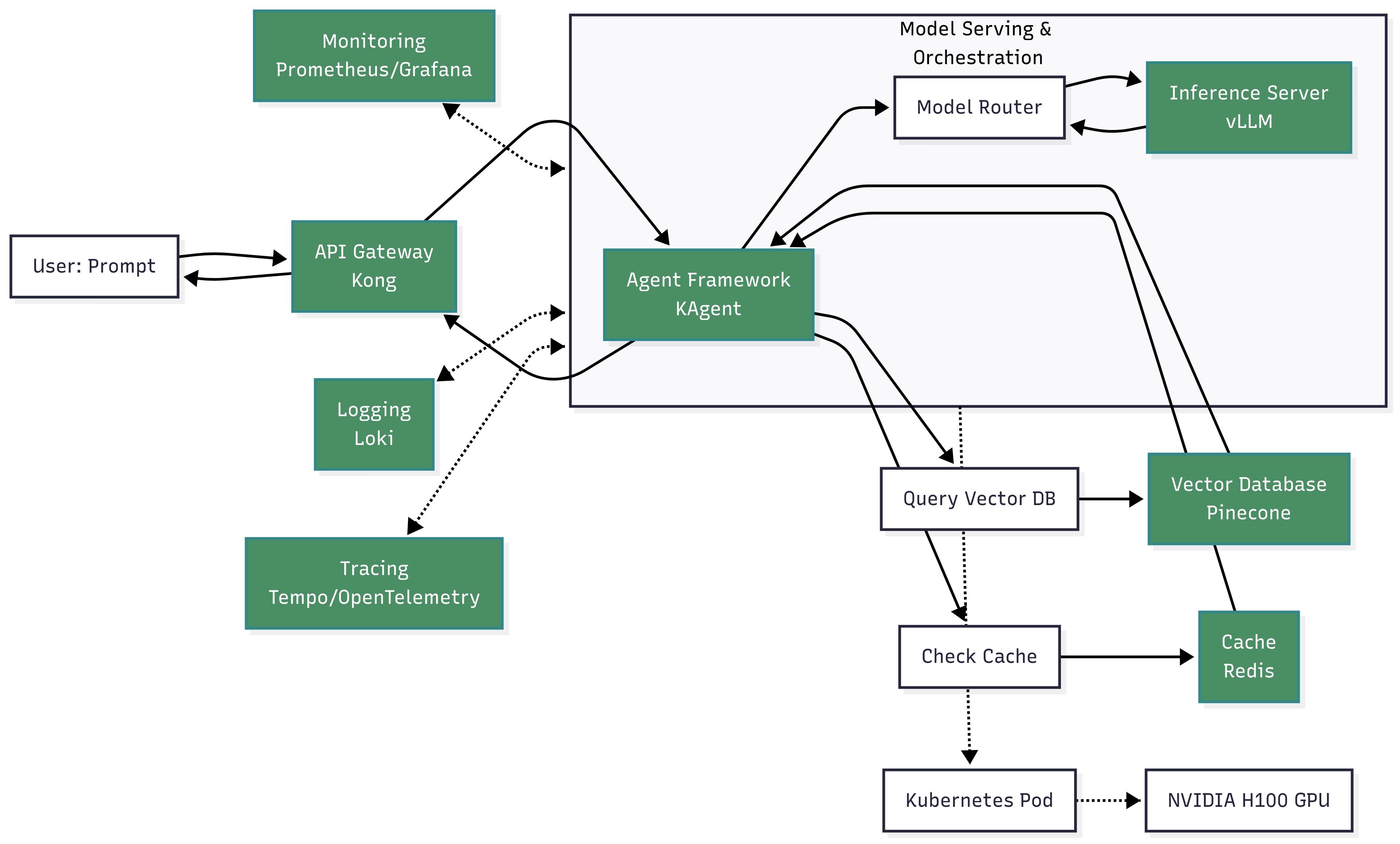
Step-by-Step Breakdown
- Initial contact: A user sends a prompt via a web interface. The request is routed through an API Gateway (Kong), which handles authentication and rate limiting.
- Agentic orchestration: The gateway forwards the request to an agent framework like KAgent, which parses the user's intent and initiates a multi-step reasoning process.
- Context retrieval (RAG): The agent converts the prompt into an embedding and queries a vector database (Pinecone), which returns relevant context from internal documents.
- Memory and caching: The agent checks a cache (Redis) for similar queries and retrieves long-term context from a SQL database.
- Model routing and inference: The agent sends the enriched prompt to a model router, which calls an inference server (vLLM). The server uses dynamic batching and KV caching to generate the response efficiently.
-
The role of KV cache: During autoregressive decoding, the KV cache stores computed Key and Value vectors for previous tokens. For each new token, it only computes vectors for the new token, retrieving others from the cache. This reduces redundant computation, drastically cutting latency and boosting throughput.
-
- Response generation and action: The generated response is returned to the agent, which may post-process it or trigger actions via API calls. The final response is sent back through the API Gateway to the user.
- Observability: The entire process is monitored with Prometheus for metrics, Loki for logs, and OpenTelemetry for traces, providing full visibility into system performance.
Understanding the end-to-end inference flow is crucial for optimization and troubleshooting.
3. Essential Open-Source Tools
Model Serving Engines
- vLLM leads in production inference through PagedAttention algorithm and continuous batching. It achieves 2-4x higher throughput than traditional frameworks and supports tensor parallelism for large models.
- Text generation inference (TGI) provides enterprise features with comprehensive monitoring, streaming responses, and OpenAI-compatible APIs. Ideal for production deployments requiring operational simplicity.
- Ollama excels in development and edge deployments with automatic model management, quantization, and simple setup. Perfect for prototyping and local development.
Agent Frameworks
- LangChain offers the most comprehensive ecosystem with extensive integrations for tools, data sources, and model providers. Its modular architecture enables complex workflow composition.
- CrewAI specializes in multi-agent scenarios where different AI agents collaborate with role-based approaches and sophisticated team dynamics.
- AutoGen provides conversational AI frameworks where multiple agents engage in collaborative problem-solving and negotiation.
Vector Databases
- ChromaDB suits development and small-scale deployments with excellent Python integration and simple deployment. Uses SQLite backend for reliability.
- Qdrant excels in production with Rust-based performance, advanced filtering capabilities, and distributed scaling. Supports complex queries combining vector similarity with structured data.
- Weaviate provides enterprise features including hybrid search, multi-modal capabilities, and GraphQL APIs for flexible query patterns.
4. AI Agent Architecture
AI agents extend beyond simple models, serving as complex reasoning and action-taking systems.
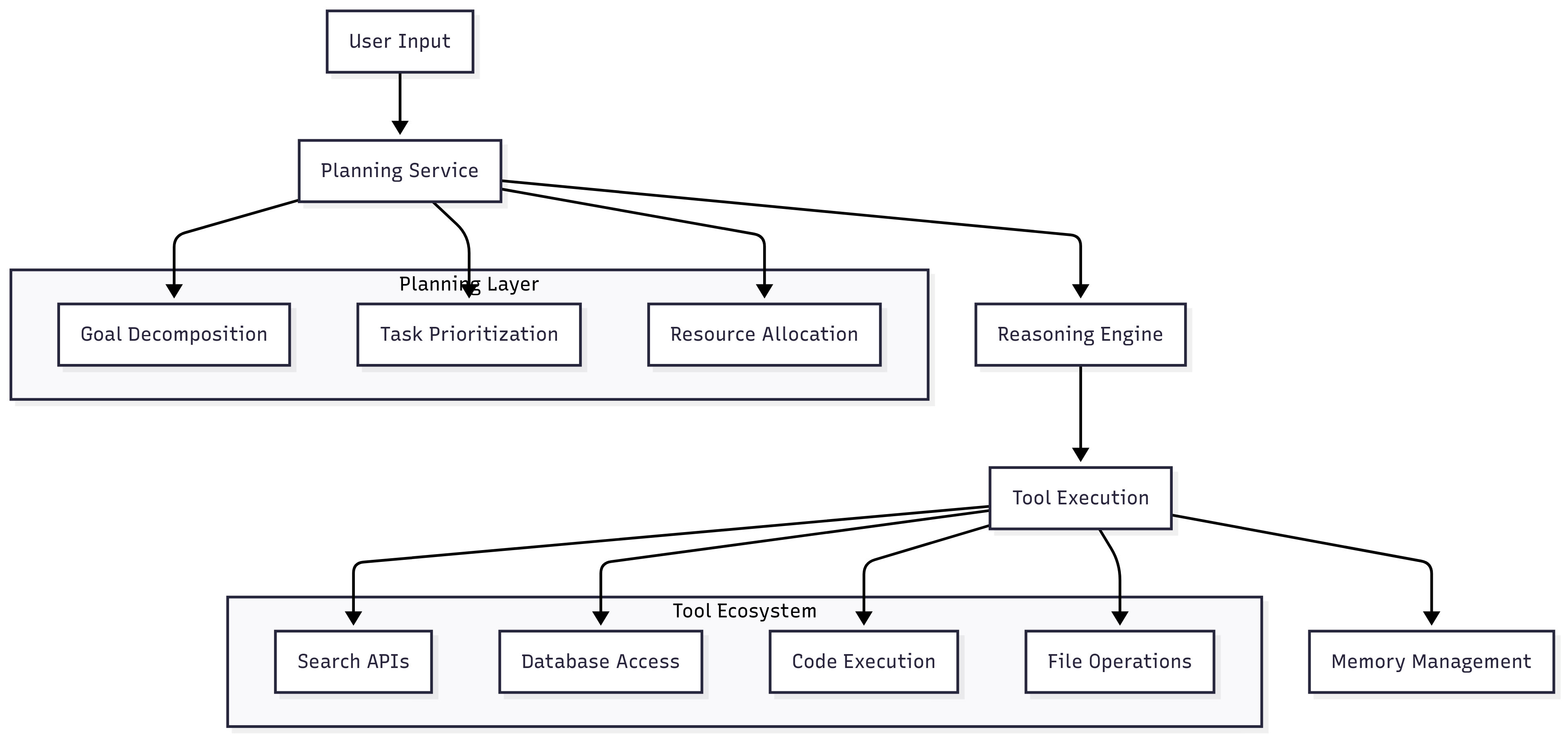
- Planning services decompose complex requests into manageable subtasks, considering dependencies, resource constraints, and failure handling.
- Tool integration requires dynamic discovery, secure execution sandboxing, and performance monitoring. Each tool must be containerized with proper resource limits and network isolation.
- Memory systems handle different types of agent memory: working memory (current context), episodic memory (conversation history), and semantic memory (learned knowledge).
5. Optimization
Quantization reduces memory requirements and improves inference speed. INT8 quantization provides 2x memory reduction with minimal accuracy loss, while INT4 offers 4x reduction with 2-5% accuracy degradation.
Model serving optimization includes KV-cache management for transformer models, dynamic batching for variable request sizes, and tensor parallelism for multi-GPU deployments.
KV-Cache
The KV (Key-Value) cache is a fundamental optimization technique for efficient LLM inference. Without it, each token generation would require recalculating all previous tokens' vectors, resulting in unsustainable computational overhead.
How KV Cache Works
The cache stores computed Key and Value vectors for all previous tokens in a sequence. When generating a new token, the model only computes the K and V vectors for that token, retrieving the rest from the cache. This reduces the computational complexity from quadratic to linear, delivering significant speed-ups.
Challenges and Strategies
- Memory footprint: The KV cache can consume substantial GPU memory, especially for long sequences and large batches.
- Optimization techniques: To address this, advanced methods like cache offloading, quantization, and eviction policies are employed to balance memory usage and performance.
Hardware Acceleration
GPU optimization focuses on memory bandwidth utilization, compute vs. memory-bound operation identification, and multi-GPU coordination efficiency.
CPU optimization leverages advanced instruction sets (AVX-512, AVX2), threading libraries (OpenMP, Intel TBB), and optimized math libraries (Intel MKL, OpenBLAS).
Cost Optimization Strategies
- Intelligent caching: Semantic similarity-based caching for AI responses
- Spot instances: Use spare capacity for batch processing and development
- Model sharing: Single model instance serving multiple applications
- Dynamic scaling: Scale based on queue depth and response time targets

Comprehensive Tool Reference
The complete catalog of open source tools organized by infrastructure layer provides a comprehensive reference for building AI systems.
| Layer | Category | Tools | Primary Use Cases |
|---|---|---|---|
| Hardware & Cloud | GPU Computing | ROCm, CUDA Toolkit, OpenCL | Hardware acceleration, GPU programming, compute optimization |
| Cloud Management | OpenStack, CloudStack, Eucalyptus | Private cloud infrastructure, resource management | |
| Container & Orchestration | Containerization | Docker, Podman, containerd, LXC | Application packaging, isolation, portability |
| Orchestration | Kubernetes, Docker Swarm, Nomad | Container scheduling, scaling, service discovery | |
| Distributed Computing | Ray, Dask, Apache Spark, Horovod | Distributed training, parallel processing, multi-node inference | |
| Workflow Management | Apache Airflow, Kubeflow, Prefect, Argo Workflows | ML pipeline automation, job scheduling, workflow orchestration | |
| Model Runtime & Optimization | ML Frameworks | PyTorch, TensorFlow, JAX, Hugging Face Transformers | Model training, inference, neural network development |
| Inference Optimization | ONNX Runtime, TensorRT, OpenVINO, TVM | Model optimization, cross-platform inference, performance tuning | |
| Model Compression | GPTQ, AutoGPTQ, BitsAndBytes, Optimum | Quantization, pruning, model size reduction | |
| LLM Serving | vLLM, Text Generation Inference, Ray Serve, Triton | High-performance LLM inference, request batching, scaling | |
| API & Serving | Model Deployment | BentoML, MLflow, Seldon Core, KServe | Model packaging, versioning, deployment automation |
| Web Frameworks | FastAPI, Flask, Django, Tornado | REST API development, web services, microservices | |
| Load Balancing | Nginx, HAProxy, Traefik, Envoy Proxy | Traffic distribution, reverse proxy, service mesh | |
| API Gateway | Kong, Zuul, Ambassador, Istio Gateway | API management, authentication, rate limiting | |
| Data & Storage | Vector Databases | Weaviate, Qdrant, Milvus, Chroma | Embedding storage, semantic search, RAG applications |
| Traditional Databases | PostgreSQL, MongoDB, Redis, Cassandra | Structured data, caching, session storage, metadata | |
| Data Processing | Apache Kafka, Apache Beam, Pandas, Polars | Stream processing, ETL, data transformation | |
| Feature Stores | Feast, Tecton, Hopsworks, Feathr | Feature engineering, serving, versioning, sharing | |
| Monitoring & Observability | Infrastructure Monitoring | Prometheus, Grafana, Jaeger, OpenTelemetry | Metrics collection, visualization, distributed tracing |
| ML Experiment Tracking | MLflow, Weights & Biases, Neptune.ai, ClearML | Experiment logging, model versioning, hyperparameter tracking | |
| LLM Observability | LangKit, Arize Phoenix, LangSmith, Helicone | LLM performance monitoring, prompt evaluation, usage analytics | |
| Logging & Analytics | ELK Stack, Fluentd, Loki, Vector | Log aggregation, search, analysis, alerting | |
| Application & Agent | Agent Frameworks | LangChain, AutoGen, CrewAI, LlamaIndex | Agent development, multi-agent systems, tool integration |
| Workflow Automation | n8n, Apache Airflow, Temporal, Zapier Alternative | Business process automation, workflow orchestration | |
| Security & Access | Keycloak, HashiCorp Vault, Open Policy Agent | Authentication, secrets management, policy enforcement | |
| Testing & Quality | DeepEval, Evidently, Great Expectations, Pytest | Model testing, data validation, quality assurance |
Conclusion: Infrastructure as a Strategic Advantage
Building successful AI infrastructure requires balancing immediate needs with long-term scalability. Start with proven, simple solutions and add complexity incrementally.
Architecting AI infrastructure is a primary engineering function that directly impacts the performance, cost, and reliability of AI products. A well-designed system, built on a layered approach and leveraging tools like Kubernetes, vLLM, KAgent, and Pinecone, can handle massive scale while providing a seamless user experience.
The AI infrastructure landscape evolves rapidly, but focusing on solid foundations with open-source tools, comprehensive observability, and operational excellence enables organizations to leverage AI advances while maintaining reliable, scalable operations. Your specific journey depends on unique requirements, but this framework provides the roadmap for building an AI infrastructure that drives real business value.
Understanding and implementing advanced optimizations like KV caching is crucial for transitioning from a prototype to a production-grade system. As AI evolves, efficient infrastructure will remain the key differentiator, enabling organizations to deploy powerful, scalable, and cost-effective AI applications.
In the next articles in this series, you will learn about layer-by-layer infrastructure analysis with a deep dive into monitoring, security compliance, and performance optimization.
Opinions expressed by DZone contributors are their own.
Comments