Driving RAG-Based AI Infrastructure
When paired with AI agents for workflow orchestration, RAG-based AI infrastructure excels in dynamic decision-making, analytics, and automation.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) have transformed AI with their ability to process and generate human-like text. However, their static pre-trained knowledge presents challenges for dynamic, real-time tasks requiring current information or domain-specific expertise. Retrieval-augmented generation (RAG) addresses these limitations by integrating LLMs with external data sources. When paired with AI agents that orchestrate workflows, RAG-based infrastructure becomes a powerful tool for real-time decision-making, analytics, and automation.
System Architecture
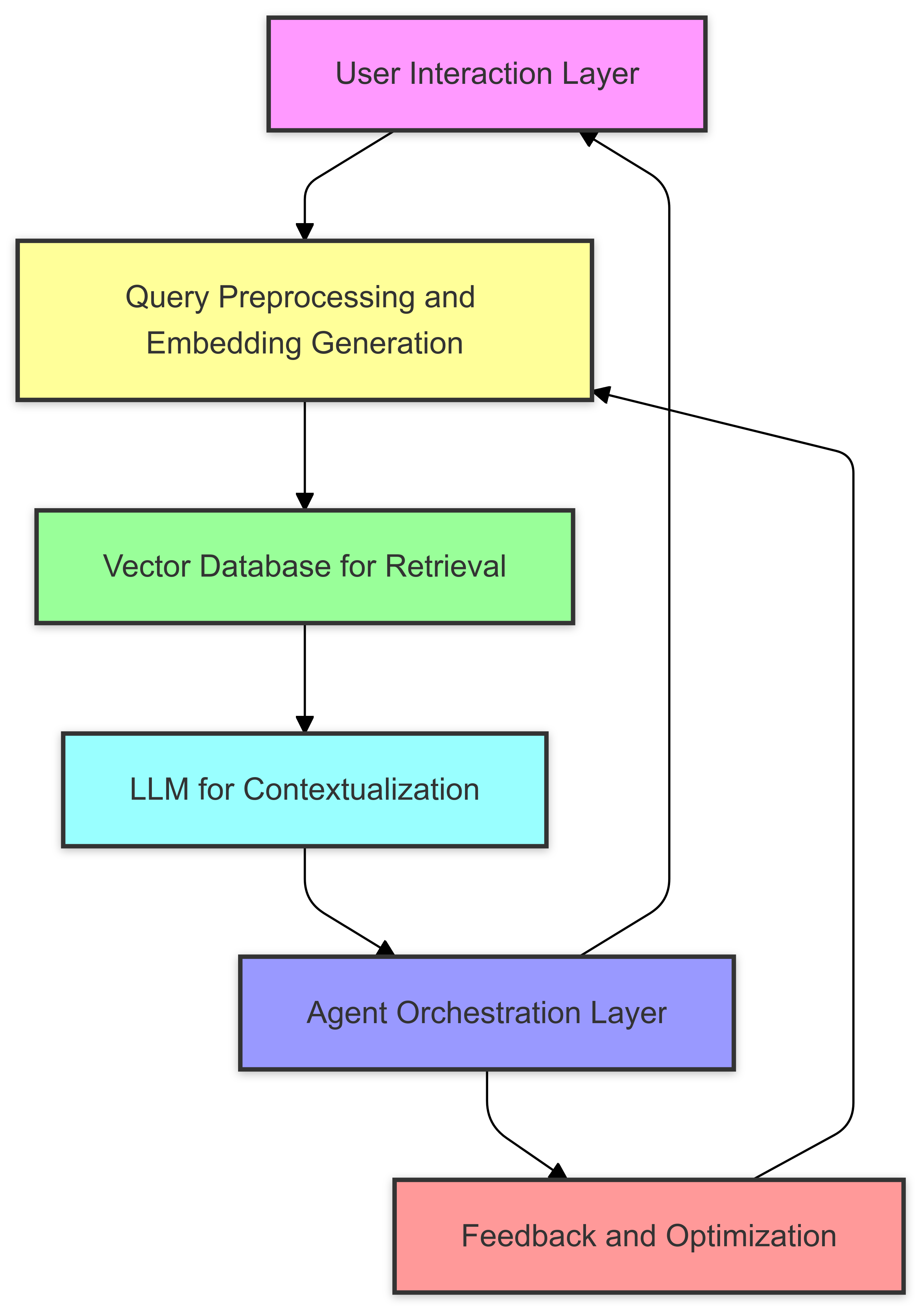
The architecture of a RAG-based AI system includes several core components:
- User Interaction Layer: This is the interface where users input queries. It can range from chatbots to APIs. The input is processed for downstream components. For example, in an enterprise setting, a user might request the latest compliance updates.
- Query Preprocessing and Embedding Generation: The input is tokenized and converted into a vectorized format using models like OpenAI’s Ada or Hugging Face Transformers. These embeddings capture semantic meaning, making it easier to match with relevant data.
- Vector Database for Retrieval: A vector database like Pinecone or FAISS stores pre-indexed embeddings of documents. It retrieves the most relevant information by comparing query embeddings with stored embeddings. For example, a legal assistant retrieves specific GDPR clauses based on user queries.
- LLM for Contextualization: Retrieved data is fed into an LLM, which synthesizes the information to generate responses. Models such as GPT-4 or Claude can create summaries, detailed explanations, or execute logic-based tasks.
- Agent Orchestration Layer: AI agents act as managers that sequence tasks and integrate with APIs, databases, or tools. For example, a financial agent might retrieve transaction data, analyze patterns, and trigger alerts for anomalies.
- Feedback and Optimization: The system collects feedback on responses and incorporates it into learning loops, improving relevance over time. Techniques such as Reinforcement Learning from Human Feedback (RLHF) and fine-tuning help refine the system.
Proposed Architecture Trade-Offs
Pros
- Dynamic knowledge updates: By retrieving data from live sources, RAG ensures responses are current and accurate. For example, medical systems retrieve updated clinical guidelines for diagnostics.
- Scalability: Modular components allow scaling with workload by adding resources to vector databases or deploying additional LLM instances.
- Task automation: Orchestrated agents streamline multi-step workflows like data validation, content generation, and decision-making.
- Cost savings: External retrieval reduces the need for frequent LLM retraining, lowering compute costs.
Cons
- Latency: Integration of multiple components like vector databases and APIs can lead to response delays, especially with high query volumes.
- Complexity: Maintaining and debugging such a system requires expertise in LLMs, retrieval systems, and distributed workflows.
- Dependence on data quality: Low-quality or outdated indexed data leads to suboptimal results.
- Security risks: Handling sensitive data across APIs and external sources poses compliance challenges, particularly in regulated industries.
Case Studies
1. Fraud Detection in Banking
A RAG-based system retrieves known fraud patterns from a vector database and analyzes real-time transactions for anomalies. If a match is detected, an AI agent escalates the case for review, enhancing financial security.
2. Legal Document Analysis
Legal assistants leverage LLMs with RAG to extract key clauses and flag potential risks in contracts. Indexed legal databases enable quick retrieval of precedent cases or regulatory guidelines, reducing manual review time.
3. Personalized Learning
In education, AI agents generate personalized lesson plans by retrieving resources from academic databases based on a student’s performance. The LLM contextualizes this information, offering customized recommendations for improvement.
Conclusion
RAG-based AI infrastructure powered by LLMs and AI agents bridges the gap between static pre-trained knowledge and dynamic, real-time requirements. At the same time, the system's complexity and data dependencies present challenges, its ability to integrate live data and automate workflows makes it invaluable in applications like finance, healthcare, and education. With advancements in frameworks like LangChain and Pinecone, the adoption of RAG-based systems is poised to grow, delivering smarter, context-aware solutions.
Opinions expressed by DZone contributors are their own.
Comments