RAG Systems: A Brand New Architecture Tool
Discover how RAG systems boost AI by combining real-time data retrieval with language models for accurate, relevant responses.
Join the DZone community and get the full member experience.
Join For FreeLet’s cut to the chase: Retrieval-Augmented Generation (RAG) systems are reshaping how we approach AI-driven information processing. As architects, we need to understand the nuts and bolts of these systems to leverage their potential effectively.
What’s RAG?
At its core, a RAG system enhances the capabilities of LLMs by integrating them with external knowledge sources. This integration allows the model to pull in relevant information dynamically, enabling it to generate responses that are not only coherent but also factually accurate and contextually relevant. The main components of a RAG system include:
- Retriever: This component fetches relevant data from an external knowledge base.
- Generator: The LLM synthesizes the retrieved information into a human-like response.
By leveraging these components, RAG systems can provide answers that are informed by real-time data rather than relying solely on pre-trained knowledge, which can quickly become outdated.
The RAG Pipeline: How It Works
The architecture of a RAG system can be visualized in a straightforward pipeline:
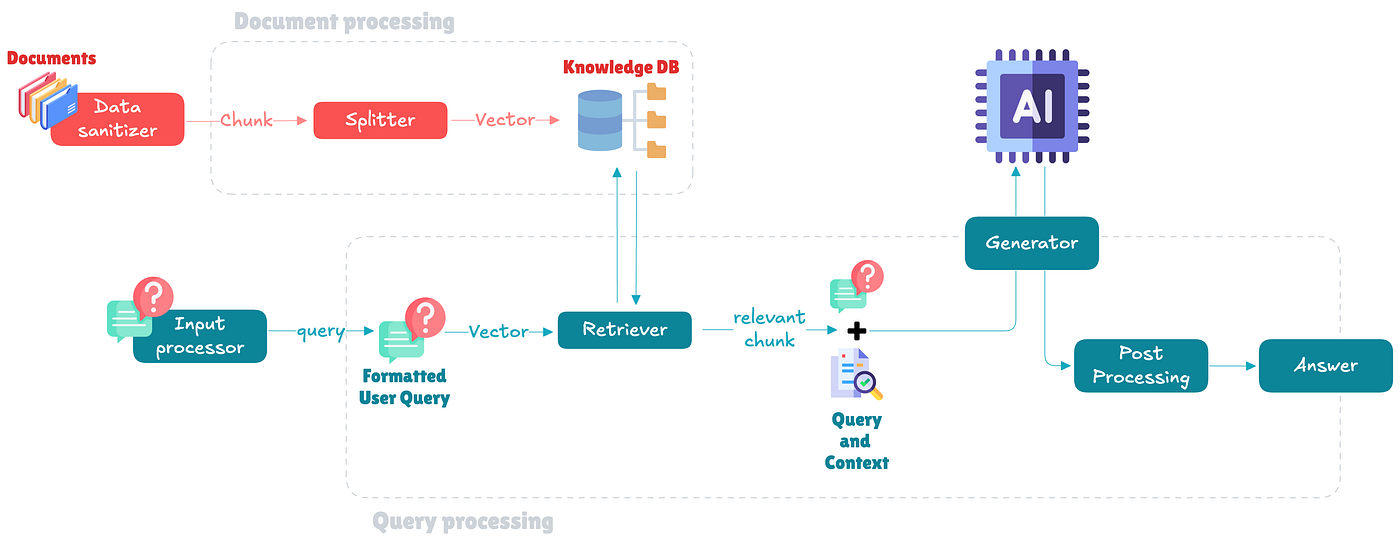
Document Processing Block
- Data sanitizer: This component cleans and preprocesses incoming documents to ensure the data is accurate and free from noise. It prepares the documents for efficient processing and storage.
- Splitter: The splitter divides documents into smaller, manageable chunks. This step is crucial for creating vector representations that can be efficiently stored and retrieved from the database.
- Knowledge DB: This is where the processed document chunks are stored as vectors. The database enables fast retrieval of relevant information based on semantic similarity.
Query Processing Block
- Input processor: This component handles user queries, performing tasks like parsing and preprocessing to ensure the query is clear and ready for retrieval.
- Retriever: The retriever searches the Knowledge DB for relevant document vectors that match the user query. It uses vector similarity measures to find the most pertinent information.
- Generator: The generator uses a large language model (LLM) to synthesize a coherent response by combining the retrieved information with its own knowledge base.
This setup allows RAG systems to dynamically pull in relevant data, enhancing the accuracy and relevance of generated responses
Benefits
RAG systems offer several advantages that make them a powerful tool in the architect’s toolkit:
- Real-time information retrieval: By integrating external knowledge sources, RAG systems access up-to-date information, ensuring responses are current and relevant.
- Enhanced accuracy: The retriever component allows for precise data fetching, reducing errors and improving factual accuracy.
- Contextual relevance: Dynamically incorporating context from the knowledge base produces more coherent and contextually appropriate outputs.
- Scalability: RAG architectures can scale to handle large volumes of data and queries, making them suitable for enterprise-level applications.
Trade-Offs
While RAG systems are powerful, they come with certain trade-offs that architects need to consider:
- Complexity: Integrating multiple components (retriever, generator, knowledge base) increases system complexity, requiring careful design and maintenance.
- Latency: Real-time data retrieval can introduce latency, potentially affecting response times. Optimizing each component is crucial to minimize delays.
- Resource intensive: Robust infrastructure is needed to support vector databases and large language models, leading to higher computational costs.
- Data privacy: Handling sensitive information in real-time retrieval poses privacy concerns that must be managed with strict security protocols.
Conclusion
RAG systems represent a significant advancement in AI architecture by seamlessly integrating real-time information retrieval with powerful language generation. This combination allows for more accurate, relevant, and contextually aware responses, making RAG a valuable tool for architects navigating the complexities of modern data environments. As we continue to explore and refine these systems, the potential for innovation in AI-driven applications is vast. Future developments may focus on enhancing efficiency and privacy, paving the way for even broader adoption across industries. RAG systems are not just a trend; they are a pivotal step toward more intelligent and responsive AI solutions.
Published at DZone with permission of Pier-Jean MALANDRINO. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments