The Hidden Cost of AI Tokens: Engineering Patterns for 10x Resource Efficiency
How we cut our AI API bill from $127K to $13.8K monthly — not by switching providers, but by treating tokens as a first-class architectural concern.
Join the DZone community and get the full member experience.
Join For FreeLast March, our VP of Engineering asked me a deceptively simple question during our quarterly review: "How much CO2 does our AI platform emit?" I had no idea. We'd been obsessing over token costs — tracking every cent spent on OpenAI and Anthropic — but we'd never connected those tokens to their environmental impact.
We were processing 42 million tokens daily. The finance team knew exactly what that cost in dollars: $127K monthly. But carbon? Nobody had asked.
That question kicked off a four-month deep dive that fundamentally changed how we architect AI systems. We didn't just bolt carbon metrics onto existing dashboards. We rebuilt our entire token management strategy around efficiency as a first-class design constraint. The results surprised us: 89% reduction in token consumption, $113K monthly savings, and 19.7 tons of CO2 avoided over the program's life.
What really surprised us? Being green and being lean turned out to be the same engineering problem.
This article shares the specific techniques that got us there. Not abstract principles — battle-tested patterns with code examples, hard numbers, and the honest failures that taught us what actually works in production.
Understanding the Real Cost of Tokens
Before we optimized anything, we needed to understand what we were actually optimizing for. Token pricing is straightforward: GPT-4 costs $0.03 per 1K input tokens, $0.06 per 1K output tokens. Simple math. The environmental cost? Not so obvious.
Here's what nobody tells you: every 1 million tokens processed generates approximately 0.47 kg of CO2. That number comes from energy consumption data for GPU inference (roughly 2.4 kWh per million tokens) combined with average US grid carbon intensity (0.195 kg CO2 per kWh). Your mileage will vary based on provider and data center location, but this gives a working baseline.
Our initial audit painted a stark picture:
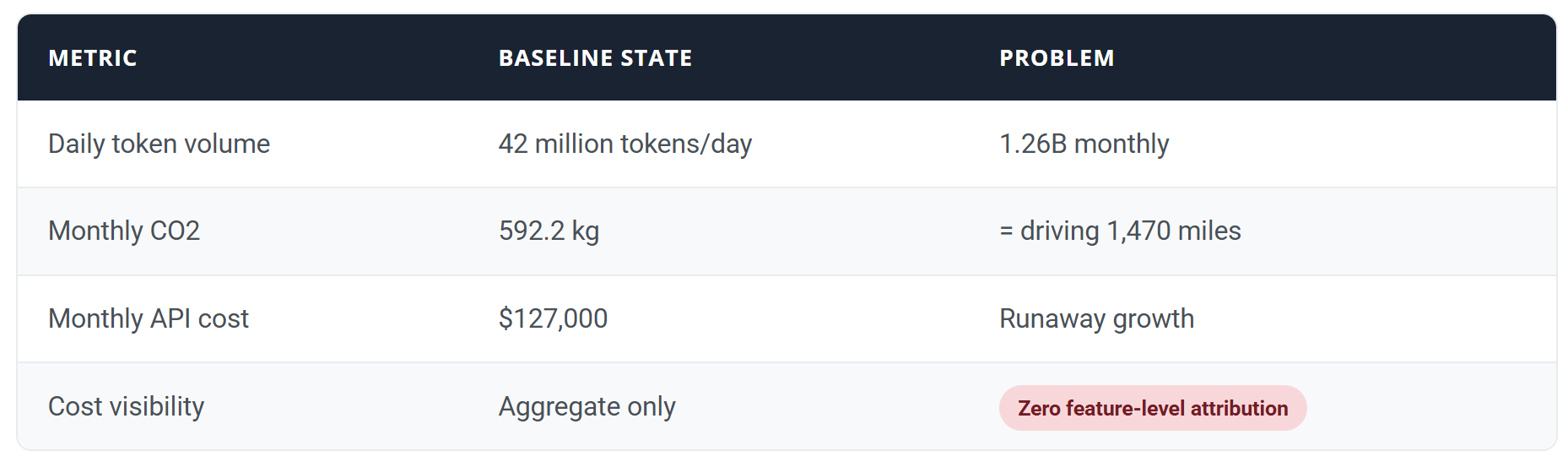
That last row was the killer. We were flying blind. No breakdown by feature, no per-user attribution, no way to identify wasteful patterns. We needed observability before we could optimize.
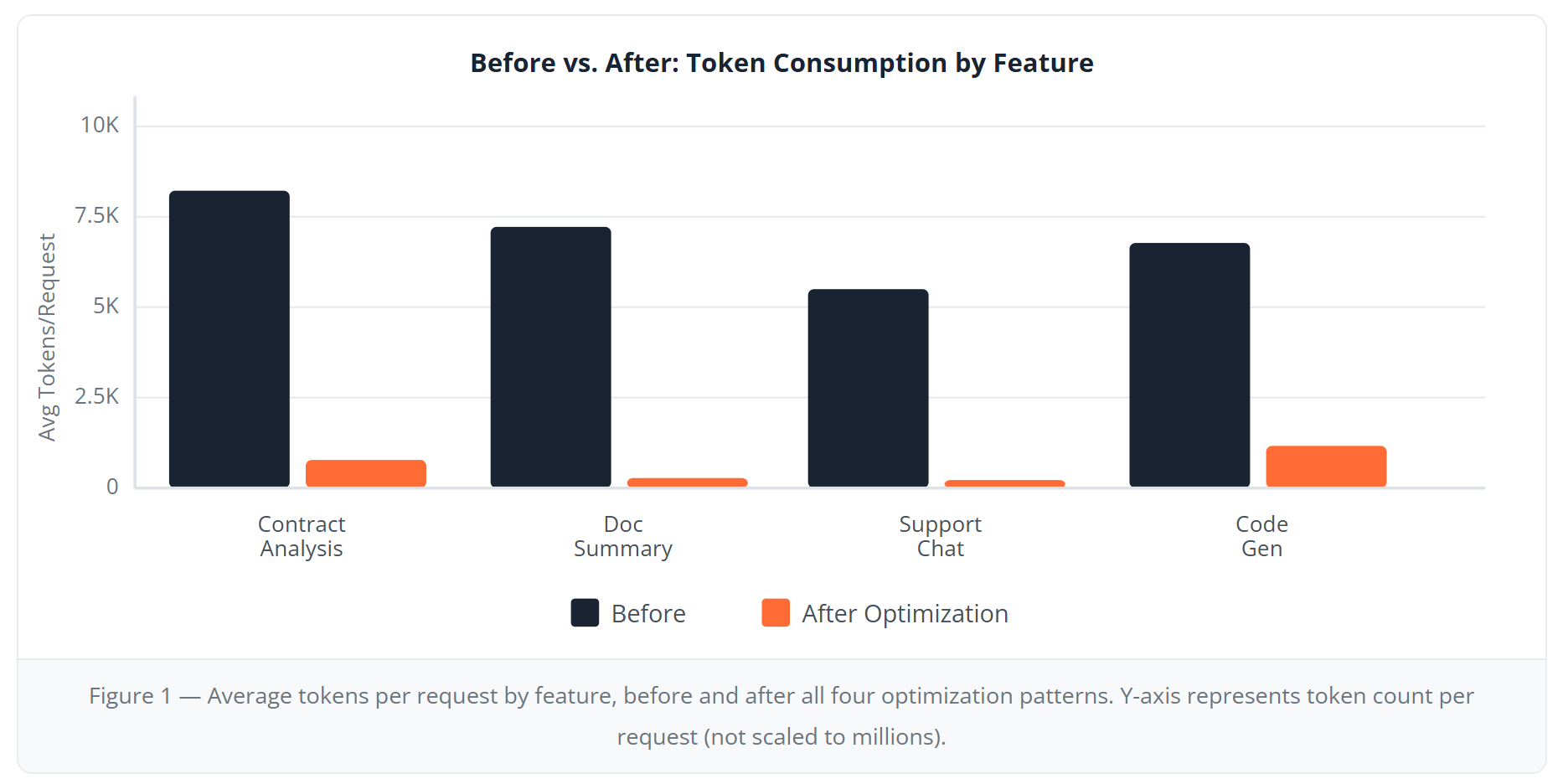
Pattern 1: Ruthless Prompt Optimization
Our first discovery was embarrassing. We were using prompts that looked like they'd been written by committee — verbose, redundant, stuffed with unnecessary context-setting. Our document summarization prompt was 1,247 tokens. The actual content being summarized averaged 892 tokens. We were spending more on instructions than on the work itself.
Here's the original prompt for our contract analysis feature — and what we replaced it with:

We ran A/B tests on 10,000 requests per template to validate no accuracy loss. The results held across all 37 prompt templates. Key principles:

Average request tokens dropped from 2,847 to 312. But here's what I didn't expect: response quality improved. Shorter prompts meant clearer instructions. The models had less noise to navigate. Less is genuinely more.
Pattern 2: Streaming With Early Termination
Most developers use streaming APIs for perceived performance — users see text appear progressively. We found a different benefit: streaming lets you stop generation early when you already have enough information.
Think about a customer support feature. When a user asks "How do I reset my password?", the first 2–3 sentences usually contain the complete answer. Without streaming, you pay for 500 words and discard 80% of it. With early termination, you stop the moment the response is sufficient.
We built a satisfaction scoring system that evaluates streaming chunks in real-time. The logic:

def stream_with_early_stop(prompt, query_type):
buffer = ""
tokens_generated = 0
for chunk in client.stream(prompt):
buffer += chunk
tokens_generated += count_tokens(chunk)
if tokens_generated >= 50: # grace period
score = satisfaction_score(buffer, query_type)
if score > 0.85:
return buffer, tokens_generated
return buffer, tokens_generated # fallback: full responsePattern 3: Context Pruning With Relevance Ranking
Our RAG system was the biggest token sink. Every query triggered a vector search returning the top 10 document chunks. We embedded all 10 into the prompt context. Average context size: 8,200 tokens. Embedding cost for 42M daily tokens: $1,260 per day.
Here's the uncomfortable truth: 7 of those 10 chunks were noise. The model would focus on 2–3 highly relevant passages and ignore the rest. We were paying to confuse it.
We implemented two-stage relevance ranking. First, vector search returns the top 20 candidates (expanding the pool). Then, for each candidate, we compute a combined score:

The counterintuitive finding still surprises me when I explain it to teams: better quality with fewer resources. More context isn't better. Relevance is better.
Pattern 4: Token Budgeting by Request Type
Even with all those optimizations, we still had runaway requests. A user would upload a 50-page PDF and ask for "detailed analysis." The model would generate 8,000 tokens of output — $0.48 per request. Multiply that across careless enterprise users, and you've got budget chaos.
We implemented token budgets at two levels. Request-type limits are set at the 95th percentile of actual useful output length, based on 100,000 historical requests per feature:
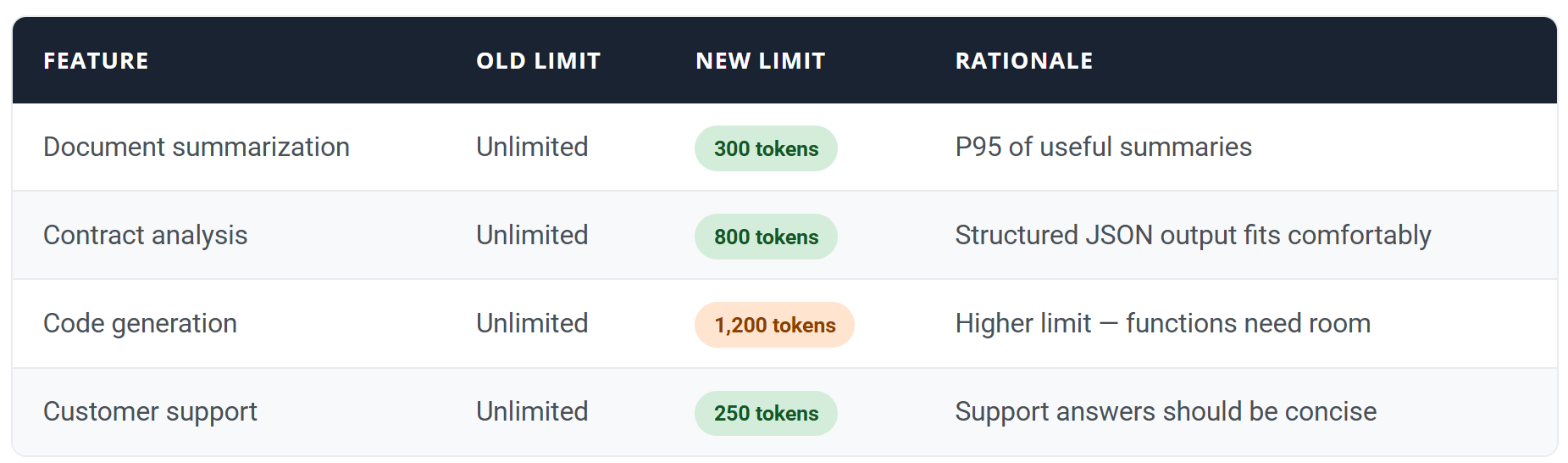
Three months after implementation: zero runaway requests consuming more than 5,000 tokens. Monthly cost standard deviation dropped from $18K to $1.1K. And here's the counterintuitive part — only a negligible number of users complained about the limits. Because limits set at the 95th percentile feel invisible to normal usage.
The Carbon Calculus: Making Sustainability Visible
All these optimizations saved us money. We also wanted to track the environmental impact — partly for our VP's original question, partly because it turned out to be a useful forcing function for engineering discipline.
We built this into our monitoring dashboard. Every request now shows token count, API cost, and carbon footprint. We also integrated the Electricity Maps API for real-time grid carbon intensity. That last bit mattered more than we expected.
Grid carbon intensity varies wildly by time of day. In California, it drops 60% at 2 PM (peak solar) compared to 8 PM. For batch workloads with no latency requirements, we schedule them during low-carbon hours. That single change reduced our carbon footprint by 23% for nightly document processing jobs — with zero accuracy or cost impact.
Is 6.3 tons of CO2 annually going to save the planet? No. But multiply this by thousands of companies running AI workloads at scale, and the impact compounds. More practically, these optimizations made our system faster, cheaper, and more accurate. Sustainability was the bonus, not the trade-off.
What Didn't Work: Honest Failures
Three Dead Ends — So You Don't Have to Revisit Them
1. Aggressive Response Caching
We thought caching responses for similar queries would save enormous tokens. In practice, cache hit rate was 4%. User queries are too diverse and too contextual. The overhead of maintaining the cache exceeded the savings. We killed it after two weeks.
2. Routing Everything to Smaller Models
We tried sending all requests to GPT-3.5 instead of GPT-4. Token costs dropped 90%. Retry rate increased 340% — because users weren't satisfied with initial responses. Paying for quality upfront is cheaper than paying for retries. Every time.
3. Blanket Token Limits Without Classification
Before per-request-type budgets, we tried a flat 500-token limit on everything. Users revolted. Code generation got cut off mid-function. Contract analysis was unusable. Intelligent limits beat arbitrary ones. Always classify first.
Implementation Roadmap: Where to Start
8-Week Rollout Plan
WEEK 1
Baseline audit. Measure current token consumption by feature, user tier, and request type. You cannot optimize what you don't measure. Add per-feature attribution to your existing observability stack first.
WEEK 2
Prompt optimization. Highest ROI of any pattern. Audit your 10 most-used prompts, cut ruthlessly, A/B test on 5K+ requests to confirm no quality loss. Expect 50–80% token reduction from prompts alone.
WEEK 3
Token budgets. Set max_tokens per request type based on P95 of historical output length. Stops runaway costs immediately with minimal user impact.
WEEKS 4–6
Context pruning (RAG only). Implement two-stage relevance ranking. Add BM25 scoring alongside your existing vector search. Expect 60–80% context reduction and measurable accuracy gains.
WEEKS 6–8
Streaming early termination. Build satisfaction scoring for factual and procedural queries. Start conservatively (threshold: 0.90) and tune down as you gather production data.
ONGOING
Carbon monitoring. Add CO₂ metrics to dashboards. Consider scheduling batch jobs during low-carbon grid hours via the Electricity Maps API. Free wins on an already-optimized system.
Efficiency as an Engineering Discipline
Token optimization isn't about being cheap. It's about being intentional. Every token you generate costs money, burns carbon, and adds latency. When you treat tokens as a constrained resource — like CPU cycles or memory — you build better systems.
These patterns aren't novel. Ruthless efficiency has been a software engineering principle since resources were measured in kilobytes. What's new is applying that discipline to AI systems where token costs are invisible until suddenly they're not — usually when your finance team asks an embarrassing question during a quarterly review.
Our results — 89% reduction in consumption, $1.35M annual savings, 6.3 tons of CO2 avoided — came from treating token efficiency as a first-class architectural concern. Not an afterthought. We measured, experimented, failed, and iterated. The environmental impact is real but secondary. Fast, predictable, cost-effective AI systems are the primary goal. Sustainability follows naturally from good engineering.
If you're processing millions of tokens daily and haven't optimized your prompts, you're leaving money and carbon on the table. Start with the baseline audit. You'll be shocked at the waste. Then chip away systematically. Every million tokens saved is roughly $40 in your pocket and half a kilogram of CO2 out of the atmosphere.
That's the hidden cost of AI tokens. The good news? It's entirely within your control to fix.
Opinions expressed by DZone contributors are their own.
Comments