KV Caching: The Hidden Speed Boost Behind Real-Time LLMs
LLMs slow down as outputs grow due to repeated attention over past tokens. KV caching skips redundant work by reusing keys and values, enabling 3–4× faster inference.
Join the DZone community and get the full member experience.
Join For FreeIntroduction: Why LLM Performance Matters
Ever notice how your AI assistant starts snappy but then… starts dragging or slowing down?
It’s not just you. That slowdown is baked into how large language models (LLMs) work. Most of them generate text one token at a time using something called autoregressive decoding. And here's the catch - the longer the response gets, the more work the model has to do at every step. So the lag adds up.
Now, picture that in practice:
- You're chatting with a support bot, and suddenly, it’s taking forever to reply.
- Your code autocompleter starts lagging just when you're in flow.
- A voice assistant pauses awkwardly mid-response.
It's not a great experience. And under the hood, it’s expensive, as every second of delay burns more GPU (or any Hardware) time, energy, and money.
So Why Does This Happen?
The model isn’t just thinking about the next word. It’s reprocessing all the previous words as well, over and over. Like re-checking your notes, from the beginning, every time you want to add a word to your output.
This isn’t just inefficient. It’s unnecessary.
That’s where KV caching comes in. It is a surprisingly simple idea that changes everything. Instead of redoing all that past computation, we cache what we’ve already seen and reuse it. The results are dramatic.
In this article, I’ll walk through:
- Why do LLMs rely on transformers in the first place?
- How does decoding one token at a time slow things down?
- What does the attention mechanism do, and how do keys and values become the bottleneck?
- And finally, how KV Caching speeds things up without cutting corners?
In real-world deployments, flipping on KV caching can mean generating four times faster, with no drop in quality. With the same model and hardware.
Let’s start by peeling back the layers on transformers, an engine that powers almost every LLM out there.
What Are LLMs and Why Do They Use Transformers?
Large language models, or LLMs, are just giant neural networks trained to predict the next word. That’s it. But the way they do that prediction is where the magic happens.
I will try not to go too deep into the architecture, as you can find many other articles on this topic. Instead of using traditional architectures like RNNs (recurrent neural networks) or LSTMs (Long Short Term Memory), modern LLMs rely almost entirely on something called the Transformer. It’s the same architecture behind models like GPT, Claude, Mistral, and even BERT.
So why did Transformers take over? Because they’re really good at two things.
- One, they process input in parallel during training, which makes them fast to train even at scale.
- Two, they use a mechanism called attention, which lets the model look at every part of the input when deciding what to say next. I will talk more about this later.
A transformer is a stack of attention blocks that each take in some data, mix it around in a clever way, and pass it forward. Inside each block, there are components for computing queries, keys, and values. These play a huge role in the attention step, which we’ll get into soon.
But here's the twist. Even though transformers are fast at training, they slow down at inference. During training, you can process thousands of tokens in parallel. But at inference time, you can only predict one token at a time. And that’s where things start to break down.
We’ll unpack that next.
From Transformers to Autoregressive Decoding
Transformers are fast to train because they look at everything at once. But that’s not how they run inference.
When generating text, language models can’t predict all tokens in parallel. They have to go one token at a time, in a simple case. That’s what we call autoregressive decoding.
- At step one, the model sees the prompt and predicts the first token.
- At step two, it sees the prompt plus the first token and predicts the second.

The key idea here is that each new token depends on everything before it. So, generation becomes a sequential process, even though the model was trained with parallelism.
As I said earlier, the longer the sequence gets, the more computation it takes to generate the next token.
How Attention Works
Let’s take a moment to unpack the attention mechanism. It’s the beating heart of the transformer. Please read this paper for a detailed explanation.
Each token gets turned into three vectors: Query (Q), Key (K), and Value (V).
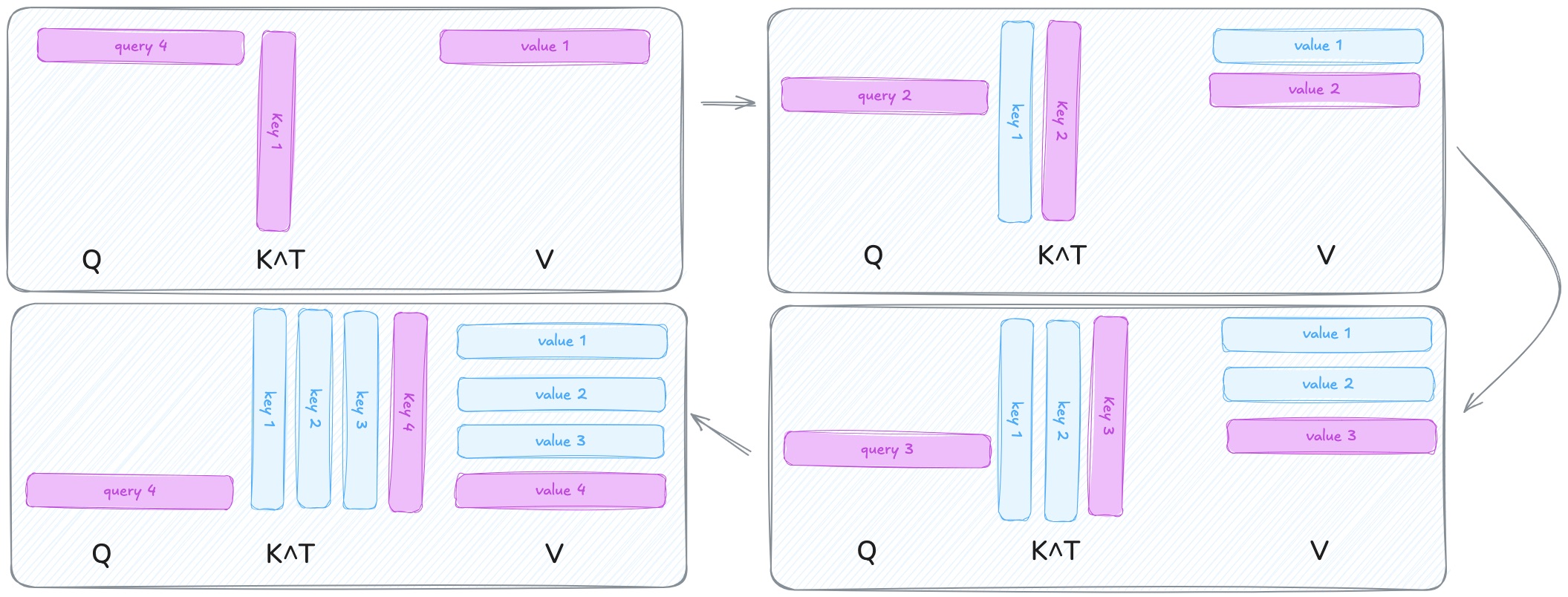
At each step, the model compares the current query to all the keys from previous tokens. It calculates a score for how relevant each past token is, and then uses those scores to weight the values. That’s how attention decides what to focus on.
Here’s what that looks like in code:
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(q, k, v):
d_k = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1)) / d_k**0.5
weights = F.softmax(scores, dim=-1)
return torch.matmul(weights, v)This mechanism is powerful because it lets the model dynamically decide which parts of the context to pay attention to. But there’s a catch.
At every step, the model needs to recompute the attention scores using all previous keys and values. That adds up quickly.
KV Caching: Let’s Avoid Repeated Computations
By now, you’ve seen the core problem: each new token requires computing attention with all previous tokens. That means more keys, more values, and more compute. It’s linear memory, quadratic time.
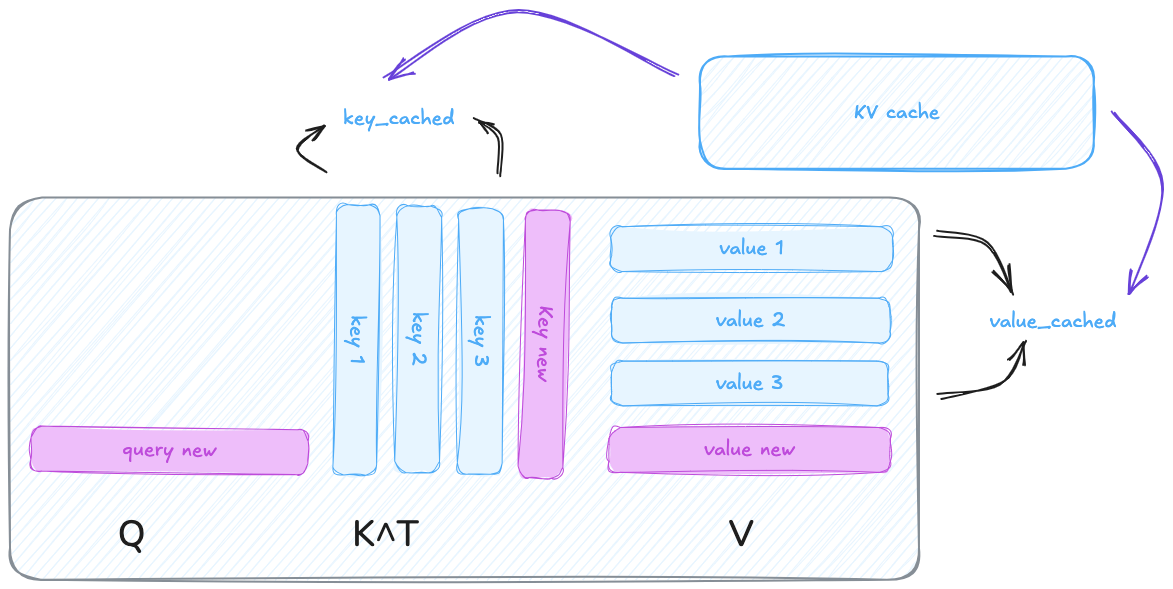
But here’s the trick: you don’t need to recompute keys and values for tokens you’ve already seen.
Instead, you cache them once and reuse them at every step.
That’s KV Caching in a nutshell.
How It Works
- At each decoding step, you compute Q for the new token only.
- You reuse K and V from the past, pulled from a cache.
- Attention becomes: Q_t x [cached K], followed by a weighted sum with [cached V].
No re-encoding. No reprocessing. Just fetch and multiply.
This turns a quadratic-time attention loop into something close to linear, especially when combined with tricks like FlashAttention and paged KV memory.
How does this look in code?
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(q, k, v):
d_k = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1)) / d_k**0.5
weights = F.softmax(scores, dim=-1)
return torch.matmul(weights, v)
# Simulate a decoding loop with KV caching
past_k = []
past_v = []
for t in range(seq_len): # decoding loop
token_t = input_tokens[:, t] # (batch,)
# Embed and project current token
x_t = embedding(token_t) # (batch, d_model)
q_t = query_proj(x_t) # (batch, d_k)
k_t = key_proj(x_t) # (batch, d_k)
v_t = value_proj(x_t) # (batch, d_v)
# Cache K and V
past_k.append(k_t)
past_v.append(v_t)
# Stack all past K and V
k_stack = torch.stack(past_k, dim=1) # (batch, t+1, d_k)
v_stack = torch.stack(past_v, dim=1) # (batch, t+1, d_v)
# Compute attention only with current Q and cached K,V
q_t = q_t.unsqueeze(1) # (batch, 1, d_k)
out_t = scaled_dot_product_attention(q_t, k_stack, v_stack)
# Generate token logits or continue loop...Speedup numbers from real-world experiments
| model | gpu | without kv cache | with kv Cache | Speedup |
|---|---|---|---|---|
|
GPT-2 (1.5B) |
A100 |
12 tok/sec |
45 tok/sec |
3.75x |
|
GPT-J (6B) |
A100 |
5 tok/sec |
20 tok/sec |
4x |
|
Mistral-7B |
L4 |
4.2 tok/sec |
14.6 tok/sec |
3.5x |
|
LLaMA 13B |
A100 |
~6 tok/sec |
~25 tok/sec |
4.1x |
When You Should Care
Let’s zoom out. KV caching sounds like a low-level optimization, but it’s not. It’s a fundamental performance unlock that powers almost every real-time LLM deployment today.
Where It Matters Most
- Chatbots that handle long conversations (ChatGPT, Claude, etc.)
- Code copilots like GitHub Copilot, Cursor, and TabNine
- Voice assistants, translators, and auto-completers
- Any application with long prompts or long outputs
If you're building tools that generate tokens sequentially, you should assume KV caching is essential. Not optional.
When It Doesn’t Matter (Much)
- One-shot inference with short outputs
- Non-autoregressive tasks (like classification or embedding extraction)
- Training time (training already uses parallel attention)
Final Thought
KV caching isn’t a niche trick. It’s what separates a working prototype from a real product.
Opinions expressed by DZone contributors are their own.
Comments