Dive Into Tokenization, Attention, and Key-Value Caching
This article covers how key-value caching works and how it helps optimize large language models. It includes a text generation process to make it easy to understand.
Join the DZone community and get the full member experience.
Join For FreeThe Rise of LLMs and the Need for Efficiency
In recent years, large language models (LLMs) such as GPT, Llama, and Mistral have impacted natural language understanding and generation. However, a significant challenge in deploying these models lies in optimizing their performance, particularly for tasks involving long text generation. One powerful technique to address this challenge is key-value caching (KV cache).
In this article, we will delve into how KV caching works, its role within the attention mechanism, and how it enhances efficiency in LLMs.
How Large Language Models Generate Text
To truly understand token generation, we need to start with the basics of how sentences are processed in LLMs.
Step 1: Tokenization
Before a model processes a sentence, it breaks it into smaller pieces called tokens.
Example sentence: Why is the sky blue?
Tokens can represent words, subwords, or even characters, depending on the tokenizer used.
For simplicity, let’s assume the sentence is tokenized as:['Why', 'is', 'the', 'sky', 'blue', '?']
Each token is assigned a unique ID, forming a sequence like:[1001, 1012, 2031, 3021, 4532, 63]
Step 2: Embedding Lookup
Token IDs are mapped to high-dimensional vectors, called embeddings, using a learned embedding matrix.
Example:
- Token “Why” (ID: 1001) → Vector:
[-0.12, 0.33, 0.88, ...] - Token “is” (ID: 1012) → Vector:
[0.11, -0.45, 0.67, ...]
The sentence is then represented as a sequence of embedding vectors:[Embedding("Why"), Embedding("is"), Embedding("the"), ...]
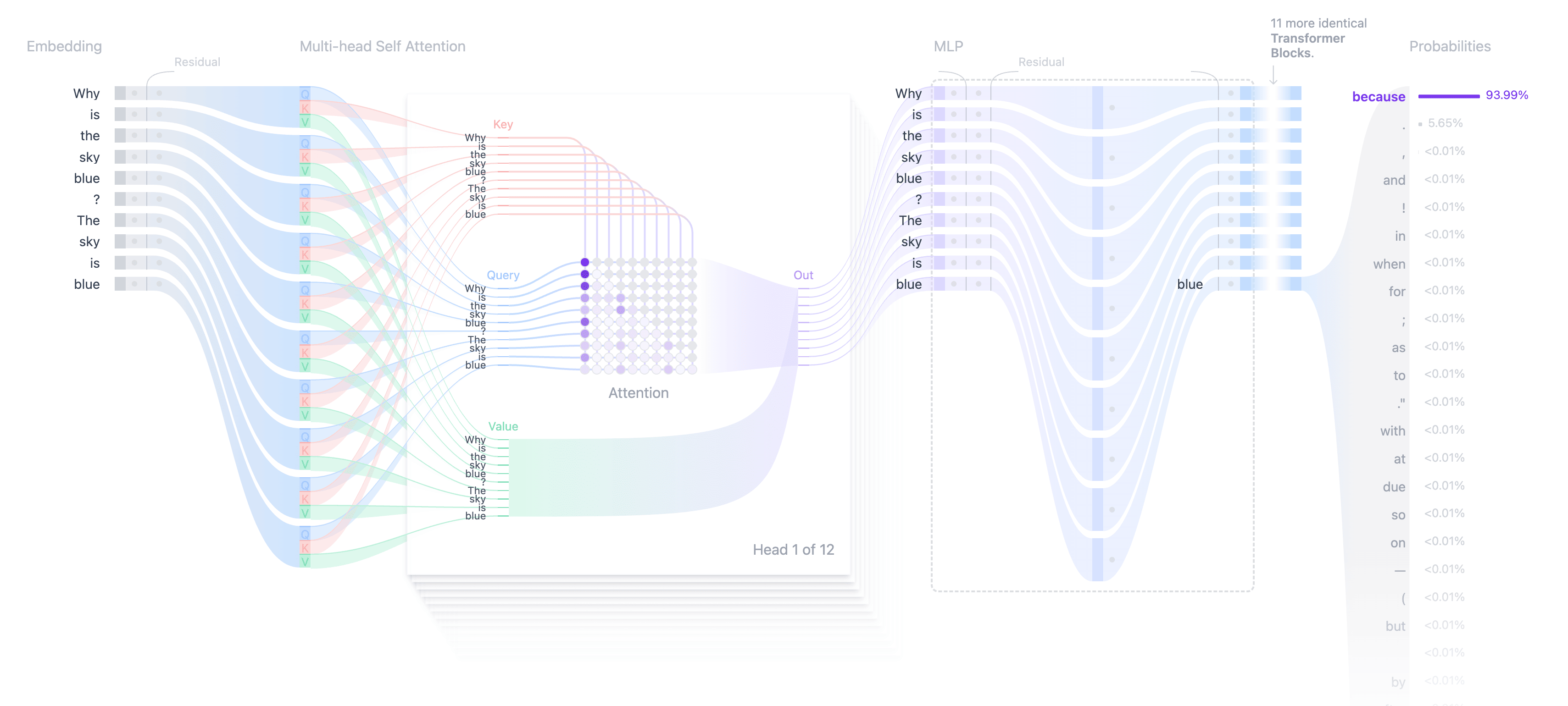
Step 3: Contextualizing Tokens With Attention
Raw embeddings don’t capture context. For instance, the meaning of “sky” differs in the sentences “Why is the sky blue?” and “The sky is clear today.” To add context, LLMs use the attention mechanism.
How Attention Works: (Keys, Queries, and Values)
The attention mechanism uses three components:
- Query (Q). Represents the current token’s embedding, transformed through a learned weight matrix. It determines how much attention to give to other tokens in the sequence.
- Key (K). Encodes information about each token (including previous ones), transformed through a learned weight matrix. It is used to assess relevance by comparing it to the query (Q).
- Value (V). Represents the actual content of the tokens, providing the information that the model “retrieves” based on the attention scores.
Example: Let's consider the LLM processing the sentence in the example, and the current token is“the.”
When processing the token “the,” the model attends to all previously processed tokens (“Why,” “is,” “the”) using their key (K) and value (V) representations.
Query (Q) for “the”:
The Query vector for “the” is derived by applying a learned weight matrix to its embedding:Q("the") = WQ ⋅ Embedding("the")
Keys (K) and Values (V) for previous tokens:
Each previous token generates:
- Key (K):
K("why") = WK ⋅ Embedding("why") - Value (V):
V("why") = Embedding("why")
Attention Calculation
The model calculates relevance by comparing Q (“the”) with all previous K vectors (“why”, “is”, and “the”) using a dot product.
The resulting scores are normalized with softmax to compute attention weights.
These weights are applied to the corresponding V vectors to update the contextual representation of “the.”
In summary:
- Q (the). The embedding of “the” passed through a learned weight matrix WQ to form the query vector Q for the token “the.” This query is used to determine how much attention “the” should pay to other tokens.
- K (why). The embedding of “why,” passed through a learned weight matrix WK to form the key vector K for “why.” This key is compared with Q (the) to compute attention relevance.
- V (why). The embedding of “why,” passed through a learned weight matrix WV to form the value vector V for “why.” This value contributes to updating the contextual representation of “the” based on its attention weight relative to Q (the).
Step 4: Updating the Sequence
Each token’s embedding is updated based on its relationships with all other tokens. This process is repeated across multiple attention layers, with each layer refining the contextual understanding.
Step 5: Generating the Next Token (Sampling)
Once embeddings are contextualized across all layers, the model outputs a logits vector — a raw score distribution over the vocabulary — for each token position.
For text generation, the model focuses on the logits for the last position. The logits are converted into probabilities using a softmax function.
Sampling Strategies
- Greedy sampling. Selects the token with the highest probability (in the image above, it uses greedy sampling and selects “because”).
- Top-k sampling. Chooses randomly among the top k probable tokens.
- Temperature sampling. Adjusts the probability distribution to control randomness (e.g., higher temperature = more random choices).
How Key-Value Cache Helps
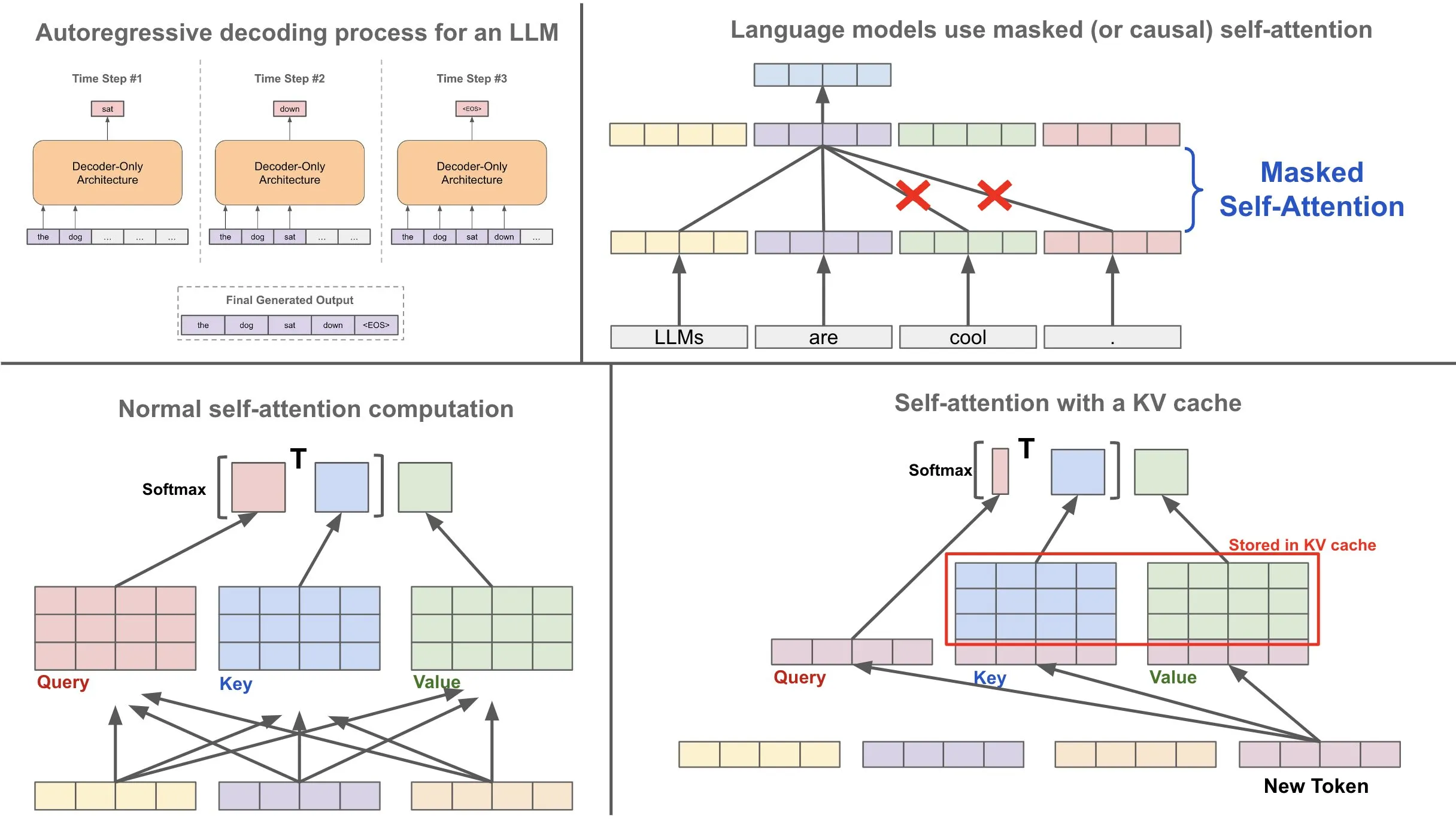
Without a KV Cache
At each generation step, the model recomputes the keys and values for all tokens in the sequence, even those already processed. This results in a quadratic computational cost (O(n²)), where n is the number of tokens, making it inefficient for long sequences.
With a KV Cache
The model stores the keys and values for previously processed tokens in memory. When generating a new token, it reuses the cached keys and values, and computes only the key, value, and query for the new token. This optimization significantly reduces the need for recalculating attention components for the entire sequence, improving both computational time and memory usage.
Code With KV Cache
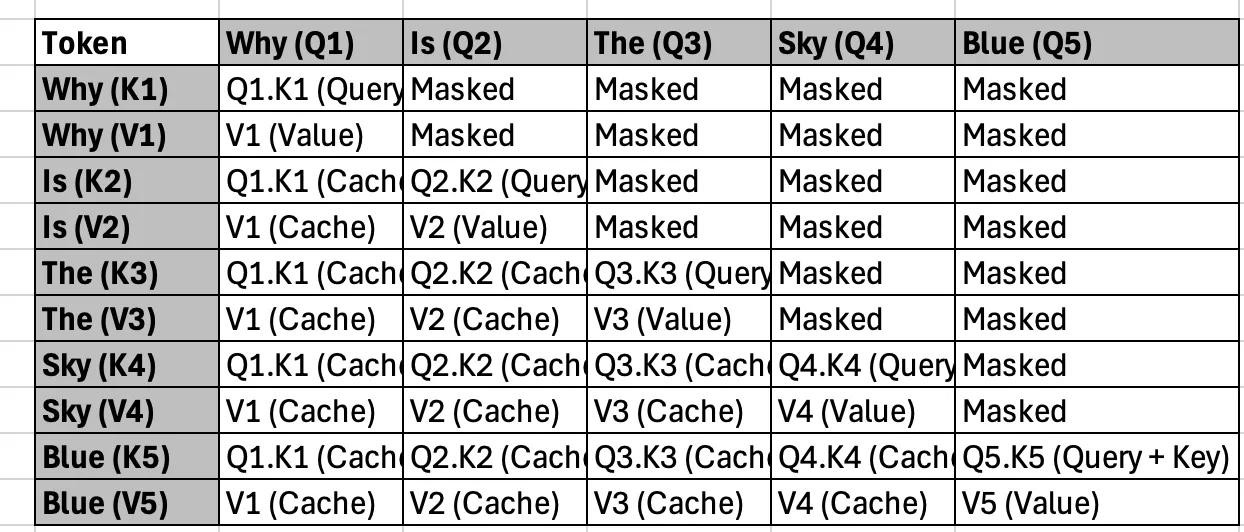
Suppose the model has already generated the sequence “Why is the sky.” The keys and values for these tokens are stored in the cache. When generating the next token, “blue”:
- The model retrieves the cached keys and values for the tokens “Why,” “is,” “the,” and “sky.”
- It computes the query, key, and value for “blue” and performs attention calculations using the query for “blue” with the cached keys and values.
- The newly calculated key and value for “blue” are added to the cache for future use.
import torch
import time
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-1B")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-1B")
# Move model to the appropriate device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Input text
input_text = "Why is the sky blue?"
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(device)
def generate_tokens(use_cache, steps=100):
"""
Function to generate tokens with or without caching.
Args:
use_cache (bool): Whether to enable cache reuse.
steps (int): Number of new tokens to generate.
Returns:
generated_text (str): The generated text.
duration (float): Time taken for generation.
"""
past_key_values = None # Initialize past key values
input_ids_local = input_ids # Start with initial input
generated_tokens = tokenizer.decode(input_ids_local[0]).split()
start_time = time.time()
for step in range(steps):
outputs = model(
input_ids=input_ids_local,
use_cache=use_cache,
past_key_values=past_key_values,
)
logits = outputs.logits
past_key_values = outputs.past_key_values if use_cache else None # Cache for next iteration
# Get the next token (argmax over logits)
next_token_id = torch.argmax(logits[:, -1, :], dim=-1)
# Decode and append the new token
new_token = tokenizer.decode(next_token_id.squeeze().cpu().numpy())
generated_tokens.append(new_token)
# Update input IDs for next step
if use_cache:
input_ids_local = next_token_id.unsqueeze(0) # Only the new token for cached mode
else:
input_ids_local = torch.cat([input_ids_local, next_token_id.unsqueeze(0)], dim=1)
end_time = time.time()
duration = end_time - start_time
generated_text = " ".join(generated_tokens)
return generated_text, duration
# Measure time with and without cache
steps_to_generate = 200 # Number of tokens to generate
print("Generating tokens WITHOUT cache...")
output_no_cache, time_no_cache = generate_tokens(use_cache=False, steps=steps_to_generate)
print(f"Output without cache: {output_no_cache}")
print(f"Time taken without cache: {time_no_cache:.2f} seconds\n")
print("Generating tokens WITH cache...")
output_with_cache, time_with_cache = generate_tokens(use_cache=True, steps=steps_to_generate)
print(f"Output with cache: {output_with_cache}")
print(f"Time taken with cache: {time_with_cache:.2f} seconds\n")
# Compare time difference
time_diff = time_no_cache - time_with_cache
print(f"Time difference (cache vs no cache): {time_diff:.2f} seconds")When Is Key-Value Caching Most Effective?
The benefits of KV cache depend on several factors:
- Model size. Larger models (e.g., 7B, 13B) perform more computations per token, so caching saves more time.
- Sequence length. KV cache is more effective for longer sequences (e.g., generating 200+ tokens).
- Hardware. GPUs benefit more from caching compared to CPUs, due to parallel computation.
Extending KV Cache: Prompt Caching
While KV cache optimizes text generation by reusing keys and values for previously generated tokens, prompt caching goes a step further by targeting the static nature of the input prompt. Let’s explore what prompt caching is and its significance.
What Is Prompt Caching?
Prompt caching involves pre-computing and storing the keys and values for the input prompt before the generation process starts. Since the input prompt does not change during text generation, its keys and values remain constant and can be efficiently reused.
Why Prompt Caching Matters
Prompt caching offers distinct advantages in scenarios with large prompts or repeated use of the same input:
- Avoids redundant computation. Without prompt caching, the model recalculates the keys and values for the input prompt every time it generates a token. This leads to unnecessary computational overhead.
- Speeds up generation. By pre-computing these values once, prompt caching significantly accelerates the generation process, particularly for lengthy input prompts or when generating multiple completions.
- Optimized for batch processing. Prompt caching is invaluable in cases where the same prompt is reused across multiple batched requests or slight variations, ensuring consistent efficiency.
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model and tokenizer
model_name = "mistralai/Mistral-7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16)
assistant_prompt = "You are a helpful and knowledgeable assistant. Answer the following question thoughtfully:\n"
# Tokenize the assistant prompt
input_ids = tokenizer(assistant_prompt, return_tensors="pt").to(model.device)
# Step 1: Cache Keys and Values for the assistant prompt
with torch.no_grad():
start_time = time.time()
outputs = model(input_ids=input_ids.input_ids, use_cache=True)
past_key_values = outputs.past_key_values # Cache KV pairs for the assistant prompt
prompt_cache_time = time.time() - start_time
print(f"Prompt cached in {prompt_cache_time:.2f} seconds\n")
# Function to generate responses for separate questions
def generate_response(question, past_key_values):
question_prompt = f"Question: {question}\nAnswer:"
question_ids = tokenizer(question_prompt, return_tensors="pt").to(model.device)
# Append question tokens after assistant cached tokens
input_ids_combined = torch.cat((input_ids.input_ids, question_ids.input_ids), dim=-1)
generated_ids = input_ids_combined # Initialize with prompt + question
num_new_tokens = 50 # Number of tokens to generate
with torch.no_grad():
for _ in range(num_new_tokens):
outputs = model(input_ids=generated_ids, past_key_values=past_key_values, use_cache=True)
next_token_id = outputs.logits[:, -1].argmax(dim=-1).unsqueeze(0) # Pick next token
generated_ids = torch.cat((generated_ids, next_token_id), dim=-1) # Append next token
past_key_values = outputs.past_key_values # Update KV cache
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
return response, past_key_values
# Step 2: Pass multiple questions
questions = [
"Why is the sky blue?",
"What causes rain?",
"Why do we see stars at night?"
]
# Generate answers for each question
for i, question in enumerate(questions, 1):
start_time = time.time()
response, past_key_values = generate_response(question, past_key_values)
response_time = time.time() - start_time
print(f"Question {i}: {question}")
print(f"Generated Response: {response.split('Answer:')[-1].strip()}")
print(f"Time taken: {response_time:.2f} seconds\n")For example:
- Customer support bots. The system prompt often remains unchanged for every user interaction. prompt caching allows the bot to generate responses efficiently without recomputing the keys and values of the static system prompt.
- Creative content generation. When multiple completions are generated from the same input prompt, varying randomness (e.g., temperature settings) can be applied while reusing cached keys and values for the input.
Conclusion
Key-value caching (KV vache) plays a crucial role in optimizing the performance of LLMs. Reusing previously computed keys and values reduces computational overhead, speeds up generation, and improves efficiency, particularly for long sequences and large models.
Implementing KV caching is essential for real-world applications like summarization, translation, and dialogue systems, enabling LLMs to scale effectively and provide faster, more reliable results. Combined with techniques like prompt caching, KV cache ensures that LLMs can handle complex and resource-intensive tasks with improved efficiency.
I hope you found this article useful, and if you did, consider giving claps.
Opinions expressed by DZone contributors are their own.
Comments