90% Cost Reduction With Prefix Caching for LLMs
Up to 70% of prompts in LLM applications are repetitive. Prefix caching can reduce inference costs by up to 90%, thus optimizing performance and saving money.
Join the DZone community and get the full member experience.
Join For Free
Do you know there’s a technique by which you could slash your LLM inference cost by up to 90%? Prefix caching is the idea that could save your application those much needed dollars. A game changing optimization technique that is not just for giants like Anthropic but also available to anyone using open- source LLMs.

Let's pull back the curtain on this technique!
Ever waited too long for ChatGPT to respond? You're not alone.
Here's a shocking truth: Of all the prompts in an LLM application, up to 70% of prompts are repetitive or similar. Every time someone asks, "What's the weather?" or "Translate this to French," or "Gifting ideas for mom," we're burning compute power processing nearly identical prompts. But it gets worse — in distributed systems, these redundant computations are multiplicative. Each node in the distributed cluster might be processing the same prompt patterns thousands of times per hour. You are bleeding money.
A while back, Anthropic elaborated on how they utilize prompt caching to lower inference costs by 90%. This was partly the reason some developers were eager to test this functionality in Claude. Numerous open-source LLM runtimes, such as vLLM, TRT-LLM, and SGLang, feature automatic prefix caching, also known as context caching. In this feature, input prompts across requests that have a common prefix will be automatically cached.
How Does Prefix Caching Work?
To better understand prefix caching, we first need to pay attention to how LLM inference works.
On a high level, it involves two steps:
- Process the given input token sequence in a forward pass. This is called the prefill phase.
- In the decode phase, the output tokens are generated in succession from first to last, where the current token will be dependent on the last token.
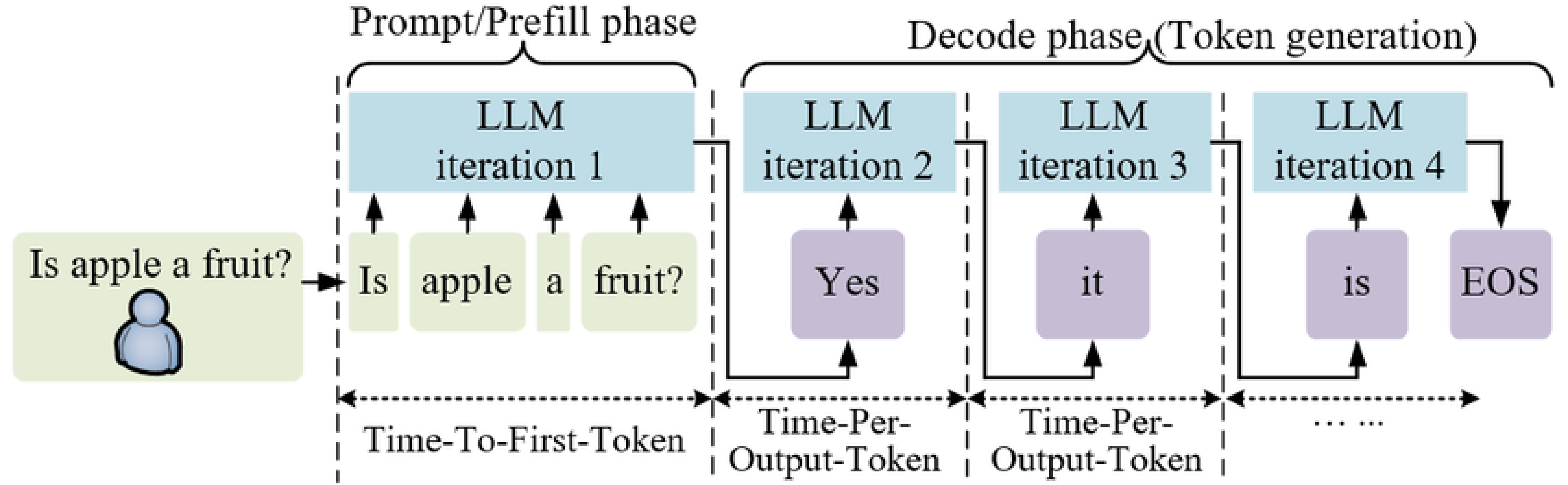
Since the process is autoregressive (dependence of new tokens on previous tokens), effective memory management is important. This has led to the general practice of KV caching the intermediate states. It differs from simple prompt or semantic caching in that it does not place full-text input and output into the database, where only exact matches (or near identical queries) get the benefit of hitting the cache and receiving the response immediately.
During the prefill phase, when an LLM processes tokens, it computes "attention," i.e., how each token relates to others. These computations produce key and value matrices for each token. Without any KV caching, these would need to be recomputed every time the model looks back at previous tokens. KV caching was developed with the intention of being able to function just for one generation, meaning that it would only capture intermediate states in the process of generating one output.
What if I Have Two Requests That Have Identical Prefixes?
This idea of KV caching has metamorphosed into prefix caching, where such states are stored and can be used when generating different responses to the prompts that contain the same prefix. For a simple analogy, consider how you would compute 2 * 6 * 3 * 5 once you have already computed 2 * 6. You would simply just reuse the computation of 2 * 6 rather than recalculating it every time you need it in the sequence.
How Does This Help My Application?
We can use the following best practices to get the most out of prefix caching capability:
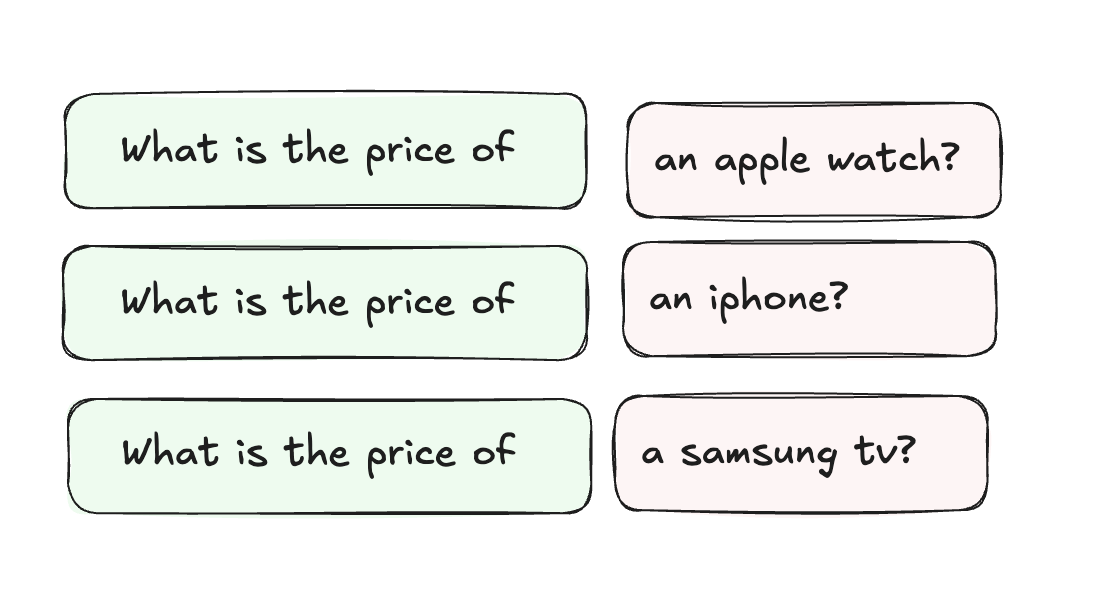
Strategic Prompt Structure
Place constant elements like system prompts, base instructions, or shared context at the beginning of the prompt (Fig. 2). This creates a foundation that is reusable for multiple queries. Any dynamic or specific content can be placed towards the end.
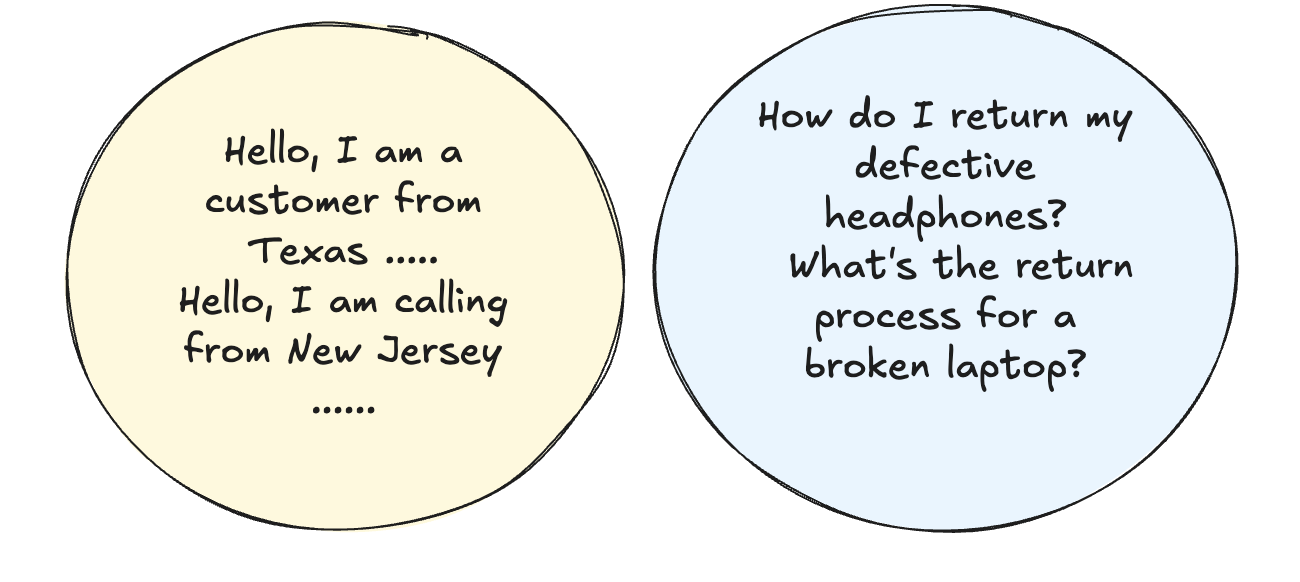
Re-grouping Requests
Bundle together requests (Fig. 3) that share a common structure/prefix. For instance, if you are processing multiple customer queries that start with common greetings or salutations, it might be beneficial to put them together since computations can be cached and reused.
Monitor Cache Utilization
Implement robust monitoring of cache utilization metrics.
Track hit and miss rates:
- To figure out what prefixes are more prominent than others
- Identify patterns in cache misses
Use these insights to refine your prompt structures for optimal performance.
A Quick Example
The example below shows how prefix caching can optimize LLM inference when multiple queries share the same context. We'll use a simple employee database table and make different queries about its contents.
import time
from vllm import LLM, SamplingParams
# A small table containing employee information
LONG_PROMPT = """You are a helpful assistant that recognizes content in markdown tables. Here is the table:
| ID | Name | Department | Salary | Location | Email |
|----|---------------|------------|---------|-------------|---------------------|
| 1 | Alice Smith | Engineering| 85000 | New York | [email protected] |
| 2 | Bob Johnson | Marketing | 65000 | Chicago | [email protected] |
| 3 | Carol White | Sales | 75000 | Boston | [email protected] |
| 4 | David Brown | Engineering| 90000 | Seattle | [email protected] |
| 5 | Eve Wilson | Marketing | 70000 | Austin | [email protected] |
"""
def get_generation_time(llm, sampling_params, prompts):
start_time = time.time()
output = llm.generate(prompts, sampling_params=sampling_params)
end_time = time.time()
print(f"Output: {output[0].outputs[0].text}")
print(f"Generation time: {end_time - start_time:.2f} seconds")
# Initialize LLM with prefix caching enabled
llm = LLM(
model='lmsys/longchat-13b-16k',
enable_prefix_caching=True
)
sampling_params = SamplingParams(temperature=0, max_tokens=50)
# First query - will compute and cache the table
get_generation_time(
llm,
sampling_params,
LONG_PROMPT + "Question: What is Alice Smith's salary? Your answer: Alice Smith's salary is "
)
# Second query - will reuse the cached table computation
get_generation_time(
llm,
sampling_params,
LONG_PROMPT + "Question: What is Eve Wilson's salary? Your answer: Eve Wilson's salary is "
)Run this code to see the actual time difference between queries. The second query should be notably faster as it reuses the cached table context. Actual timings will vary based on your hardware and setup.
Conclusion
Prefix caching surfaces as a powerful optimization technique for LLM applications. Implementing the best practices outlined above will allow developers to significantly reduce inference costs without hampering the response quality. The practical example demonstrates how easy it is to start leveraging this technique in your own applications today.
Opinions expressed by DZone contributors are their own.
Comments