Talk to Your Project: An LLM Experiment You Can Join and Build On
Find out the result of my experiment on integrating LLM into a console application and the insights I gained from the experience.
Join the DZone community and get the full member experience.
Join For FreeToday, I want to share the story of a small open-source project I created just for fun and experimentation — ConsoleGpt. The process, results, and overall experience turned out to be fascinating, so I hope you find this story interesting and, perhaps, even inspiring. After all, I taught my project how to understand spoken commands and do exactly what I want.
This story might spark new ideas for you, encourage your own experiments, or even motivate you to build a similar project. And of course, I'd be thrilled if you join me in developing ConsoleGpt — whether by contributing new features, running it locally, or simply starring it on GitHub. Anyone who's ever worked on an open-source project knows how much even small support means.
Enough with the preamble — let's dive into the story!
The Idea
When large language models (LLMs) first emerged, my immediate question was, what can we build using them? It was clear that their potential applications were virtually limitless — constrained only by imagination and willingness to experiment.
One evening, while reflecting on their capabilities, I came up with a curious idea: what if I could teach my project to talk to me in a common language? Imagine simply describing a task to it, and it would automatically execute the necessary steps. That's how the idea for ConsoleGpt was born. This happened about a year and a half ago, long before LLM-based agents became a hot topic among developers and users. Even now, I believe this experiment remains relevant and valuable in terms of the experience I gained while playing with it.

The Implementation
So, how do you establish communication between a programmer and their project? There are several options, but the most natural and intuitive one is, of course, the command-line interface (CLI). It's a familiar tool for developers and ideal for low-level interaction with software. That's when I decided my project would be a console application.
But what exactly would this application do? The obvious answer was to execute commands or even a series of commands, process their results, and present them in the desired format. The concept is simple: the programmer writes a request in natural language, the system interprets it, determines which console commands should be executed and in what order, and — if one command depends on the result of another — ensures they run sequentially, transforming the data as needed.
To bring this idea to life, I chose PHP. I've always appreciated its simplicity, flexibility, and the ease of creating tools, both simple and complex. For the console application framework, I selected the popular symfony/console library, which offers everything needed to work with CLI commands. This meant my project could be integrated into any other application using 'symfony/console,' making it not just an experiment but a potentially useful tool for other developers.
The console application serves as the interface, with commands acting as its building blocks. Here's how the process flows:
- The user enters a request in natural language.
- The system uses an LLM to process the request and to determine:
- Which commands need to be executed.
- The correct order for executing the commands.
- How to handle the results of each command to complete the task.
- The console application then executes the identified commands, returning the results to the LLM, which processes the output and presents it to the user in the required format.
LLM Choice
As mentioned earlier, I used PHP for development and 'symfony/console' as the foundation for the CLI application. For the language model, I opted for OpenAI's GPT models (GPT-3, GPT-4, etc.). The reasons for this were simple and practical:
Ease of Integration
OpenAI provides an accessible API with excellent documentation and a sandbox for testing. Additionally, there are numerous libraries for nearly every programming language that serve as wrappers for the API, simplifying interaction with the model.
For my project, I used the well-maintained openai-php/client library, which had all the necessary functionality. The model is closed-source, so I don't need to run it locally, spend a lot of time figuring out how it works, etc. Downsides include: it costs money (albeit relatively little), it is potentially unstable (the API might break or its format could change in the future), and potentially unreliable since I depend on a third-party service provider over whom I have no control. Additionally, I had to share data with OpenAI when interacting with their models. However, these downsides were not critical for the task at hand.
High-Quality Models
At the time of development, OpenAI's models were among the best general-purpose LLMs available — at least, that is what OpenAI and user reports suggested. My goal wasn't to find a niche solution or spend too much time fine-tuning. I simply wanted to quickly test whether it was possible to build a system that lets users "talk" to a program, and OpenAI's models were perfect for this.
Function Calling
Implementing my idea without this feature would have been extremely difficult. To execute specific console commands, I needed the model to return data in a precise format (i.e., the command name and its parameters). Without structured outputs, language models might produce incorrect or unexpected results, breaking the application. Function calling ensures that the output adheres to a predefined structure, logically separating user-addressed text from executable tasks.
In my project, each console command is represented as a function, with arguments and options serving as parameters. This setup allows ChatGPT to:
- Know what commands are available during a session.
- Understand the required parameters for each command.
- Automatically determine the sequence of command executions needed to achieve the desired outcome.
In addition to console command functions, I added several system functions, such as retrieving chat statistics, switching the language model in use, adjusting the context window size, and so on.
Project Structure
The project's structure is straightforward and modular, making it both maintainable and extensible. Here's a brief overview:
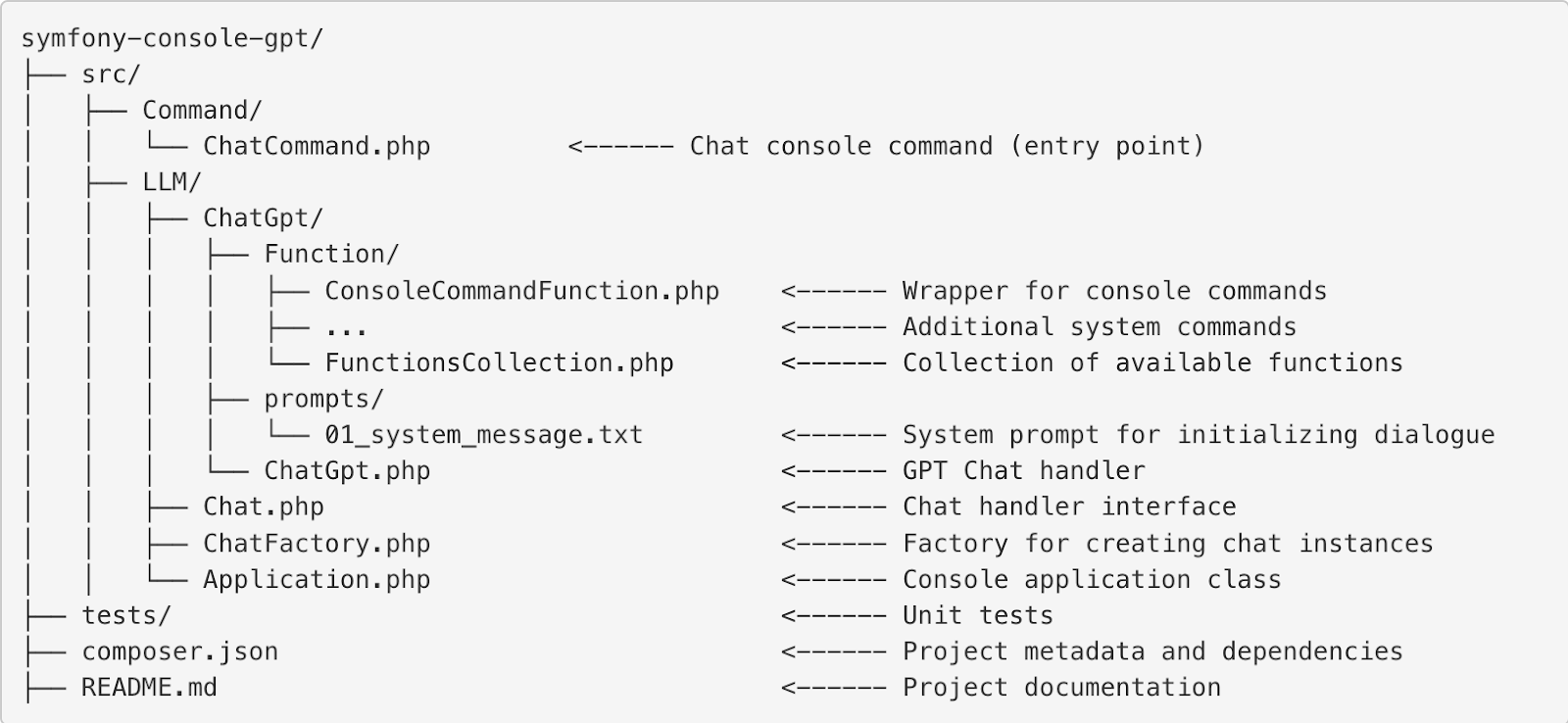
- Command directory contains the main console command, ChatCommand. It serves as the entry point for interacting with the console application. This command can be integrated into any existing application based on symfony/console either as a standalone command or used as the main project command through inheritance of the base Application class. This solution allows users to easily integrate ConsoleGpt functionality into their projects without complex configurations: it just works out of the box.
- LLM directory is responsible for all logic related to working with language models. It contains the Chat interface, which defines chat behavior, as well as the ChatFactory, which handles specific chats' creation. For example, the implementation for OpenAI models is located in the ChatGpt subdirectory, where the core functionality for interacting with the OpenAI API is concentrated.
- Functions for ChatGPT reside in the ChatGpt/Function subdirectory. A key element here is the ConsoleCommandFunction class, which acts as a wrapper for each console command. A collection of all functions is stored in FunctionsCollection, which is loaded when the chat starts and is used to generate requests to the language model. Additionally, this directory contains supplementary system commands, such as retrieving statistics, switching the language model, and other management tasks.
- In the ChatGpt/prompts subdirectory, there is a file named 'system_message.txt', which contains the system prompt used for initial configuration of the model's behavior and setting the context for processing user requests.
The project structure was designed with future expansion and support for other language models in mind. While the current implementation supports only OpenAI ChatGPT, using Chat interface and ChatFactory functionality makes adding other models a straightforward task (provided the issue of function calls in other solutions is resolved). This architecture ensures that the project is adaptable to various needs and offers flexibility and versatility.
Connecting the Chat to Your PHP Project
To integrate ConsoleGpt into your project, ensure the library is installed via Composer:
composer require shcherbanich/symfony-console-gptAfter installing the library, you can integrate ChatCommand into your console application using one of several methods. Let's look at the main options.
1. Adding the Command Using the add Method
The simplest approach is to add ChatCommand to the list of available commands using the add() method in your console application. This option is suitable for quickly incorporating the command into an existing console project.
<?php
use ConsoleGpt\Command\ChatCommand;
use Symfony\Component\Console\Application;
$application = new Application();
$application->add(new ChatCommand());
$application->run();2. Inheriting from the Base Application Class
If you want to make ChatCommand the core of your console application, you can inherit your application class from the base Application class provided by the library. This will automatically add ChatCommand to your application.
<?php
use ConsoleGpt\Application as ChatApplication;
final class SomeApp extends ChatApplication
{
// Add your custom logic if needed
}3. Using DI in Symfony
If your application is built with Symfony and uses the Dependency Injection (DI) mechanism, you can register the ChatCommand in services.yaml. This will allow Symfony to automatically recognize the command and make it available in your application.
To do this, add the following code to your services.yaml file:
services:
ConsoleGpt\Command\ChatCommand:
tags:
- { name: 'console.command', command: 'app:chat' }
After that, the command will be accessible in the console under the name app:chat. This approach is suitable for typical Symfony applications where all console commands are registered via the service container.
To run the application, you also need to set the environment variable OPENAI_API_KEY with your OpenAI API key. This key is used for authorizing requests to the model's API. You can obtain your key on the OpenAI API Keys page. There, you can also top up your balance if necessary and view usage statistics. You can set the environment variable on Linux/macOS by running the following command in the terminal:
export OPENAI_API_KEY=your_keyIf you use Windows, the command will need to look like this:
set OPENAI_API_KEY=your_keyThe Result
To test and debug the project, I created a demo application with several commands for managing the project. The results exceeded my expectations: the system worked exactly as intended and sometimes even better. The language model interpreted most requests accurately, invoked the appropriate commands, and clarified any missing information before executing the tasks in a correct manner. Here's a demo video. One of the most impressive aspects was the system's ability to handle complex command sequences, which I believe demonstrates the enormous potential of this approach.
My experiment became not only an interesting technical challenge but also a starting point for thinking about new products. I believe this solution can inspire other developers to create their own projects — whether based on my code or simply by applying the ideas I implemented. For this reason, I chose the MIT license, which offers maximum freedom of use. You can utilize this project as a foundation for your experiments, improvements, or products.
Here are a few thoughts on how this system, its individual components, or this idea could be used:
- Scientific research: If you're studying human-computer interaction or language model capabilities, this project could serve as a useful base for experiments and research.
- Building interactive interfaces for console applications: This solution transforms static console applications into dynamic and intuitive interfaces that can be trained to execute commands in natural language.
- Assistive technology for people with disabilities: By integrating a speech-to-text model, you can create a convenient tool for blind or visually impaired individuals or for those with motor impairments. With this approach, users could potentially interact with console applications using voice commands, greatly improving accessibility.
- Creating AI agents: This system can be used as a foundation for building fully functional AI agents. Since console commands can perform a wide range of tasks, like launching programs, processing data, interacting with external APIs, and more, this solution can be seen as a flexible framework for constructing powerful tools.
Lessons Learned
This experiment provided me with both positive insights and a clear view of certain limitations and potential risks. Here are the key takeaways:
- Anyone can сreate an LLM Agent very quickly. Building an LLM agent is a task that any developer can accomplish in just a few evenings. For example, I created the first working version of this project in a single evening. Even though the code was far from being perfect or optimized, it already delivered impressive results. This is inspiring because it shows that the technology is now accessible and open for experimentation.
- Humans can truly talk with code. This experiment confirmed that modern language models can be effectively used for interacting with programs. They excel at interpreting natural language queries and converting them into sequences of actions. This opens up significant opportunities for automation and improving user experience.
- GPT-3 performs just as well as GPT-4o for this task. It may sound surprising, but it is true. Recently, the improvement in model quality has become less apparent, raising the question: why pay more?
- Custom functionality is great but risky. Relying on the custom functions of language models carries risks. In my case, the application heavily depends on OpenAI's Function Calling feature. If the company decides to charge extra for its use, changes its behavior, or removes it entirely, the application will stop working. This highlights the inherent dependency on third-party tools when using external services.
- OpenAI's API optimization increases costs for users. I noticed that OpenAI's API is designed in a way that drives up user costs. For example, functions are billed at standard rates despite requiring excessive text transmission. Recently, OpenAI introduced a new feature called 'tools' that wraps functions but requires even more data to be transmitted for functionality to work. This increases the context size, which, in turn, raises the cost of each request. This issue is especially noticeable when executing complex sequences of console commands, where the context grows with each step, making requests progressively more expensive.
Final Thoughts
Despite the identified downsides and risks, I am satisfied with the results of this experiment. It demonstrated that even minimal effort can yield impressive results, and technologies like language models are genuinely transforming how software is developed. However, this experiment also served as a reminder of how important planning is and how careful we should be when accounting for potential limitations. This is especially true when considering such solutions for commercial or long-term projects.
Just to make sure, here is a link to the project's homepage on GitHub. Feel free to borrow, commit, and discuss it with me and the community!
Opinions expressed by DZone contributors are their own.
Comments