A Guide to Using Amazon Bedrock Prompts for LLM Integration
Easily integrate LLMs into your application, manage prompts effectively and leverage the latest in LLM application development with Amazon Bedrock.
Join the DZone community and get the full member experience.
Join For FreeAs generative AI revolutionizes various industries, developers increasingly seek efficient ways to integrate large language models (LLMs) into their applications. Amazon Bedrock is a powerful solution. It offers a fully managed service that provides access to a wide range of foundation models through a unified API. This guide will explore key benefits of Amazon Bedrock, how to integrate different LLM models into your projects, how to simplify the management of the various LLM prompts your application uses, and best practices to consider for production usage.
Key Benefits of Amazon Bedrock
Amazon Bedrock simplifies the initial integration of LLMs into any application by providing all the foundational capabilities needed to get started.
Simplified Access to Leading Models
Bedrock provides access to a diverse selection of high-performing foundation models from industry leaders such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon. This variety allows developers to choose the most suitable model for their use case and switch models as needed without managing multiple vendor relationships or APIs.
Fully Managed and Serverless
As a fully managed service, Bedrock eliminates the need for infrastructure management. This allows developers to focus on building applications rather than worrying about the underlying complexities of infrastructure setup, model deployment, and scaling.
Enterprise-Grade Security and Privacy
Bedrock offers built-in security features, ensuring that data never leaves your AWS environments and is encrypted in transit and at rest. It also supports compliance with various standards, including ISO, SOC, and HIPAA.
Stay Up-to-Date With the Latest Infrastructure Improvements
Bedrock regularly releases new features that push the boundaries of LLM applications and require little to no setup. For example, it recently released an optimized inference mode that improves LLM inference latency without compromising accuracy.
Getting Started With Bedrock
In this section, we’ll use the AWS SDK for Python to build a small application on your local machine, providing a hands-on guide to getting started with Amazon Bedrock. This will help you understand the practical aspects of using Bedrock and how to integrate it into your projects.
Prerequisites
- You have an AWS account.
- You have Python installed. If not installed, get it by following this guide.
- You have the Python AWS SDK (Boto3) installed and configured correctly. It's recommended to create an AWS IAM user that Boto3 can use. Instructions are available in the Boto3 Quickstart guide.
- If using an IAM user, ensure you add the
AmazonBedrockFullAccesspolicy to it. You can attach policies using the AWS console. - Request access to 1 or more models on Bedrock by following this guide.
1. Creating the Bedrock Client
Bedrock has multiple clients available within the AWS CDK. The Bedrock client lets you interact with the service to create and manage models, while the BedrockRuntime client enables you to invoke existing models. We will use one of the existing off-the-shelf foundation models for our tutorial, so we’ll just work with the BedrockRuntime client.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1') 2. Invoking the Model
In this example, I’ve used the Amazon Nova Micro model (with modelId amazon.nova-micro-v1:0), one of Bedrock's cheapest models. We’ll provide a simple prompt to ask the model to write us a poem and set parameters to control the length of the output and the level of creativity (called “temperature”) the model should provide. Feel free to play with different prompts and tune parameters to see how they impact the output.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'amazon.nova-micro-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"schemaVersion": "messages-v1",
"messages": [{"role": "user", "content": [{"text": "Write a short poem about a software development hero."}]}],
"inferenceConfig": {
"max_new_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)We can also try this with another model like Anthropic’s Haiku, as shown below.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'anthropic.claude-3-haiku-20240307-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": [{"type": "text", "text": "Write a short poem about a software development hero."}]}],
"max_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)Note that the request/response structures vary slightly between models. This is a drawback that we will address by using predefined prompt templates in the next section. To experiment with other models, you can look up the modelId and sample API requests for each model from the “Model Catalog” page in the Bedrock console and tune your code accordingly. Some models also have detailed guides written by AWS, which you can find here.
3. Using Prompt Management
Bedrock provides a nifty tool to create and experiment with predefined prompt templates. Instead of defining prompts and specific parameters such as token lengths or temperature in your code every time you need them, you can create pre-defined templates in the Prompt Management console. You specify input variables that will be injected during runtime, set up all the required inference parameters, and publish a version of your prompt. Once done, your application code can invoke the desired version of your prompt template.
Key advantages of using predefined prompts:
- It helps your application stay organized as it grows and uses different prompts, parameters, and models for various use cases.
- It helps with prompt reuse if the same prompt is used in multiple places.
- Abstracts away the details of LLM inference from our application code.
- Allows prompt engineers to work on prompt optimization in the console without touching your actual application code.
- It allows for easy experimentation, leveraging different versions of prompts. You can tweak the prompt input, parameters like temperature, or even the model itself.
Let’s try this out now:
- Head to the Bedrock console and click “Prompt Management” on the left panel.
- Click on “Create Prompt” and give your new prompt a name
- Input the text that we want to send to the LLM, along with a placeholder variable. I used
Write a short poem about a {{topic}}. - In the Configuration section, specify which model you want to use and set the values of the same parameters we used earlier, such as “Temperature” and “Max Tokens.” If you prefer, you can leave the defaults as-is.
- It's time to test! At the bottom of the page, provide a value for your test variable. I used “Software Development Hero.” Then, click “Run” on the right to see if you’re happy with the output.
For reference, here is my configuration and the results.
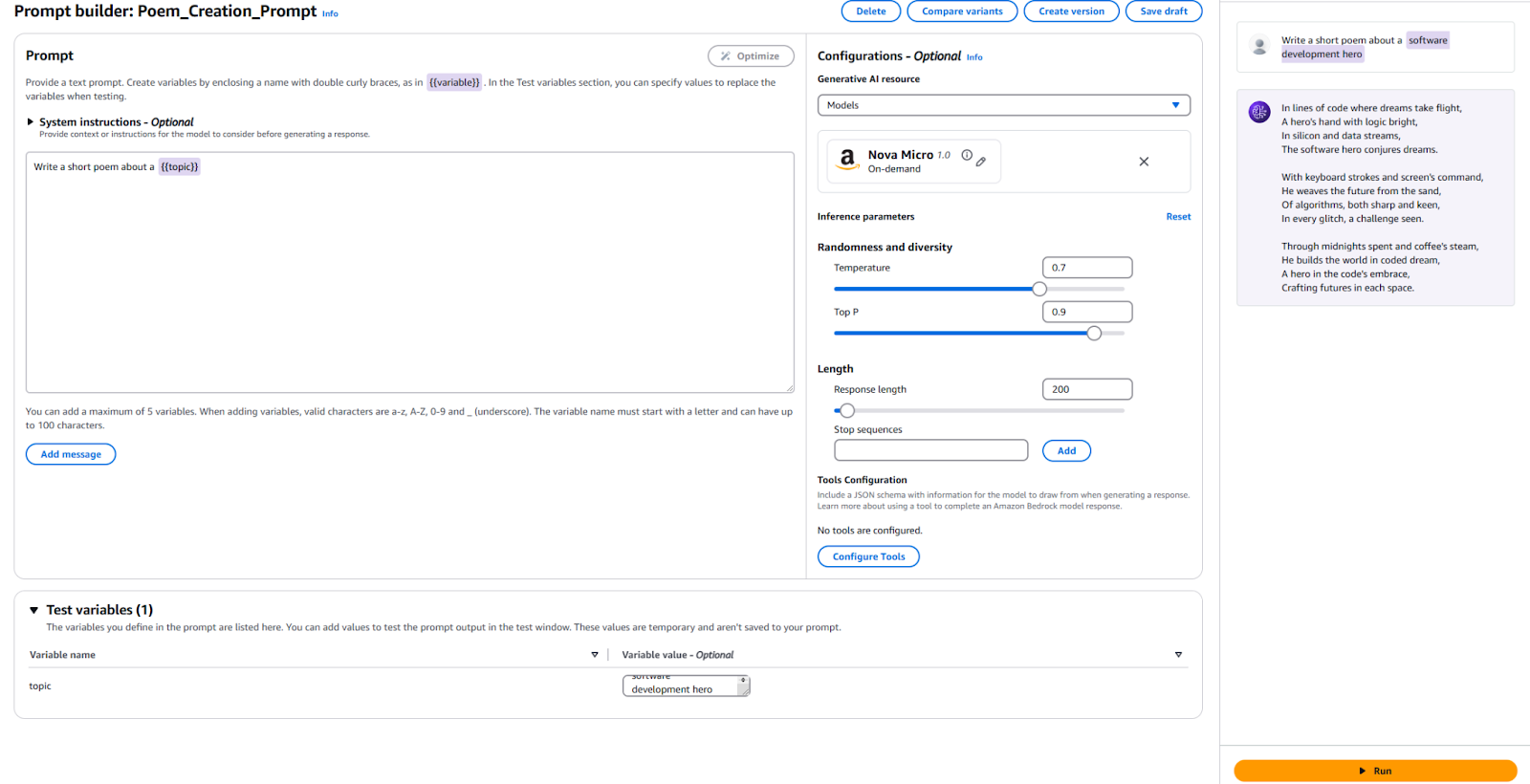
We need to publish a new Prompt Version to use this Prompt in your application. To do so, click the “Create Version” button at the top. This creates a snapshot of your current configuration. If you want to play around with it, you can continue editing and creating more versions.
Once published, we need to find the ARN (Amazon Resource Name) of the Prompt Version by navigating to the page for your Prompt and clicking on the newly created version.

Copy the ARN of this specific prompt version to use in your code.

Once we have the ARN, we can update our code to invoke this predefined prompt. We only need the prompt version's ARN and the values for any variables we inject into it.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select your prompt identifier and version
promptArn = "<ARN from the specific prompt version>"
# Define any required prompt variables
body = json.dumps({
"promptVariables": {
"topic":{"text":"software development hero"}
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(modelId=promptArn, body=body)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)As you can see, this simplifies our application code by abstracting away the details of LLM inference and promoting reusability. Feel free to play around with parameters within your prompt, create different versions, and use them in your application. You could extend this into a simple command line application that takes user input and writes a short poem on that topic.
Next Steps and Best Practices
Once you're comfortable with using Bedrock to integrate an LLM into your application, explore some practical considerations and best practices to get your application ready for production usage.
Prompt Engineering
The prompt you use to invoke the model can make or break your application. Prompt engineering is the process of creating and optimizing instructions to get the desired output from an LLM. With the pre-defined prompt templates explored above, skilled prompt engineers can get started with prompt engineering without interfering with the software development process of your application. You may need to tailor your prompt to be specific to the model you would like to use. Familiarize yourself with prompt techniques specific to each model provider. Bedrock provides some guidelines for commonly large models.
Model Selection
Making the right model choice is a balance between the needs of your application and the cost incurred. More capable models tend to be more expensive. Not all use cases require the most powerful model, while the cheapest models may not always provide the performance you need. Use the Model Evaluation feature to quickly evaluate and compare the outputs of different models to determine which one best meets your needs. Bedrock offers multiple options to upload test datasets and configure how model accuracy should be evaluated for individual use cases.
Fine-Tune and Extend Your Model With RAG and Agents
If an off-the-shelf model doesn't work well enough for you, Bedrock offers options to tune your model to your specific use case. Create your training data, upload it to S3, and use the Bedrock console to initiate a fine-tuning job. You can also extend your models using techniques such as retrieval-augmented generation (RAG) to improve performance for specific use cases. Connect existing data sources which Bedrock will make available to the model to enhance its knowledge. Bedrock also offers the ability to create agents to plan and execute complex multi-step tasks using your existing company systems and data sources.
Security and Guardrails
With Guardrails, you can ensure that your generative application gracefully avoids sensitive topics (e.g., racism, sexual content, and profanity) and that the generated content is grounded to prevent hallucinations. This feature is crucial for maintaining your applications' ethical and professional standards. Leverage Bedrock's built-in security features and integrate them with your existing AWS security controls.
Cost Optimization
Before widely releasing your application or feature, consider the cost that Bedrock inference and extensions such as RAG will incur.
- If you can predict your traffic patterns, consider using Provisioned Throughput for more efficient and cost-effective model inference.
- If your application consists of multiple features, you can use different models and prompts for every feature to optimize costs on an individual basis.
- Revisit your choice of model as well as the size of the prompt you provide for each inference. Bedrock generally prices on a "per-token" basis, so longer prompts and larger outputs will incur more costs.
Conclusion
Amazon Bedrock is a powerful and flexible platform for integrating LLMs into applications. It provides access to many models, simplifies development, and delivers robust customization and security features. Thus, developers can harness the power of generative AI while focusing on creating value for their users. This article shows how to get started with an essential Bedrock integration and keep our Prompts organized.
As AI evloves, developers should stay updated with the latest features and best practices in Amazon Bedrock to build their AI applications.
Opinions expressed by DZone contributors are their own.
Comments