From Concept to Production: A Strategic Framework for AI/ML Project Success
AI fails when treated like software. AI succeeds when built with a framework designed for uncertainty, data drift, and decision risk.
Join the DZone community and get the full member experience.
Join For FreeThe AI revolution has promised to transform business operations by automating manual work intelligently; however, it has fallen short of expectations.
MIT recently published a report claiming 95% of generative AI projects fail to deliver measurable ROI. This highlights a massive gap between AI hype and real-world success. When you compare this with the Project Management Institute (PMI) findings that 73.4% of traditional projects succeed, the difference is hard to ignore. This is not just a simple efficiency issue. This is a fundamental crisis in how we build AI systems.
After 18 years of leading complex projects and digital transformations at large financial companies, I have seen this happen again and again. The problem is not a lack of skilled people, computing power, or funding. We are building AI projects with the wrong framework. 
Why Traditional SDLC Fails AI Projects
The fundamental problem is that we are building an AI project with the wrong framework. AI projects are not software projects with machine learning sprinkled on top. They are fundamentally different from traditional software development lifecycle (SDLC) projects.
Traditional projects manage certainty. We define requirements, build a system to meet those requirements, test against expected outcomes, and deploy it to production.
AI projects manage uncertainty. We expect models to behave in a certain way. We train them according to huge data sets, evaluate probabilistic outcomes, and deploy systems that evolve over time. We can never be fully confident in the completeness of the training data or in model behavior in edge cases, and we cannot guarantee that the system will not hallucinate.
This is not a subtle difference. This is a fundamental shift from deterministic to probabilistic thinking. Still, the organization continues to enforce stage-gate governance designed for SDLC projects on AI initiatives as well. This is like using a roadmap to navigate the ocean.
The high success rate of traditional projects is a result of decades of maturity in project management practices. That is why it's important to adopt an AI lifecycle and not use SDLC for an AI project. What works for SDLC will not work for an AI project, as they are inherently different.
Framework for AI Success
I have developed a framework specifically designed for the unique challenges of AI initiatives. This is not a modified SDLC. This is a fundamentally different approach to building intelligent systems.
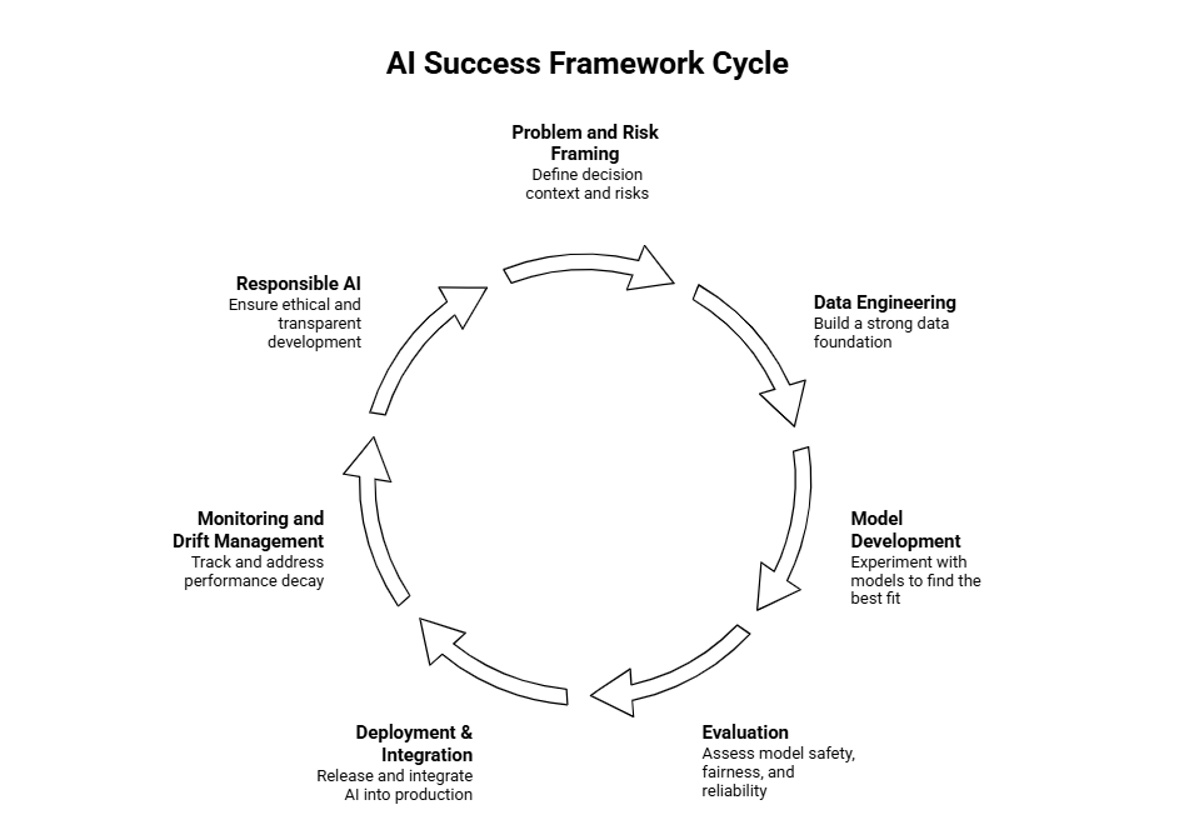
1. Problem and Risk Framing
Traditional SDLC starts with "What system should do"; however, an AI project needs to start with "What decision we are influencing and what is the cost of being wrong." We go from requirement gathering in the SDLC to risk framing, along with requirements, in AI projects. Before starting the code, we need to have the answer to the following:
- Decision context: Will AI approve mortgages based on the client's risk profile, detect financial fraud, diagnose medical conditions, recommend treatments, or approve insurance claims? Each use case has an entirely different tolerance level.
- Accountability structure: Who will be responsible within the organization when AI makes wrong decisions?
- Regulatory boundaries: Laws like GDPR, HIPAA, fair-lending rules, ITAR, and other industry regulations put strict limits on what AI can or cannot do.
- Error tolerance: What is our error tolerance? Is it 5%, 1% or 0.1%. This decision drives everything we build downstream?
Action: Create a one-page risk document clearly articulating worst-case business scenarios and their business impact. You are not ready to build if you can't explain what wrong looks like.
2. Data Engineering: Building the Foundation
Data is the most critical element of any AI project. An AI project will be as good as its source data. Now, when we start using the company's historical data, which was not captured for model training, we will find huge amounts of data, but it is not usable directly, which is why data processing becomes so important. We can generate synthetic data in a lab; however, it doesn’t capture real-world scenarios.
Actions:
- Use data versioning tools like MLFlow from day one.
- Establish bias detection protocols before model training begins.
- Create synthetic data pipelines for edge cases.
- Clearly record where each piece of data is coming from and how it was collected.
It’s always better to build model-agnostic products because models are disposable. The underlying architecture should be designed to continuously adopt newer, more powerful frontier models. Without strong data governance, model tuning will never translate into a real-world usable product.
3. Model Development
This phase is about scientific experimentation, not just for coding. We convert the initial hypothesis into experiments and explore different models to build a product. MLOps tooling is essential at this stage. This phase puts importance on versioning Hyperparameters, datasets, and code together.
The goal is not to provide a perfect model. We need to figure out which approach best handles our specific uncertainty.
Action: Build multiple candidate models using different approaches (e.g., ensemble methods, different architectures, and various feature engineering strategies).
4. Evaluation
In the SDLC, we ask: "Does it work accurately?" In AI projects, we must ask: "Is it safe, fair, and reliable?"
Common metrics go beyond accuracy.
- Bias and fairness: Ensure the model works consistently across different demographics. Use metrics like demographic parity, equal opportunity, and equalized odds.
- Explainability: We must be able to explain the rationale behind the model's decision to all stakeholders. SHAP and LIME are common tools for Explainability.
- Confidence calibration: When your model says it's 90% confident, is it actually right 90% of the time? HITL is critical for confidence and accuracy.
- Cost-weighted metrics: False negatives and false positives rarely have equal business impact. Weight your metrics accordingly.
- Adversarial robustness: What happens when users intentionally try to game your system? Use edge cases in Testing to create robustness.
Action: Establish a checklist to validate fairness, explainability, calibration, cost-weighted impact, and adversarial robustness before deployment.
5. Deployment and Integration
Production AI systems must assume they will degrade over time. AI systems don’t just get released. They are hypotheses entering the real world.
Key Considerations
- Latency vs. cost constraints: Work closely with users to determine whether latency or cost is the higher priority. In customer interaction, latency is critical. In contrast, for test and measurement, cost efficiency may matter more.
- Human in the loop: AI should augment human decision-making and not replace it. High-stakes scenarios like mortgage approval and medical diagnosis must be reviewed by a human.
- Assume degradation: The model will degrade over time. It's important to build roll back procedure during deployment and not after it.
Action: Create a deployment checklist with a rollback strategy, monitoring alert, and success metrics measured every 30 days and not just on launch day.
6. Monitoring and Drift Management
This phase has no SDLC equivalent. We must monitor concept drift, data drift, performance decay, and bias pattern over time. Once triggered, we need to focus on human overview, re-training, model rollback, or full system design
A real-world example is building a fraud detection system with weekly drift monitoring and bi-weekly re-training windows.
Action: Measure the time from drift detection to model update in production.
7. Responsible AI
An AI system can deny someone a loan, recommend the wrong medical treatment, or, worst of all, trick users into believing something purely fictional. This makes responsible AI an essential part of developing AI solutions.
Responsible AI ensures the system is developed ethically, transparently, and in accordance with laws like GDPR and HIPAA.
Key principles:
- Embed responsible AI into every lifecycle stage
- Ensure diverse perspectives define success metrics
- Build explainability from the start
- Mitigate data bias with synthetic data where needed
Action: Measure performance across demographic groups, use cases, and edge cases. Conduct a red teaming exercise by actively trying to break or misuse the system.
AI lifecycle management is not an extension of SDLC. It's an entirely new operating model for building intelligent systems. AI products are now moving away from prototypes to full-scale commercial products. Success will depend not only on better architectures but also on how well organizations adopt the AI lifecycle itself.
Opinions expressed by DZone contributors are their own.
Comments