Code Reviews: Building an AI-Powered GitHub Integration
An AI-powered code review assistant that integrates GitHub, a Flask app, and the qwen2.5-coder model on Ollama to automate code reviews.
Join the DZone community and get the full member experience.
Join For FreeOne common issue with growing teams with an extensive codebase is maintaining the code quality. It requires tremendous effort to maintain the code base, and manual code reviews often create a bottleneck during the development process.
One standard practice is to get the pull request (PR) reviewed by a senior engineer before merging it into the code base. But developers often get overloaded with reviews as they continue to deliver their regular tasks and might overlook some of the minute details that end up in production. I personally had an experience where a simple missing null check created a cascading error during migration, ultimately leading to corrupted data in production. Human beings tend to make such mistakes, and it is a very common issue.
In this article, I would like to share how I implemented an AI-powered code review assistant, which pulls the data from GitHub, uses the locally hosted qwen2.5-coder model on Ollama to review the code, and publishes the comments back to GitHub.
You might wonder, “Don’t we have GitHub Copilot?” Yes, we do, but it might not work efficiently with proprietary code, such as code specific to ServiceNow, Salesforce, etc. To address this issue, this project included a manual review system to correct the feedback from the model, which is then used to fine-tune the model.
Problem: Code Review Bottlenecks
Being part of a development team, you will face these issues:
- Delay in reviews: As senior developers manage code reviews along with their tasks, there is a significant delay in reviews.
- Inconsistent standards: Different reviewers focus on different aspects, leading to unpredictable feedback.
- Context switching: Developers lose productivity when switching between coding and reviewing.
- Learning curve: Junior developers need detailed guidance but don’t always get comprehensive feedback.
All these issues encouraged me to build a solution to provide a consistent one-pass review, while giving human beings the ability to make a final decision.
Solution: GitHub + Ollama Integration
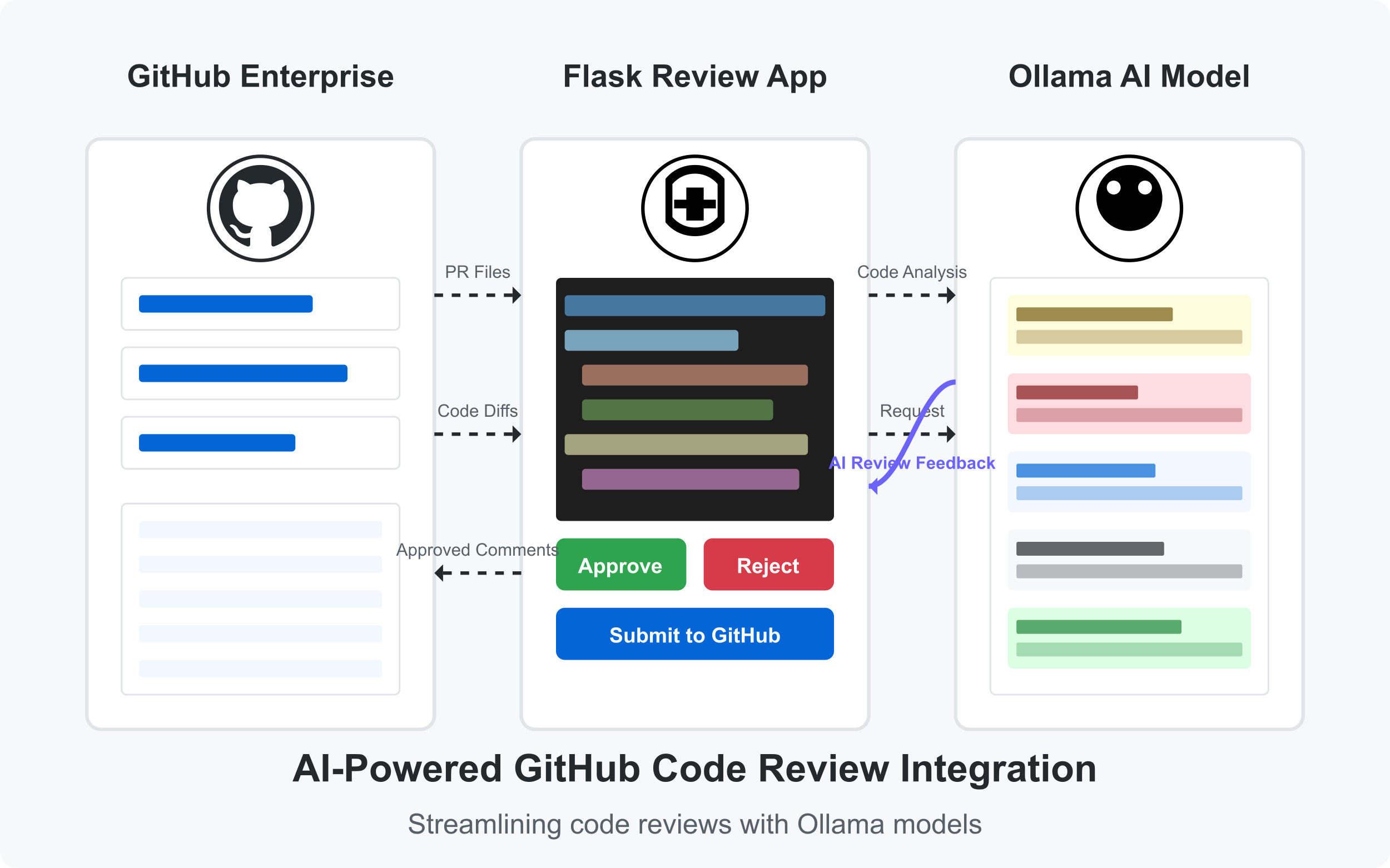
To start with an MVP, I have built a web application based on Flask that acts as a bridge between GitHub and locally hosted LLM models.
Let’s dive into how it works and how you can implement it in your environment.
+-------------------+ +-------------------+ +--------------------+
| | | | | |
| GitHub +----->+ Flask App +----->+ Ollama API |
| Enterprise | | (Reviews Server)| |(Local qwen2.5 Model)|
| | | | | |
+-------------------+ +------+-----+------+ +--------------------+
| ^
| |
+-------v-----+-------+ +--------------------+
| | | |
| Comments Database +---->+ Monaco Editor UI |
| (JSON/SQL) | | Web Interface |
| | | |
+---------------------+ +--------------------+
Here are some core components in the application:
- GitHub integration: Fetches PR files and their diffs through GitHub’s API.
- Flask application: Processes code for AI consumption and manages the review workflow.
- Ollama integration: Sends code to locally-hosted model (qwen2.5-coder) and processes the LLM’s feedback.
- Monaco editor UI: Provides a rich interface for reviewing code and suggestions.
- Comments database: Stores and tracks review comments (used a simple JSON in this project).
Implementation Details
Setting Up Ollama Locally
To set up Ollama locally, visit ollama.com, download Ollama based on your operating system, and follow the onscreen instructions to install it. Once you are done with the installation, you can choose the model based on your use case from the list of models available on Ollama.
In this case, I have selected qwen2.5-coder. Use the command below to interact with the model in the command line.
ollama run qwen2.5-coderSetting Up Flask
If you already do not have Flask installed, install it using pip install Flask. Once you’ve successfully set up Flask, you can begin building the application by adding routes, templates, and integrating with external services or databases.
Let’s look into the app.py, which is the core of the Flask app, where we define all the api routes, business logic, etc. So, to call the model, Ollama provides an API endpoint ‘http://localhost:11434/api/generate’. Refer to the code below to understand how we pass the information to Ollama.
def call_ollama_model(code):
try:
response = requests.post(OLLAMA_API_URL, json={
'model': 'qwen2.5-coder',
'prompt': f"""
Please review the following JavaScript code for potential issues,
improvements, and suggestions. For each issue, include:
1. The line number
2. The issue type (bug, performance, readability, security)
3. A brief explanation of the problem
4. A suggested fix
Here's the code you need to review:
{code}
Format your response as JSON with the following structure:
{{
"comments": [
{{
"line": 42,
"type": "security",
"message": "Unvalidated user input used in SQL query",
"suggestion": "Use parameterized queries with prepared statements"
}}
]
}}
""",
'stream': False
})
if response.status_code == 200:
result = response.json()
return process_ollama_response(result['response'])
else:
return f"Error calling Ollama model: {response.status_code}"
except Exception as e:
return f"Error calling Ollama model: {str(e)}"
Function to Fetch GitHub PR Details
def get_pr_files(repo_owner, repo_name, pull_number):
headers = {"Authorization": f"token {GITHUB_TOKEN}"}
url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/pulls/{pull_number}/files"
response = requests.get(url, headers=headers)
if response.status_code == 200:
files = response.json()
return files
else:
return None
Comment Management System
The application stores comments locally and tracks which ones have been synced to GitHub:
def save_comments_to_file(comment):
# Load existing comments
if os.path.exists(COMMENTS_FILE):
with open(COMMENTS_FILE, 'r') as file:
try:
all_comments = json.load(file)
except json.JSONDecodeError:
all_comments = {}
else:
all_comments = {}
# Add or update comment
pr_key = f"{comment['repo_owner']}/{comment['repo_name']}/pull/{comment['pull_number']}"
if pr_key not in all_comments:
all_comments[pr_key] = []
# Generate a unique ID for the comment
comment_id = str(uuid.uuid4())
comment['id'] = comment_id
comment['synced_to_github'] = False
comment['created_at'] = datetime.now().isoformat()
all_comments[pr_key].append(comment)
# Save back to file
with open(COMMENTS_FILE, 'w') as file:
json.dump(all_comments, file, indent=4)
return comment_idSubmitting Comments to GitHub
def submit_comment_to_github(comment_id):
# Load all comments
with open(COMMENTS_FILE, 'r') as file:
all_comments = json.load(file)
# Find the comment by ID
for pr_key, comments in all_comments.items():
for comment in comments:
if comment['id'] == comment_id and not comment['synced_to_github']:
# Extract PR details
repo_parts = pr_key.split('/')
repo_owner = repo_parts[0]
repo_name = repo_parts[1]
pull_number = repo_parts[3]
# Create GitHub comment
headers = {"Authorization": f"token {GITHUB_TOKEN}"}
url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/pulls/{pull_number}/comments"
payload = {
"body": comment['body'],
"commit_id": comment['commit_id'],
"path": comment['path'],
"line": comment['line']
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 201:
# Mark as synced
comment['synced_to_github'] = True
with open(COMMENTS_FILE, 'w') as write_file:
json.dump(all_comments, write_file, indent=4)
return True
return False
return FalseUser Interface Implementation
The application features a clean interface built around the Monaco editor, making it easy to review code and manage feedback:
<!DOCTYPE html>
<html>
<head>
<title>AI Code Review Assistant</title>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/monaco-editor/0.34.0/min/vs/editor/editor.main.css">
<script src="https://cdnjs.cloudflare.com/ajax/libs/monaco-editor/0.34.0/min/vs/loader.js"></script>
</head>
<body>
<div class="container">
<div class="header">
<h1>AI Code Review Assistant</h1>
<form id="prForm">
<input type="text" id="repoOwner" placeholder="Repository Owner">
<input type="text" id="repoName" placeholder="Repository Name">
<input type="number" id="pullNumber" placeholder="PR Number">
<button type="submit">Analyze PR</button>
</form>
</div>
<div class="main">
<div id="editor-container"></div>
<div id="comments-container">
<h3>AI Suggestions</h3>
<div id="ai-comments"></div>
<h3>Add Comment</h3>
<form id="commentForm">
<input type="number" id="lineNumber" placeholder="Line Number">
<select id="commentType">
<option value="improvement">Improvement</option>
<option value="bug">Bug</option>
<option value="security">Security</option>
<option value="performance">Performance</option>
</select>
<textarea id="commentText" placeholder="Comment text"></textarea>
<button type="submit">Add Comment</button>
</form>
<button id="submitToGitHub">Submit All Comments to GitHub</button>
<button id="exportComments">Export Comments for Training</button>
</div>
</div>
</div>
<script>
// Monaco editor initialization code
require.config({ paths: { 'vs': 'https://cdnjs.cloudflare.com/ajax/libs/monaco-editor/0.34.0/min/vs' }});
require(['vs/editor/editor.main'], function() {
window.editor = monaco.editor.create(document.getElementById('editor-container'), {
value: '// Code will appear here',
language: 'javascript',
theme: 'vs-dark',
readOnly: true,
lineNumbers: 'on',
glyphMargin: true
});
});
// Rest of the UI JavaScript
</script>
</body>
</html>
Fine-Tuning the AI Model
As discussed in the introduction, to improve the LLM's performance for our specific codebase, we can fine-tune the model using data collected through the review process.
Exporting Training Data
The application includes an endpoint to export comments in a format suitable for fine-tuning:
@app.route('/export_comments', methods=['GET'])
def export_comments():
"""Export all comments in a format suitable for model fine-tuning."""
if os.path.exists(COMMENTS_FILE):
with open(COMMENTS_FILE, 'r') as file:
try:
all_comments = json.load(file)
# Format for fine-tuning
training_data = []
for pr_key, comments in all_comments.items():
for comment in comments:
if comment.get('human_approved', False):
training_example = {
"input": comment.get('code_context', ''),
"output": comment.get('body', '')
}
training_data.append(training_example)
return jsonify({
"status": "success",
"training_examples": len(training_data),
"data": training_data
})
except json.JSONDecodeError:
return jsonify({"status": "error", "message": "Invalid comments file"})
else:
return jsonify({"status": "error", "message": "No comments file found"})
Fine-Tuning Using Unsloth
Unsloth is an excellent tool for efficiently fine-tuning models. Here's how to use it with your exported data.
NOTE: In this application I built, I did not have enough data to fine-tune the model, but if you want to try this, please refer to the below. It uses unsloth/llama-3-8b to fine-tune based on the custom data.
Install Unsloth:
pip install unslothThen, create a fine-tuning script (taken from the official tutorial):
from unsloth import FastLanguageModel
import torch
import pandas as pd
import json
# Load the dataset from the exported JSON
with open("exported_comments.json", "r") as f:
data = json.load(f)
training_data = data["data"]
# Convert to DataFrame
df = pd.DataFrame(training_data)
# Initialize the model
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/llama-3-8b",
max_seq_length=2048,
dtype=torch.bfloat16,
load_in_4bit=True,
)
# Set up a supervised fine-tuning trainer
trainer = FastLanguageModel.get_peft_trainer(
model=model,
tokenizer=tokenizer,
train_dataset=df,
formatting_func=lambda example: f"Review this code: {example['input']}\n\nReview: {example['output']}",
peft_config=FastLanguageModel.get_peft_config(r=16, lora_alpha=32, target_modules=["q_proj", "k_proj", "v_proj", "o_proj"]),
max_seq_length=2048,
dataset_text_field="formatting_func",
batch_size=1,
epochs=3,
learning_rate=2e-4,
gradient_accumulation_steps=4,
warmup_ratio=0.05,
logging_steps=1,
)
# Train the model
trainer.train()
# Save the fine-tuned model
model_path = "code-review-model"
trainer.save_model(model_path)
# Export for Ollama
FastLanguageModel.export_to_gguf(
model_path=model_path,
output_path="code-review-model.gguf",
quantization_method="q4_k_m"
)Adding Your Fine-Tuned Model to Ollama
After fine-tuning, create a Modelfile to import your model into Ollama:
# code-review-modelfile
FROM ./code-review-model.gguf
PARAMETER temperature 0.1
PARAMETER top_p 0.7
PARAMETER stop "</review>"
SYSTEM """
You are an expert code reviewer specializing in identifying bugs, security issues, performance problems, and code quality improvements. When reviewing code:
1. Focus on substantive issues that impact functionality, security, and performance
2. Provide specific, actionable feedback with line numbers
3. Suggest concrete solutions for each issue identified
4. Format your response consistently for each issue
5. Be concise but thorough
"""
Finally, create the model in Ollama:
ollama create code-reviewer -f code-review-modelfileNow you can update your application to use your custom fine-tuned model.
Conclusion
AI-powered assistants can help streamline development by automating first-pass reviews while maintaining human oversight for accuracy. Let me know your comments on my project and any suggestions for improving it.
Opinions expressed by DZone contributors are their own.
Comments