AI/ML Project Work By Using Scrum
How to apply scrum methodology to work with AI/ML product development. We go over the challenges and tips for application.
Join the DZone community and get the full member experience.
Join For FreeWorking with AI/ML Projects? Which Agile Methodology to use to ensure success (Scrum/Kanban/Scrumban/Lean Start-up)?
This story was shared by one of my close friends.
Challenges with AI/ML Projects:
- The output depends on the input. Getting volumes of data is a challenge. Data is again expensive.
- ML are complex technologies that take time to implement and fully leverage.
- Cost also requires to examine for chasing 100% accuracy.
- The change request is expansive after a particular stage of the Model development.
- AI/ML expertise is in scarcity in the industry. Technology is new.
Kanban was not considered, because, in Kanban, there are no definite iterations or sprints, just a continuous flow where work items are pulled from one stage to the later. Kanban board is never reset. Many of the Scrum events were not employed. Kanban teams usually have daily stand-up meetings but they are not prescribed. There are no routinely planned sprint planning meetings, sprint demos, or sprint retrospectives, so the process is more lightweight. Some of the exercises in those rituals may or may not be performed at an informal level.
Scrum is a more discipline, prescribed approach to deal with complexity and uncertainty.
The team initially explored the Lean Start-up approach. Later moved into Scrum. Build-Measure-Learn in a Sprint! The team wants more discipline.
What we have analyzed that there are 3 stages in AI/ML projects.
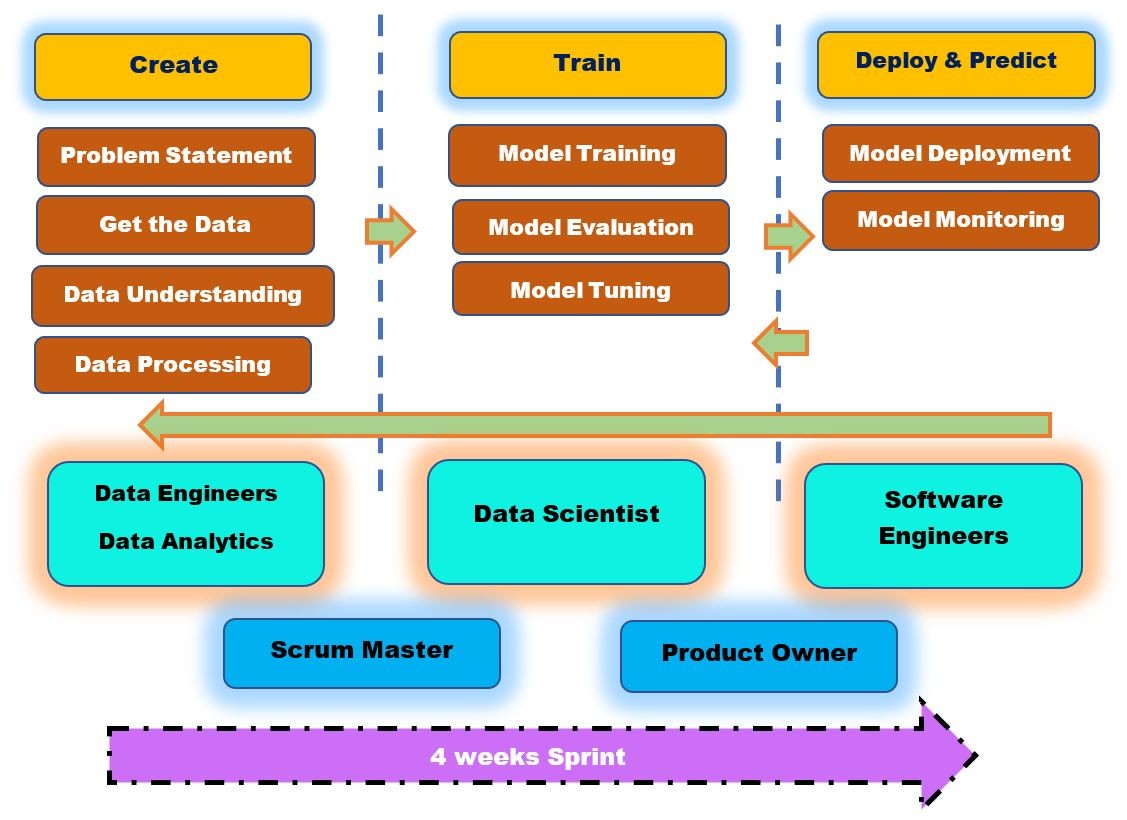
Create, Train, Deploy & Predict.
These are the main three focus area AI/ML team members should concentrate on. All the activities in the scrum team need to spread in all these Sections. Product backlog items need to touch upon all these areas. User stories are related to all these sections. e.g. Benchmark algorithm, Improve Algorithm Accuracy, etc.
e.g. User Story: User Stories are work items required to accomplish a Feature end-to-end. Examples of User Stories include:
- Obtain data Explore data Catalyze new features Create models Deploy models Retrain models
- Each section will have many activities to succeed.
- Ensure team members add >Spike as separate work items in the product backlog
- Discuss Spike and other stories in daily stand-up.
- Be specific on the task’s description related to ML work (No Vague statement).
Let us look into each section.
- For Create Phase: Below activities are part of the creation phase.
- Problem Statement: Need to discuss with your customer and diverse stakeholders to recognize and classify business problems. Formulate questions that illustrate the business goals that the data science techniques can Focus on.
- Get the data: The quantity & quality of the data dictates how valid our model could be. The outcome of this exercise is typically a representation of data which the team will use for training
- Data Understanding: Generate a fair understanding of the data.
- Data Processing: Wrangle data and strengthen it for training. Clean that which may essential (eliminate duplications, correct inaccuracies, deal with missing values, normalization, data type conversions, etc). Randomize data, which eliminates the effects of the specific order in which we gathered and/or otherwise prepared the data. Visualize data to help detect relevant relationships between variables or class differences, or perform other exploratory analysis.
For Train Phase:
Model Training, Model Evaluation, and Model Tuning:
- The data set pertains to an algorithm, and the algorithm leverages sophisticated mathematical modeling to interpret and develop predictions.
Model Evaluation
- Check whether the model behaves satisfactorily for production. Evaluate the training and test data set. Use an array of competing for machine-learning algorithms along with the numerous associated tuning parameters that are accommodated toward resolving the question of significance with the prevailing data.
For Deploy and Think Phase:
The focus is to substantiate the trained model. Employing the test data, analyze the model’s accuracy. If the results are not good enough, we desire to modify and retrain the ML model. After the collection of models function satisfactorily, we can operationalize them for other applications to absorb. Depending on the business requirements, predictions are constructed either in real-time or on a cluster basis.
Evaluate the model’s results with the business stakeholders. Are there other data elements worth including to the model to form it higher accuracy?
Review the algorithm choice. Within each class of algorithm, there are dozens of algorithm choices. A different algorithm may function better for the model.
Adapt the parameters of the appointed algorithm to revise performance. Sometimes slight modifications have a sizable impact.
Scrum Team Members:
The scrum team consists of a cross-functional, self-organized team with a common purpose. Collaborating with these diversified skilled team members is not an easy task. ML projects Scrum master has to be Master collaborator!
- Scrum Master to ensure all these phases has the right product backlog items. All the scrum events and sprint goals are defined. Scrum Master with the help of the Product Owner ensures the sprint goal is achieved and incrementally model build and deployment can happen.
Organizations hire numerous individuals with their various skills in a project to fulfill the requirements in each phase. This would be a combination of Big Data Engineer — who engineers the full data pipeline to gathers the expected data from several heterogeneous sources under one basket in the needed form.
- Data analyst, who does proper data collection and interpretation activities. An analyst ensures that the collected data is relevant and exhaustive while also interpreting the analytics results.
- Data Scientist, who studies the data and develops machine learning models for the use-case and data mining techniques.
- Data engineers implement, test, and maintain infrastructural components that data architects design.
- Software Engineers would pick up the model built up by the scientist into a production environment.
In 4 weeks’, the timeframe the team is trying to deploy a model, sometimes it is successful and most of the time work moves to the next sprint. The below statistics also depict the same that it is not easy to deploy the model by 4 weeks’ timeline. The team is flexible and considering this as the next sprint achievements.
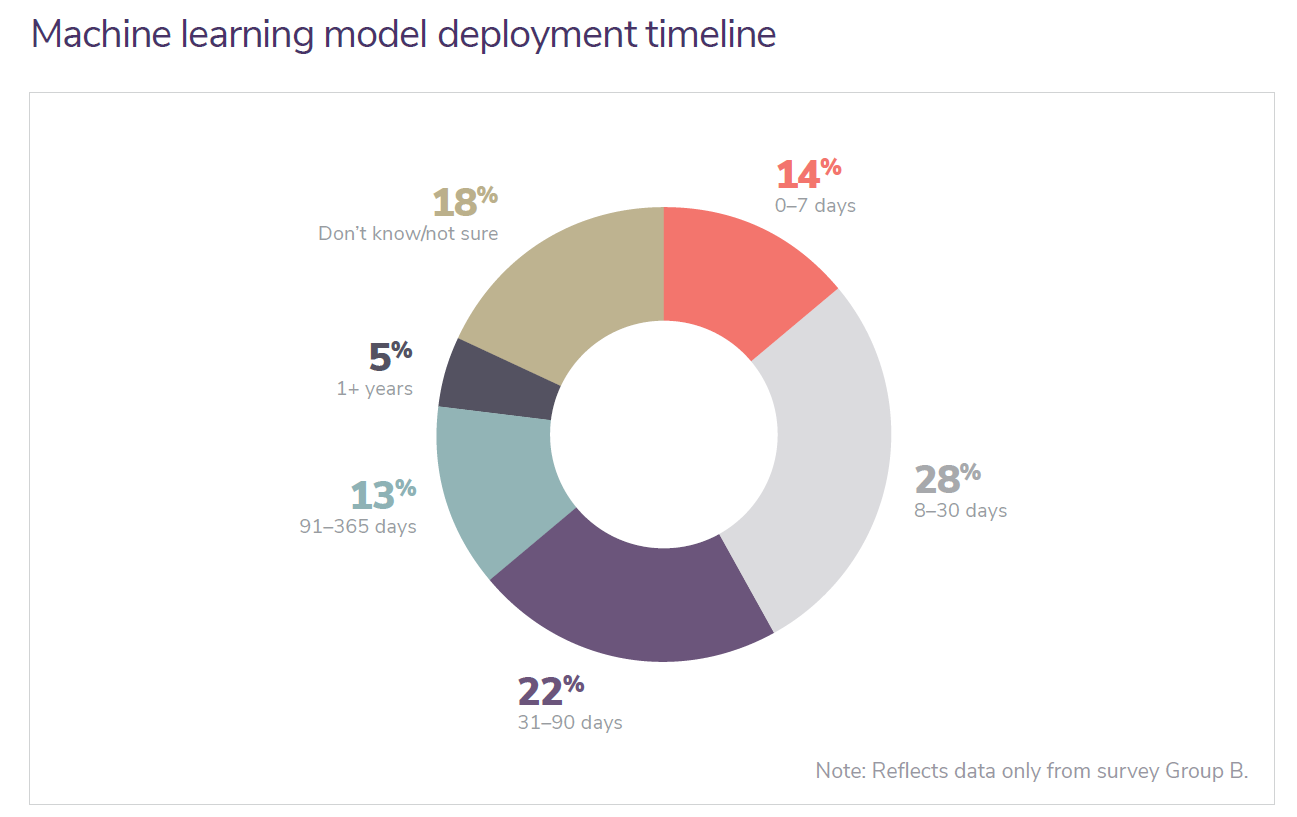
Source: Algorithmia’s “2020 State of Enterprise ML”. This question about how long it takes to deploy an ML model into production was only asked to a subset of respondents at a company that has an ML model production.
Scrum Master, PO, and Team to measure success with
- Development and deployment of a predictive model
- Monitor if the accuracy of forecasting results corresponds to performance requirements and improve a model if needed.
- Track the performance of the deployed model
- Measure the Business Impact
As we are aware ML model takes a lot of work, so though Scrum says potentially shippable work after 4 weeks, but it is OK to deploy a successful model maybe a second or third sprint. Customer and Stakeholder collaboration is central to this ML execution journey.
We are also in the discovery path and in every retro, we are becoming better to execute ML projects in better ways.
Opinions expressed by DZone contributors are their own.
Comments