Alipay: Large-Scale Model Training on Billions of Files
Chuanying Chen provides a deep dive into the practices of reliable, scalable, and high-performance large-scale training on billions of files.
Join the DZone community and get the full member experience.
Join For FreeAnt Group, formerly known as Ant Financial, is an affiliate company of the Chinese conglomerate Alibaba Group. The group owns the world’s largest mobile payment platform Alipay, which serves over 1.3 billion users and 80 million merchants.
Our team works on the AI platform. With the exponential growth of data, we create and optimize infrastructure that enables large-scale model training and overcomes the performance bottleneck while reducing the cost of data storage and computation.
1.1 Challenges in Large-Scale Training
- Storage I/O Performance: With the increasing compute power of GPU for model training, the underlying storage infrastructure is under considerable pressure to keep up. Our training jobs need to process a large number of small files (ranging from 300 million to billions), which can exert significant pressure on file metadata, leading to performance issues. The inability to meet the current GPU training speed can severely impact the efficiency of model training.
- Single-Machine Storage Capacity: The continuous growth of model sets is a concern, as a single machine may not have sufficient storage capacity. Thus, there is a need for a solution that can support large-scale model training.
- Network Latency: Although there are several storage solutions available, none of them offer a seamless integration of high-throughput, high-concurrency, and low-latency performance. Alluxio, however, provides an innovative solution to address this challenge by being more compact and by having the ability to be used with calculation operations deployed in the same room, which minimizes network latency and performance loss.
1.2 Challenges of GPU Training With Decoupled Storage and Computation
When we replace the CPU with GPU for training, the disparity between computation and storage speed becomes more pronounced. Frequently, it is not feasible to co-locate storage and computing clusters due to their physical locations, which may span across different regions or even countries, leading to substantial latency issues. Our AI platform needs to address common challenges such as improving storage throughput, reducing storage I/O latency, maximizing GPU utilization, and enhancing GPU training efficiency.
With the trend of decoupling storage and computing, we see performance improvement by utilizing advanced storage media (such as HDD, Sata-SSD, Nvme-SSD, Optane, or RAM) or by preloading data files into memory to meet the computing read requirements. However, as the training scale grows, the storage pressure increases. A single machine’s storage capacity eventually becomes a bottleneck.
On the other hand, the architecture of decoupled storage and computing allows the computing node to overcome its capacity limitations, thus allowing unlimited scalability. However, this also results in increased distances between storage and computing, leading to increased storage throughput and I/O latency due to sub-millisecond levels of network latency (compared to memory nanoseconds, tens of microseconds for SSD, and sub-milliseconds for network).
2. Optimize the Reliability of Alluxio
We use Kubernetes (K8s) to manage our resources. Frequent restarts or migrations of these resources cause cluster failovers. The performance of these failovers has a significant impact on the user experience. If the service becomes unavailable during a failover, it could result in many errors on the user side. Prolonged downtime, such as several hours, may even result in the interruption of model training. Hence, maintaining the reliability of Alluxio is very critical.
Our optimization efforts are focused on two key areas: enhancing worker registration on followers and accelerating the master migration process.
2.1. Worker Registration on Followers
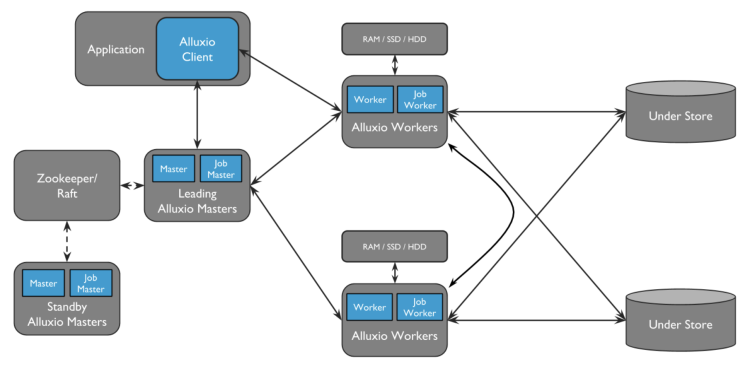
The diagram below represents the high availability settings of our Alluxio system. The master node acts as the central repository for metadata, with its internal metadata synchronization maintained through Raft. The primary master node serves as the external interface for metadata services, while the worker nodes provide data services. The worker registration with the primary master node ensures discovery, commonly referred to as worker node discovery, and is critical in maintaining reliability during system operation.
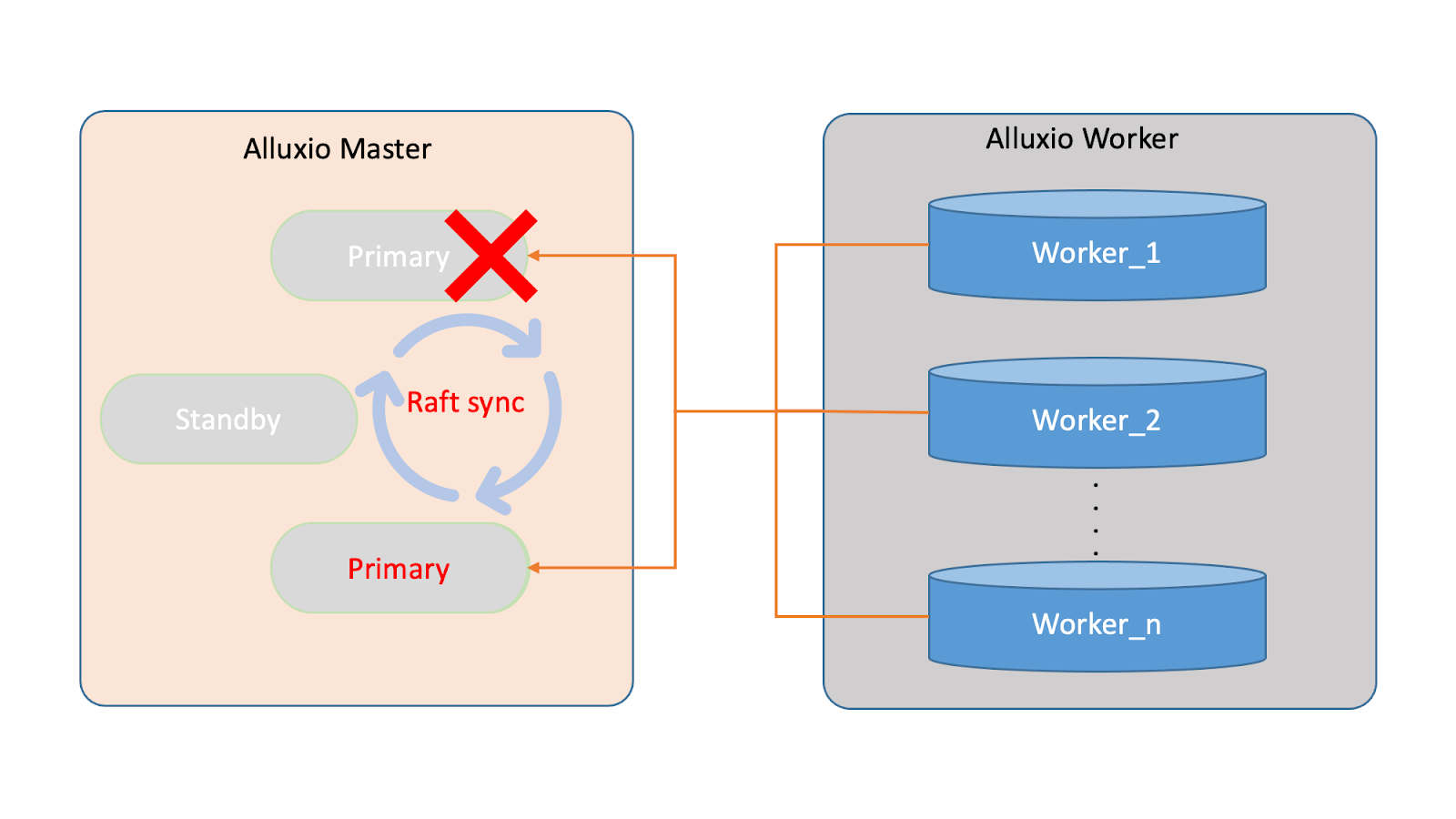
The challenges during a failover event in Alluxio arise during the worker registration process. During a failover, the worker nodes need to discover and register with the newly elected primary, leading to three key challenges:
- Cluster unavailability before the first worker registers: The cluster is unavailable before the first worker completes its registration with the new primary. This is because the first worker is responsible for restoring the new primary's leadership; without a worker, the primary can only access metadata and not data.
- Performance impact of cold data during worker registration: During the worker registration process, if a block of data is cached in the worker but not registered with the master, the master is unaware of this block and treats it as cold data. As a result, when this block is needed, it must be reloaded from UFS, which can impact the performance significantly.
- Redundant data needs to be cleaned up after worker registration: Once worker registration is complete, any redundant cache data from the previous process should be cleaned up for performance. Therefore, cleaning up redundant cache data is necessary to prevent this from negatively affecting the efficiency of cache space usage.
Our optimization involves implementing a system where all worker nodes pre-register with all master nodes. Upon initialization, the workers will re-establish their connections with the masters through a real-time heartbeat mechanism. This allows for continuous monitoring and updating of the status of the worker nodes, as depicted in the diagram below:
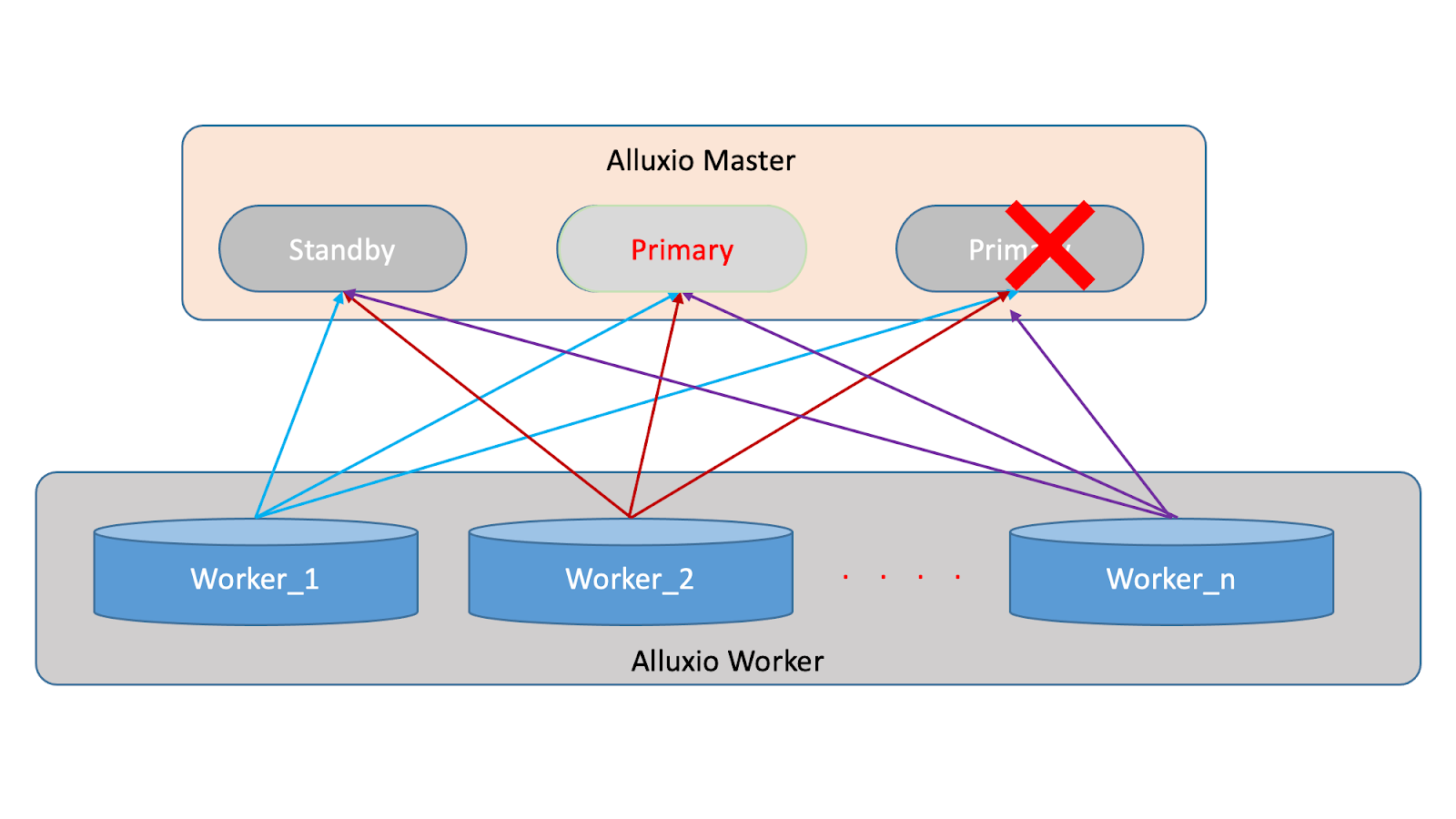
During a primary restart, a Raft election takes place to establish a new primary. This process involves self-discovery, election, and catch-up, which can be completed in under 30 seconds, significantly reducing the downtime during failover.
However, there are some potentially negative impacts. If a master node is restarted, the new primary will provide normal service to the outside. However, if a standby master node is restarted, the worker nodes need to re-register their metadata information, which can result in high network traffic and potentially affect the performance of the registered masters. However, this impact is negligible if the cluster load is low. Despite this, this optimization has been implemented to improve failover efficiency.
2.2. Speeding up the Process of Master Migration
Initially, three masters provided external services and maintained reliability by having workers register with the primary. However, during machine rearrangements, such as replacing standbys and the primary, the new master cluster node was established, consisting of standby3, standby4, and the newly elected primary.
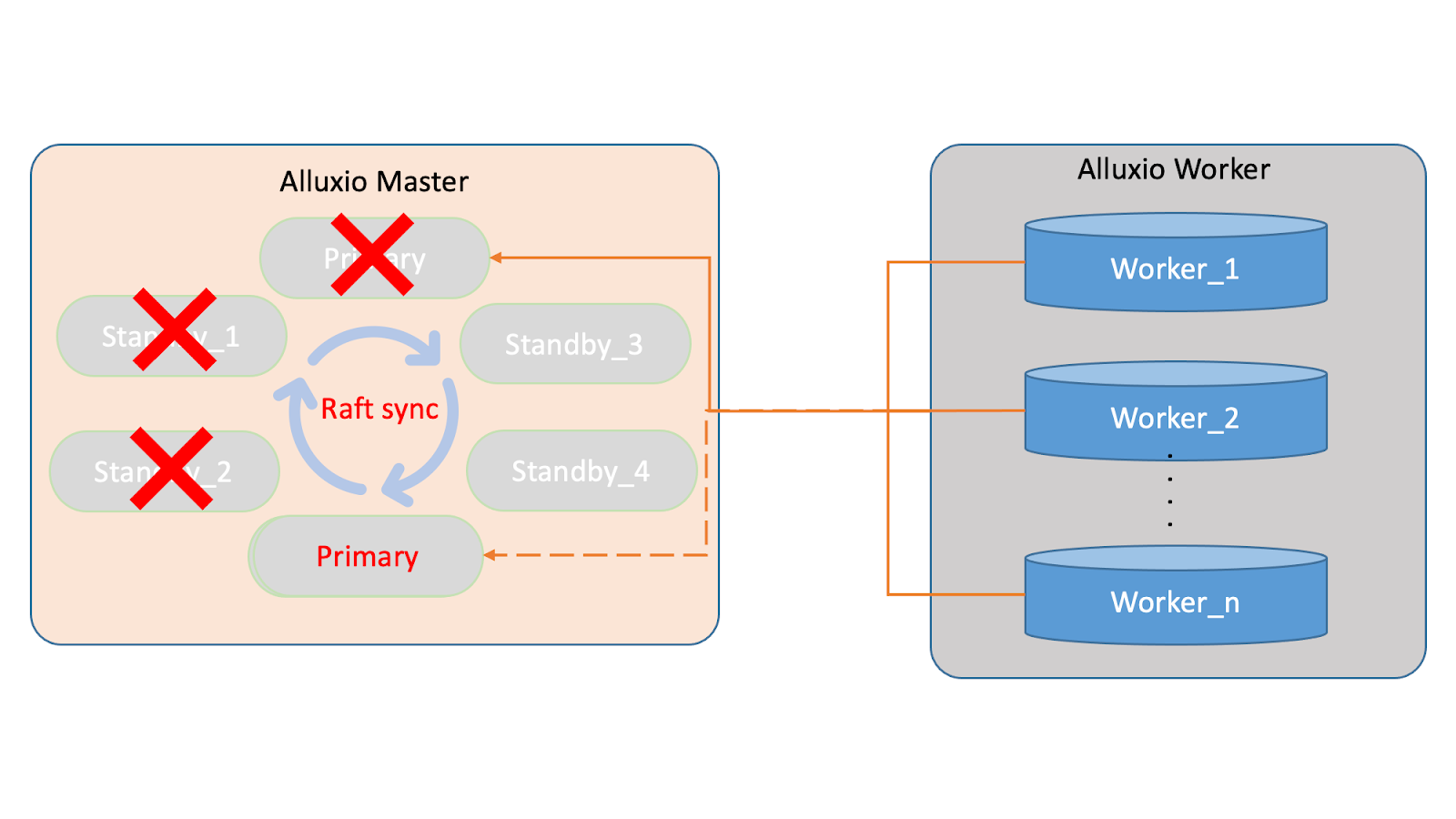
To address the master migration problem, we have implemented a solution to maintain a constant heartbeat between the primary and worker nodes. This real-time communication allows the worker nodes to stay updated on any changes to the master nodes.
For instance, if there is a change in the master nodes, such as standby3 replacing standby1, the primary will inform the worker nodes of the updated cluster composition through the heartbeat. This process is repeated for each subsequent change in the master nodes.
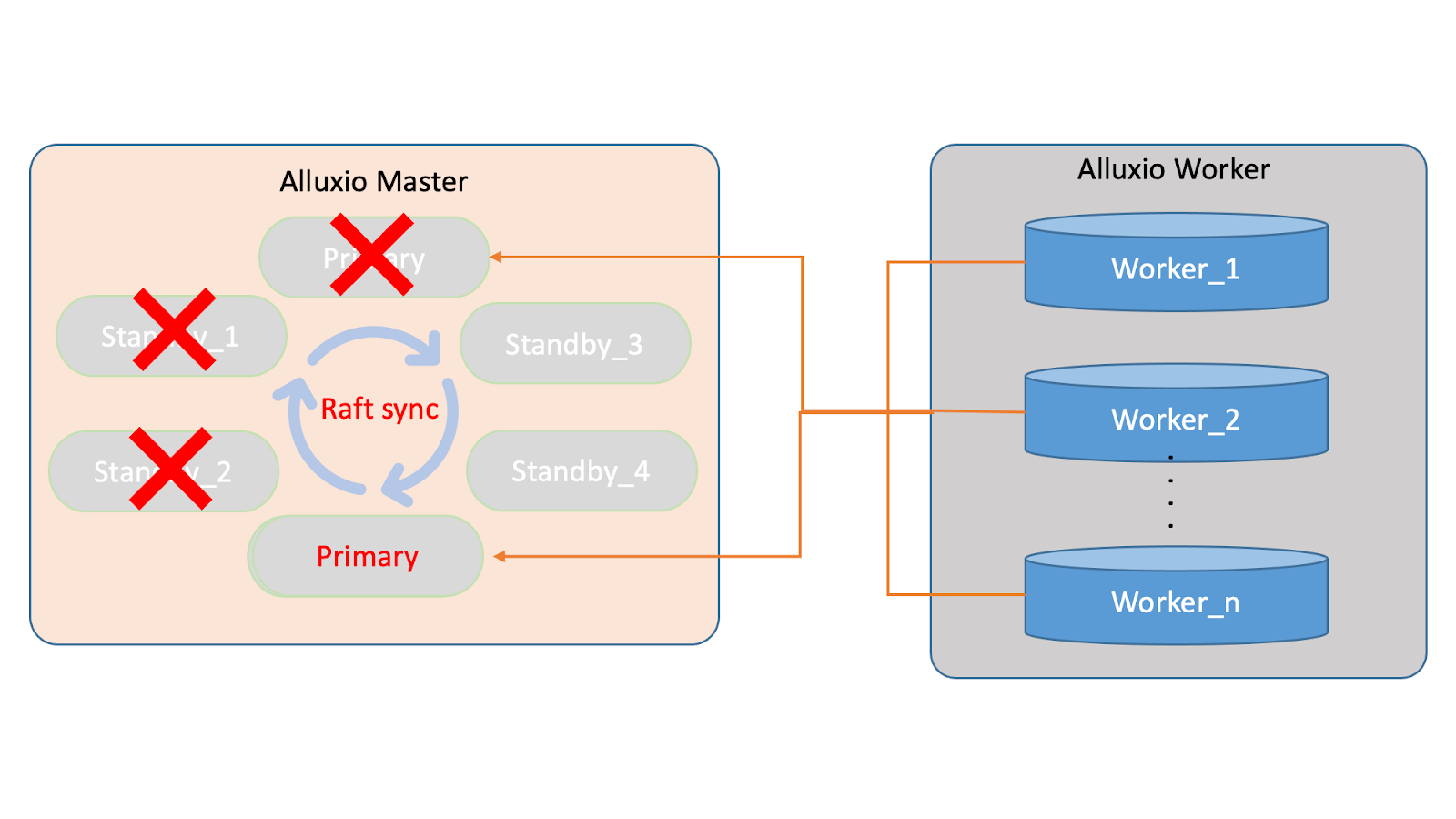
By implementing this solution, we can update the worker nodes in real-time to ensure the cluster’s reliability. This approach eliminates the need for manual intervention for master node changes, reducing operational costs significantly.
Note that in the initial setup, the master information recognized by the worker was statically injected through configuration during initialization. This static management of the master information led to the crash of the entire cluster when there were changes in the master nodes, as the worker could not recognize the new nodes. Our solution eliminates this issue and ensures the cluster is reliable.
3. Improve the Performance of Training Using Alluxio
The illustration below presents the overarching structure of the present Alluxio system. The client begins by retrieving metadata from the leader and accessing normal workers according to the metadata information. The leader and the standby maintain metadata consistency through the Raft consensus algorithm, with the leader responsible for initiating metadata synchronization to the standby.
The current Alluxio architecture has two main components: the client and the leader/standby synchronization. The client retrieves metadata from the leader and accesses the workers for data retrieval. The leader and the standby masters maintain consistency of metadata information through Raft synchronization, where the leader can initiate metadata updates to the standby. However, the standby cannot initiate updates to the leader, violating the data consistency principle.
Regarding worker registration, the standby now has connections with workers and collects all data, giving it similar attributes to the leader regarding data integrity. However, using the standby as a backup is not practical as it may break the Raft data consistency rule. In an effort to make full use of the standby’s resources, we have explored the possibility of providing read-only services. Read-only operations do not require Raft updates and do not impact data consistency, making it a good fit for standby.
This optimization plan is particularly relevant for scenarios such as model training or file cache acceleration, where write operations are performed only once during preheating and subsequent operations are read-only. In large-scale read-only scenarios, utilizing the standby can significantly improve the entire cluster's performance.
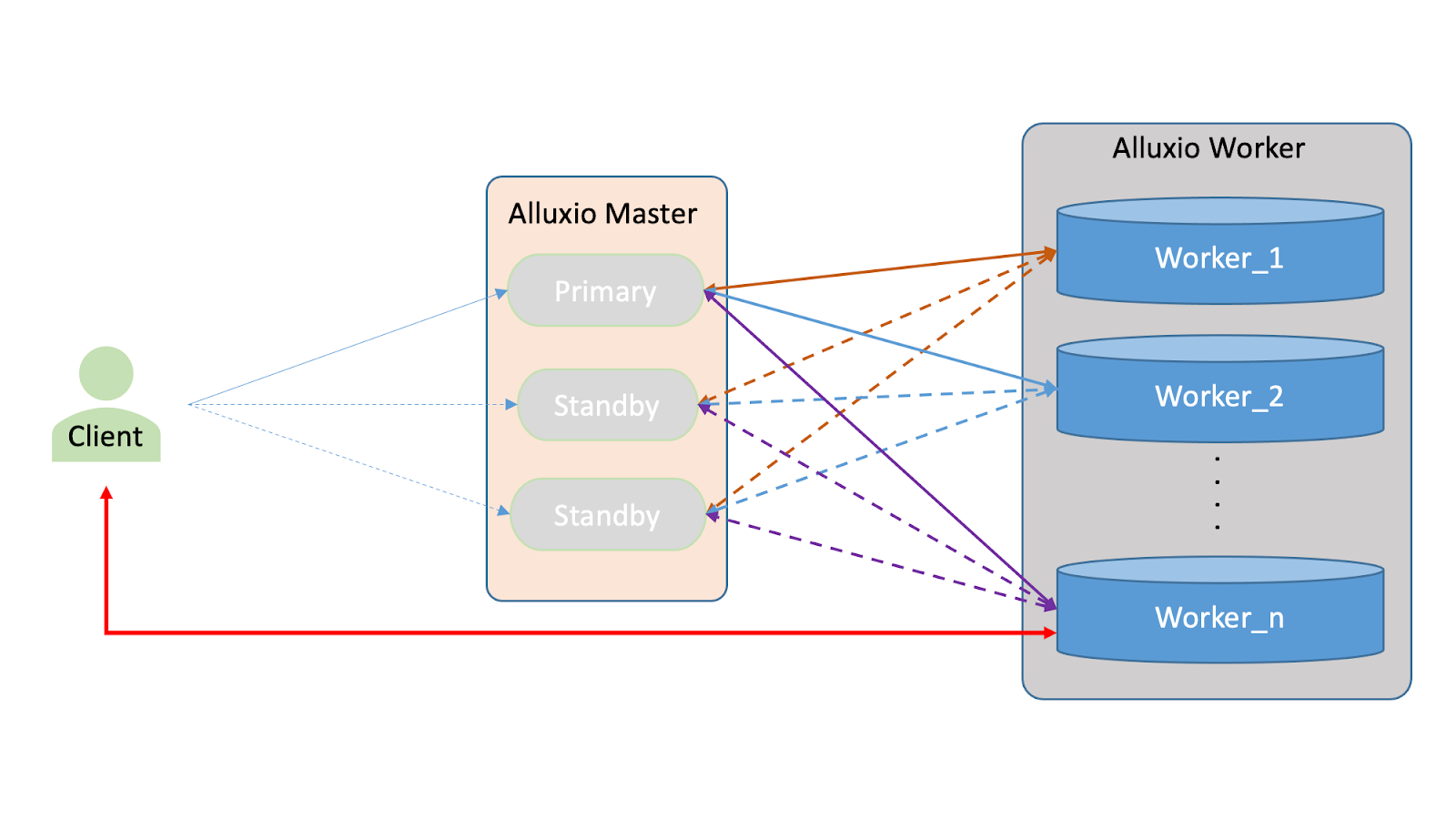
The previous implementation involved all workers registering with all standbys, resulting in the data of the standby being essentially equivalent to that of the primary. Meanwhile, the primary and workers maintained main heartbeats. When a client initiates a read-only request, it is randomly assigned to the current master for processing, which is then returned to the client. Writes, however, are still sent to the primary.
By integrating Alluxio, we can improve the performance of read-only requests without compromising Raft consistency. Theoretically, expanding the machines can boost read-only performance by a factor of three or more. We have tested this optimization via reading from followers, displaying notable performance enhancements. This is the outcome of incorporating Alluxio into the system.
4. Increase the Scalability of Alluxio (Scale-Out Alluxio Clusters)
We have notably improved the scalability of the system by sharding the metadata. Each shard constitutes an Alluxio cluster, and multiple Alluxio clusters form a federation that collaboratively serves the metadata, enabling support for over a billion files. To ensure that the correct Alluxio cluster services the request, we introduced a proxy that routes the request based on the hash of the path.
The Alluxio system contains several components in its master, including block master, file master, Raft, and snapshot. These elements have an impact on the system’s performance in the following ways:
- Block Master: The block master is responsible for managing the allocation of blocks on worker nodes. In large-scale cluster setups, the block master can become a performance bottleneck due to its memory consumption. As the block master stores information about the blocks present on the worker nodes, it can consume a significant amount of memory on the master nodes.
- File Master: The file master is responsible for storing metadata information about the files stored in the Alluxio system. This component can strain local storage in large-scale setups as the metadata information grows.
- Raft: Raft is the consensus protocol Alluxio uses to maintain data consistency across the cluster. However, efficiency issues can arise in syncing data within the Raft protocol, which can impact overall performance.
- Snapshot: The snapshot component is responsible for periodically taking a snapshot of the metadata stored in the file master. The efficiency of the snapshot component can significantly impact performance if it cannot keep up with the workload. This can result in a backlog of intermediate data and affect performance.
Testing has demonstrated that Alluxio can handle a scale of approximately 300 million files in a small-scale scenario. However, if the aim is to support billions of files, relying solely on increasing the specifications of the storage machines is not practical. The size of the data used for model training may continue to grow, but we cannot expand the machine specifications limitlessly. To address this issue, we need to implement additional optimization strategies.
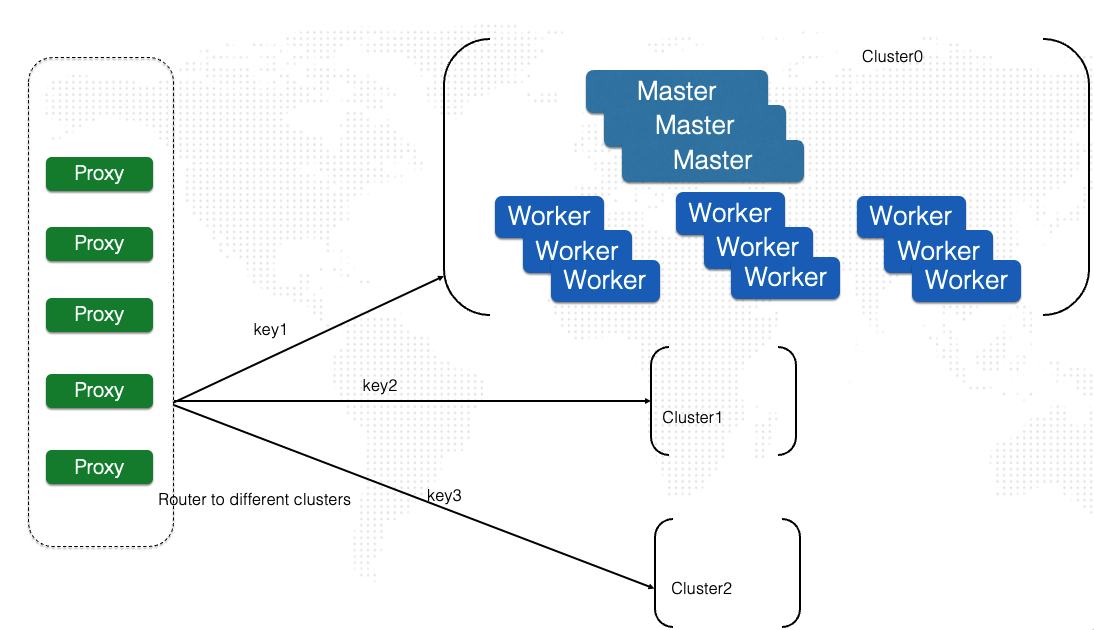
To optimize, we choose Redis’ implementation of metadata fragmentation and provision of services through multiple clusters. The fragmentation of metadata, such as large collections of whole data sets, involves hashing the data and mapping it to a specific shard. As a result, a small cluster only needs to cache a portion of the keys, enabling efficient selection. The full hash is then allocated to set cluster size, with several shards caching the entire model training file.
We added a front-end proxy that internally maintains a hash mapping table. The proxy resolves the user’s request by looking up the hash mapping and assigning it to a fixed cluster for processing. This results in a scattering of data, leading to several advantages. Firstly, the capacity of metadata increases, reducing pressure on the system. Second, the load is distributed across multiple clusters, improving overall CPS and cluster throughput capabilities. Thirdly, this approach theoretically allows for the expansion of many cluster clusters, potentially supporting a larger scale.
5. Summary
To summarize, to enable efficient large-scale training on our AI platform’s billions of files, we optimized Alluxio for reliability, performance, and scalability.
In terms of reliability, our optimization makes it possible to control the failover time of the cluster to 30 seconds or less. This, along with the implementation of client-side failover, results in seamless failover, minimizing disruptions to the users and ensuring a positive user experience. The recovery of underlying processes occurs without interrupting training on the user side, and there are no errors reported, contributing to the overall reliability of our AI platform.
Performance optimization has resulted in a threefold increase in the throughput of a single cluster, enhancing the overall performance and enabling the support of more concurrent model training tasks.
By sharding the metadata, we have made Alluxio clusters scale out dramatically.
By implementing these optimizations, we have significantly enhanced the AI training jobs for our businesses in various domains.
About the Author
Chuanying Chen is a senior software engineer at Ant Group.
Published at DZone with permission of ccy lu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments