All About GPU Threads, Warps, and Wavefronts
This article talks about the GPU threads concept, warps and warpSize, and subtle differences when using NVIDIA and AMD GPUs.
Join the DZone community and get the full member experience.
Join For FreeOn a GPU, the threads are always run as a group of threads called warps. In that sense, the granularity of thread execution is always 32 (or 64, as explained later) on GPU. If a user requests for one thread, that one thread in the warp acts as an active thread while the rest of the threads are inactive. It is not conventional to request a single thread in GPU programming.
The threads inside the warp run in parallel (and not concurrent) and execute the instructions in a SIMD (Single Instruction Multiple Data) fashion.
Let's introduce some terminology.
WarpSize defines the number of threads in a warp. On Nvidia hardware, it's always 32. So, this value can be hardcoded in programs. On AMD architecture, warpSize is referred to as wavefront, and thread size in a wavefront can be 64 or 32 based on the GPU architecture.
Since the threads inside a warp execute in parallel, it makes sense to allocate threads in multiples of warpSize, so that no threads are inactive. Anyways, that is the meaningful purpose of using a GPU for launching "n" number of parallel threads on multiple data executing the same instructions in a GPU kernel or program rather than running a single thread.
Let's consider the GPU kernel (a function that runs on GPU) with a launch configuration of 1 grid with 2 thread blocks. Each thread block has 256 threads.
__global__ void myKernel() {
// Kernel code here
}
int main() {
// ...
myKernel<<<2, 256>>>(/* arguments */); // Launches the kernel with 2 block of 256 threads
// ...
}If the warpSize is 32, then 256/ 32 = 8 warps are created on each threadBlock. Instead of 256 threads, if we specify 260, then 9 warps will be created, with the last warp having 4 active threads and 28 inactive threads, thereby wasting the full potential of GPU threads availability.
The threads from the same threadBlock are present in a warp. That means the last warp cannot have threads from multiple thread blocks. For example, it cannot have threads from threadBlock 0 and 4 threads from threadBlock 1. This is because all the threads in a threadBlock are expected to run the same instructions and can share memory if specified.
If branching is required, then the threads in the "if condition" executes the if statement code, and the other threads in the warp are masked. In the next cycle, the threads in the "else condition" execute the else statement code while the other threads are masked and just waste the cycle. This introduces serialization in the execution, though the threads inside the respective if and else blocks run in parallel.
This is known as warp divergence.
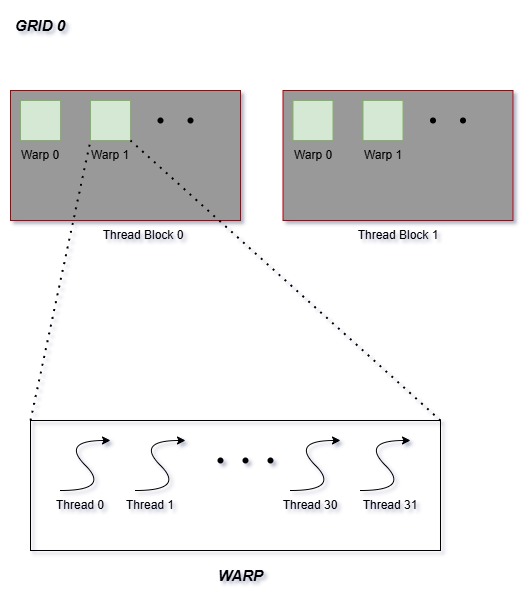
The above diagram represents a grid of 2 blocks with "n" number of threads. The threads are grouped in warps of size 32.
It makes sense to align the data buffer size to align with warpSize. This makes sure that an individual thread acts on data with respect to its own unique index.
#include<stdio.h>
#include<cuda.h>
int warp_size = 32;
__global__ void add_one(int *data, int N) {
// This function code is executed in parallel by multiple threads
int idx = threadIdx.x + blockIdx.x * blockDim.x;
printf("gpu: thread id is %d \n", idx);
if (idx < N) {
data[idx] += 1;
}
}
int main() {
int count = warp_size * 1;
int *host_data = new int[count];
// Add dummy data
for (int i=0; i < count; i++) {
host_data[i] = i;
printf("host: input data: index %d data is %d \n", i, host_data[i]);
}
int *device_data;
cudaMalloc(&device_data, sizeof(int)*count);
cudaMemcpy(device_data, host_data, sizeof(int)*count, cudaMemcpyHostToDevice);
add_one<<<1, count>>>(device_data, count); // Launch kernel with one ThreadBlock with 32 threads.
cudaMemcpy(host_data, device_data, sizeof(int)*count, cudaMemcpyDeviceToHost);
for (int i=0; i < count; i++) {
printf("host: processed data: index %d data is %d \n", i, host_data[i]);
}
delete[] host_data;
return 0;
}
In the above program, the data buffer size is in multiples of warpSize to derive efficient threads usage within GPU.
The WaveFront size on AMD GPUs is noted here.
Conclusion
In conclusion, this article highlights the importance of GPU threads and their execution, the effect of warpSize on GPU programs, and signifies the importance of warps to derive maximum GPU utilization.
Opinions expressed by DZone contributors are their own.
Comments