Amazon Neptune, The Truth Revealed
Let's check out a benchmark of Amazon Neptune as well as explore the discoveries revealed by it.
Join the DZone community and get the full member experience.
Join For FreeIn May this year, Amazon announced the General Availability of its cloud graph database service called Amazon Neptune. Here is a comprehensive blog that summarizes its strengths and weaknesses. Last year, we published a benchmark report on Neo4j, Titan, and TigerGraph. It is intriguing for us to find out how does Amazon Neptune perform relative to the other three graph databases? To answer this question, we conducted the same benchmark on Amazon Neptune. This article presents the discoveries revealed by our benchmark.
Executive Summary
Amazon Neptune provides both RDF and Property Graph models. For this benchmark, we focused on the Property Graph model, which uses Gremlin as its query interface.
- Data Loading Speed: TigerGraph loads 21x to 58x faster than Neptune.
- Storage: Amazon Neptune needs 8.0x to 9.6x more disk storage for the same input graph data.
- 1-hop and 2-hop Graph Queries: TigerGraph is at least 10x faster for 1-hop twitter data set and at least 57x faster for 2-hops for both data sets.
- 3-hop and 6-hop Queries: For 3-hop queries, Amazon Neptune returns out of memory (OOM) error on 17 out of 20 trials. Neptune could not finish 6-hop queries.
- Analytic Queries (PageRank, Connected Components, etc.): Not Supported on Neptune, supported in TigerGraph.
We have made our benchmark datasets, queries, input parameters, result files and scripts available via GitHub so that any reader can reproduce our benchmark results [1].
Setup
Dataset
We use two publicly available data sets. The first one is from graph500.org. It provides a synthetic data generator using Kronecker product. The second one is a well-known Twitter follower dataset. For each graph, the raw data are formatted as a single tab-separated edge list:
U1 U3
U1 U4
U2 U3
Table 1. Datasets

Hardware and Software
Table 2. Cloud hardware
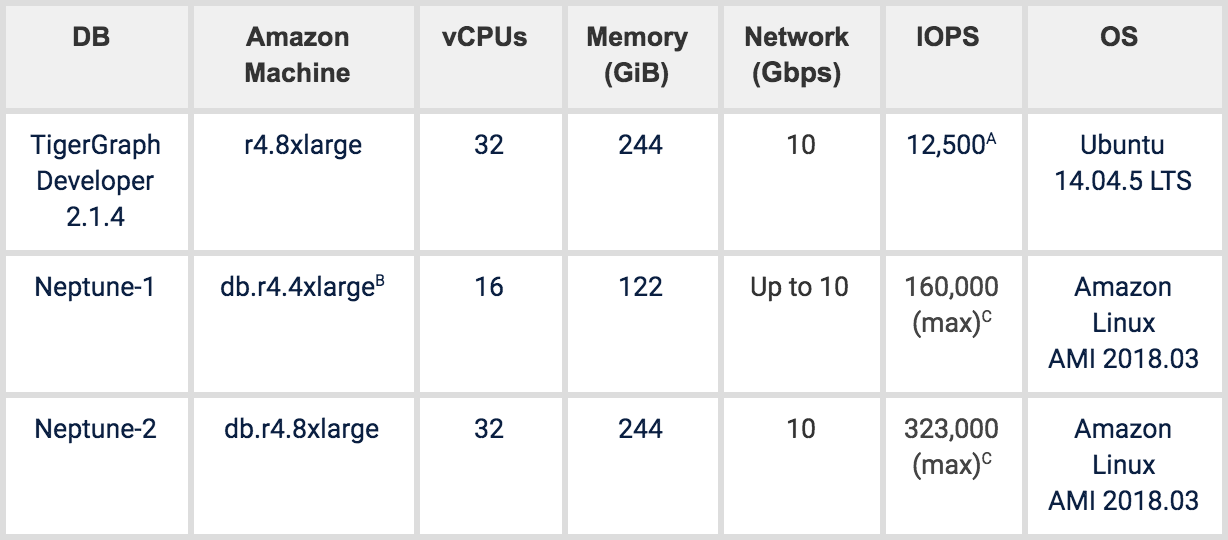
A. For r4.8xlarge, we attached a 250G EBS-optimized Provisioned IOPS SSD (IO1). It’s the storage we used to install vendor software, host raw data, host graph DB storage to ensure same IOPS during loading and querying. The IOPS we set is 50/Gib for this 250G SSD drive, producing total IOPS of 12,500.
B. Neptune DB instance has 5 classes. Each class has pre-defined configuration settings, such as CPUs, Memory, SSD, etc. Our benchmark is based on the two largest DB instance classes.
C. Amazon Neptune IOPS is observed from the Amazon Cloudwatch console.
Table 3. Amazon Neptune client machine

Tests
First, we compared the data loading performance according to the following measures:
- Time to load our benchmark data sets. The loading time includes vertex file preparation time for Amazon Neptune as it requires a specific CSV format.
- Storage size of loaded data.
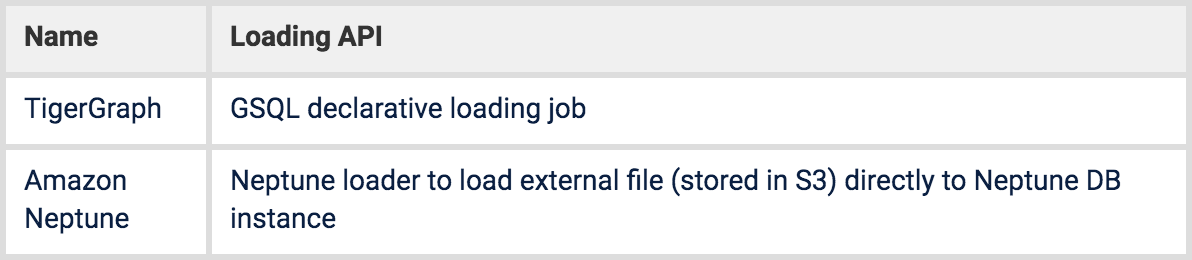
Table 4. Loading methods
Then we measured the query response times for the following queries:
- Count all 1-hop-path endpoint vertices for 300 fixed random seeds, timeout set to 3 minutes/query.
- Count all 2-hop-path endpoint vertices for 300 fixed random seeds, timeout set to 3 minutes/query.
- Count all 3-hop-path endpoint vertices for 10 fixed random seeds, timeout set to 2.5 hours/query.
- Count all 6-hop-path endpoint vertices for 10 fixed random seeds, timeout set to 2.5 hours/query.
- We attempted to test PageRank and Weakly Connected Component discovery queries, but Amazon Neptune seems to lack the language support for algorithmic queries.
By “fixed random seed”, we mean we did a one-time random selection of N vertices from the graph and saved this list as the repeatable input condition for the tests. Each path query starts from one vertex and finds all the vertices which are at the end of a k-length path. We ran the N queries sequentially. We only count how many path endpoint vertices are discovered rather than returning the set of vertices so that I/O time is not a factor. However, we also ran cross-validation tests to confirm that Amazon Neptune and TigerGraph are discovering the same set of path endpoint vertices.
Results
The figures below report the benchmarking results for loading time, DB storage size, and k-hop-path-neighbor-count query time.
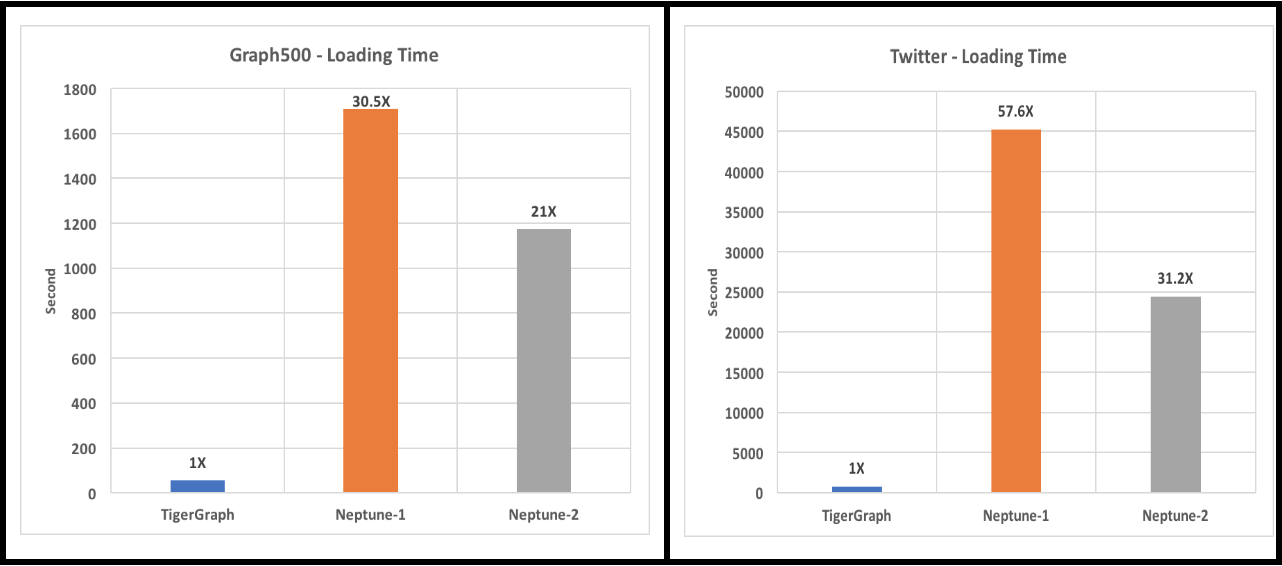
Figure 1. Loading time
Amazon Neptune loading time includes vertex file loading time, edge file loading time, and the vertex file preparation time. TigerGraph can load the edge file directly without the need to create the vertex file.
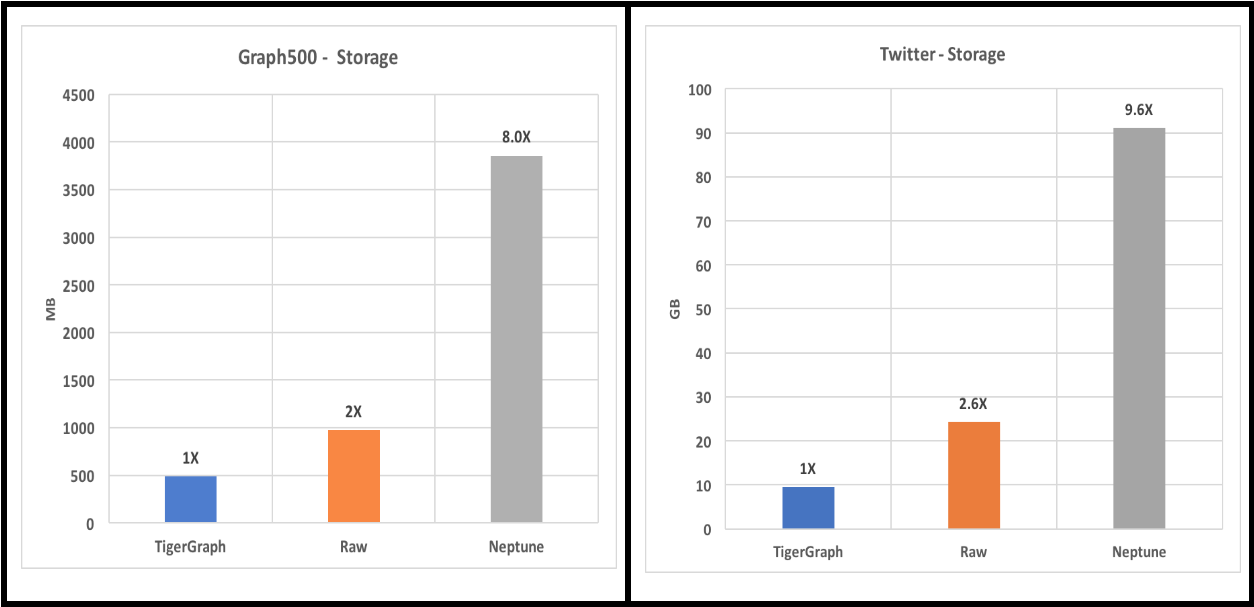
Figure 2. Disk storage size
For Amazon Neptune, we find its total storage size and divide it by 6 (the replication factor).
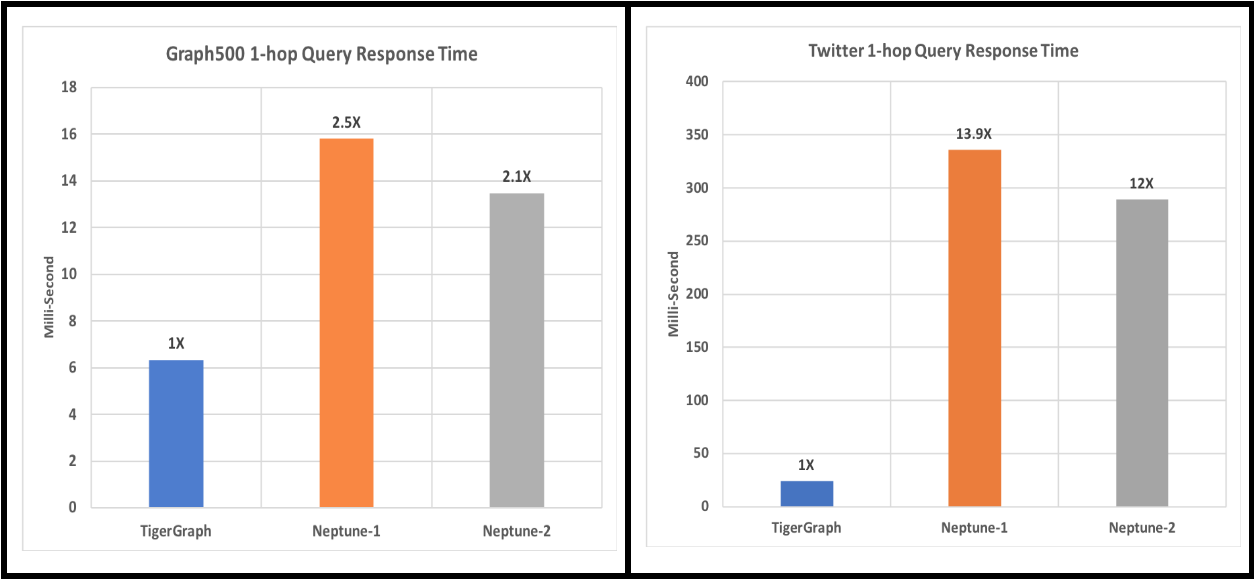
Figure 3. 1-hop-neighbor-count average query time over 300 fixed random seeds
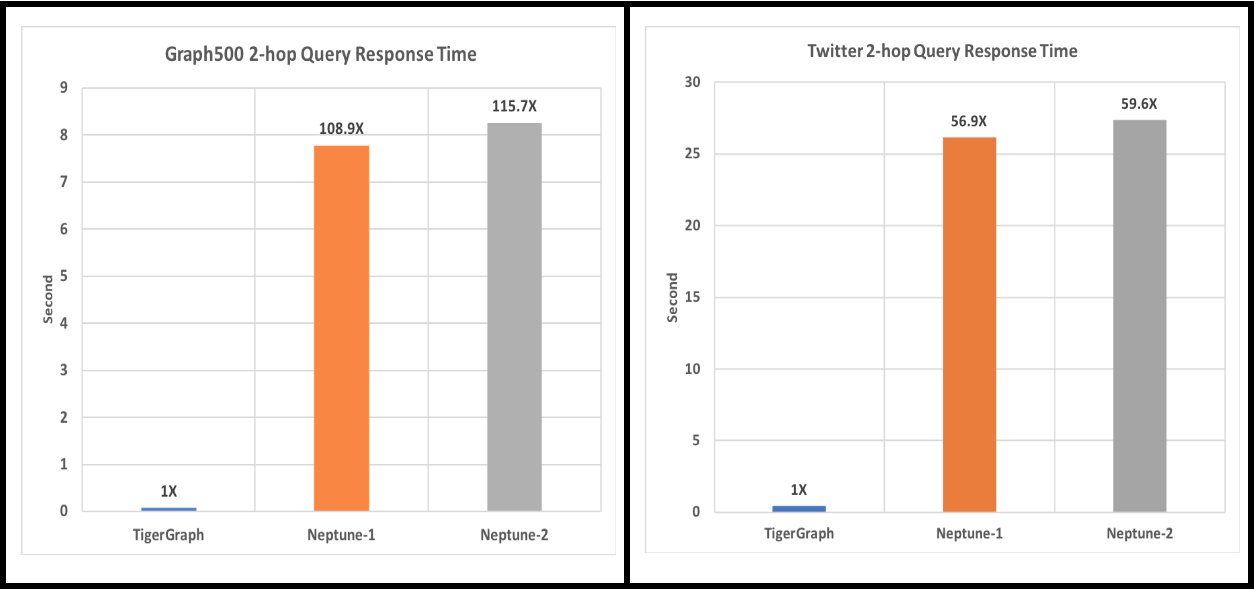
Figure 4. 2-hop-neighbor-count average query time over 300 fixed random seeds
For the graph500 data, Neptune-1, one of the 300 queries timed out. For Twitter data, Neptune-1 had 63 query timeouts, and Neptune-2 had 60 query timeouts.
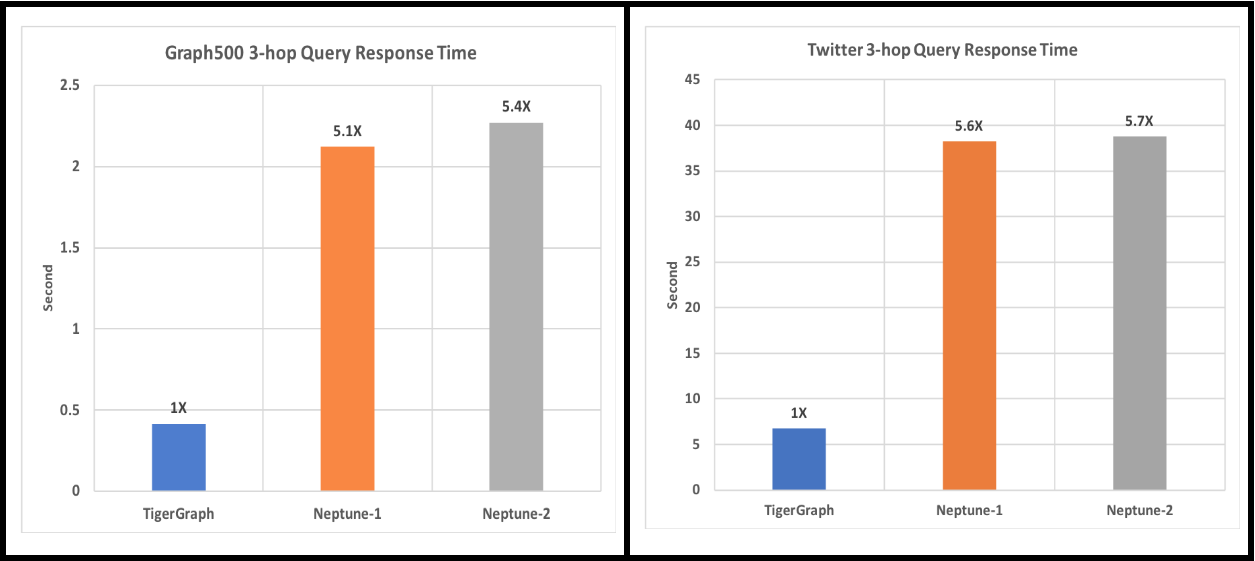
Figure 5. 3-hop-neighbor-count average query time over 10 fixed random seeds
For graph500 data, Neptune-1 and Neptune-2 both had 8 of the 10 queries fail due to Out-Of-Memory (OOM) error. For Twitter dataset, both Neptune-1 and Neptune-2 had 9 out of 10 queries fail due to OOM.
Table 6. Loading Time for graph500
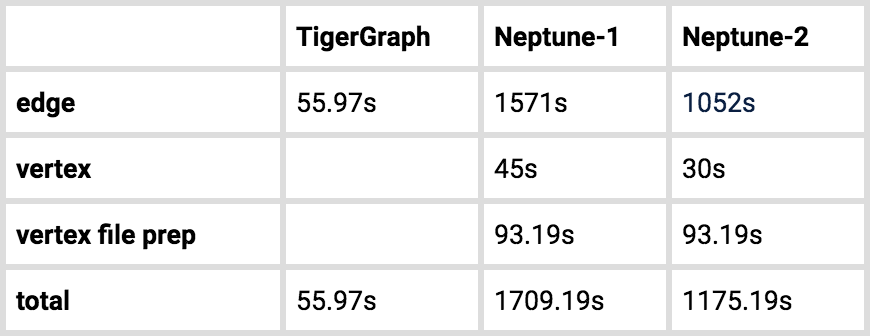
Table 7. Loading Time for twitter
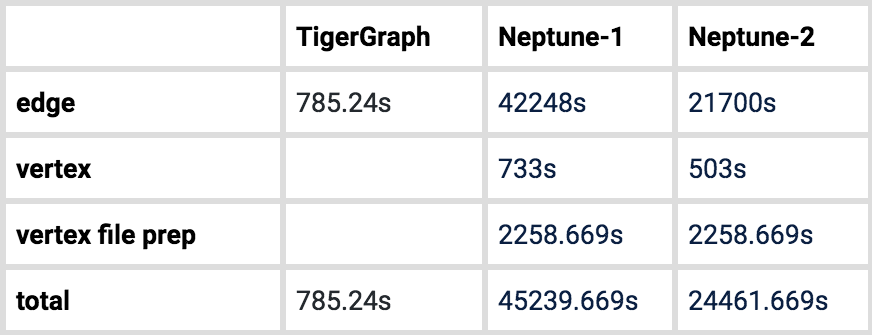
Neptune requires that a separate vertex file be loaded before loading edges. We counted the time required to extract vertex data from the edge file and to load the vertex file.
Table 8. Average time of K-hop-path-neighbor count query for graph500
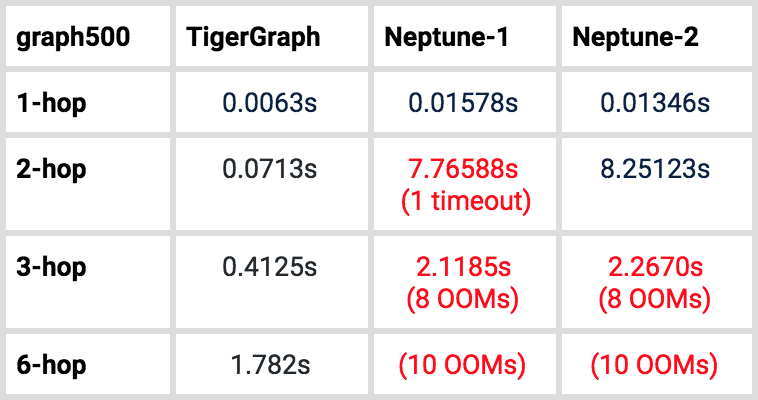
Table 9. Average time of K-hop-path-neighbor count query for twitter.
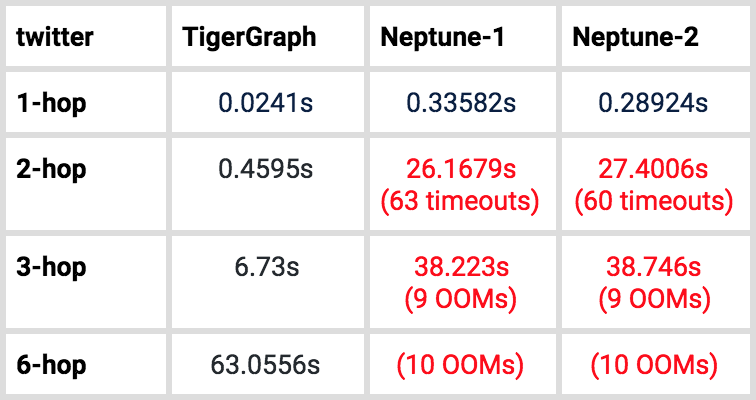
We do not include timeout/OOM queries in Average Time of K-hop-path-neighbor calculation.
Discussion
In this section, we discuss some of the differences between the products, which are relevant to these tests.
Amazon Neptune
Neptune provides a bulk loader, which can ingest data from Amazon S3 storage only, so users must first put their data in S3. The maximum storage limit of Neptune is 64TB [2]. For property graphs, data files must be in CSV format. Also, the graph’s property types can only be simple scalar types [3], while TigerGraph property types can be scalar plus complex types such as map, list, and set. Neptune also loads vertices and edges separately. We had to prepare for loading by extracting the vertex IDs from the edge file and then writing them to a properly formatted file. We recorded the peak IOPS of the two instances benchmarked. From the Amazon Cloudwatch console, we observed that their IOPS performance is much better than that of the TigerGraph EC2 machine’s SSD. Despite better hardware, the Neptune loading is still 21x – 57.6x slower than TigerGraph’s.
For the 1-hop query, both instances of Neptune can finish each of the 300 random input cases within the 3-minute timeout setting. However, for 2-hop queries, on the graph500 data, Neptune-1 had one query timeout. On the larger Twitter dataset, Neptune-1 had 63 query timeouts, and Neptune-2 had 60 query timeouts. Worse, for 3-hop queries, on the graph500 data, Neptune-1 and Neptune-2 both had 8 queries out of 10 run out of memory, meaning they could not finish the test at all. On the Twitter dataset, both Neptune-1 and Neptune-2 had 9 queries run out of memory. Lastly, Amazon Neptune cannot answer any of the 6-hop queries tested. We reiterate that Neptune instances come in fixed configurations, and we tested the largest ones available.
Amazon Neptune does not support VertexProgram from the Gremlin OLAP API [4]. Therefore, we could not run analytic queries such as Weakly Connected Component or PageRank.
Neptune supports server node replication by creating up to 15 read replicas [2]; however, it does not support a distributed database where the data are partitioned across a cluster. In this experiment, we used only a primary node (without read replicas).
A Neptune instance comes with one built-in graph. It does not allow users to create multiple graphs.
TigerGraph
TigerGraph has a high-level loading language with built-in ETL, so it can accept many different input formats and perform data transformations. One feature is that users can load an edge file without any vertex files if there are no properties on the vertex. This situation applies to the two data sets here.
Not only does TigerGraph load data at least 20x faster than Amazon, but it stores it in less space. This means TigerGraph can store a larger database in the same amount of memory. It also suggests faster data access, because CPU caches will be able to hold a larger portion of the graph.
All of the k-hop queries finished, without memory or timeout problems. Moreover, TigerGraph’s GSQL language can implement OLAP type queries, such as Weakly Connected component and PageRank. Since they are written in standard GSQL, the user is free to customize these queries.
If you are interested in learning more about TigerGraph here are some helpful resources:
- Download the TigerGraph Developer Edition: https://www.tigergraph.com/developer/
- Download the GSQL White Paper: https://info.tigergraph.com/gsql
- Download the Neptune Benchmark: https://info.tigergraph.com/tigergraph_vs_neptune
References
[1] Script for reproducing Neptune benchmark and TigerGraph benchmark https://github.com/tigergraph/ecosys/tree/benchmark/benchmark/neptune
https://github.com/tigergraph/ecosys/tree/benchmark/benchmark/tigergraph
[2] Neptune read replica and storage limits https://aws.amazon.com/neptune/faqs/
[3] Neptune CSV load data types https://docs.aws.amazon.com/neptune/latest/userguide/bulk-load-tutorial-format-gremlin.html
[4] Neptune does not support VertexProgram https://docs.aws.amazon.com/neptune/latest/userguide/access-graph-gremlin-differences.html
Opinions expressed by DZone contributors are their own.
Comments