An Insider’s View of MySQL Group Replication
Get a good look at how MySQL enables high availability through its Group Replication plugin from the leader of the replication team.
Join the DZone community and get the full member experience.
Join For FreeBecause of MySQL’s high-performance, scalability, and availability, it has been widely popular for web applications and has become a foundation for IT platforms that support high-traffic social media portals, e-commerce applications, and fast-growing organizations.
With the latest MySQL 5.7.17 update release, MySQL Group Replication is now available on Oracle Cloud and offers native, built-in high availability for MySQL databases.
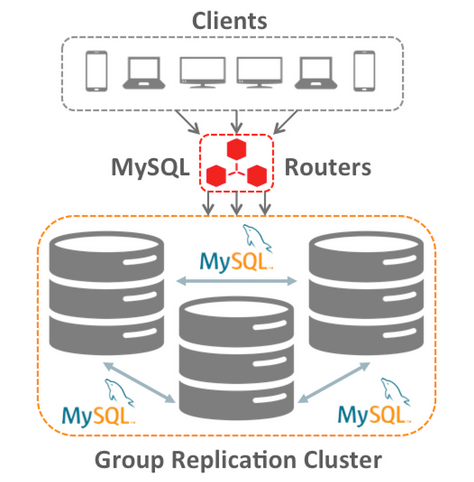
To gain deeper insight into the benefits and use cases of MySQL Group Replication, we had the pleasure to interview Nuno Carvalho, the team lead for MySQL Group Replication, and get his insider perspective.
Q: Hi Nuno, could you give us a little background about yourself and tell us what you do at MySQL?
A: Absolutely! Before coming to MySQL, I was a post-graduate student and a researcher at the University of Minho in Portugal. My work focused on designing and implementing techniques to improve scalability for distributed systems. Five years ago I joined Oracle as a developer on the MySQL replication team. One day, the opportunity to work on Group Replication was presented to me, and my small team took on the task of making it happen. Currently, I'm a Principal Software Engineer and the MySQL Replication Service Team Lead at Oracle. My team is in charge of the MySQL Group Replication plugin.
Q: Before we dive into Group Replication, could you tell us what MySQL replication is and why it's such a popular feature for MySQL?
A: MySQL replication is a simple and effective way to spread data among several servers, with three main goals:
Availability: We can avoid the issue of single point of failure by replicating data to several locations.
Scalability: The application can serve more requests by sending read operations to replicas and allowing the primary server to handle only the write operations.
Overcome the single server limit: Eventually, all big users will reach the point when their data no longer fits in a single server. The solution is to shard data across multiple servers, and it needs replication to take care of data flow for the sharding to operate effectively.
MySQL replication is very easy to set up and it performs extremely well, so MySQL developers and DBAs love to use this feature to scale out and to provide high availability for their MySQL environments.
Q: What triggered the development of MySQL Group Replication if the existing MySQL replication is already a great solution?
A: MySQL replication is an asynchronous replication, so to avoid confusion between the traditional MySQL replication and the new MySQL Group Replication, I’ll call the existing MySQL replication “MySQL asynchronous replication” moving forward.
As mentioned previously, many MySQL developers and DBAs use MySQL asynchronous replication for scaling out — using the primary server to handle all the writes and the replicas for read operations. In this scenario, if for any reason the primary server fails or needs to be taken down for maintenance or upgrade, the DBA has to manually failover the primary server to one of the replicas, direct the write traffic to the new primary, and configure all the replicas to replicate from it. Once the previously-failed server goes back online again, the DBA has to manually add the server back to the replication topology and configure it appropriately.
This is not a big problem if you only have one primary and two replicas, but consider the situation when you have tens or hundreds of replicas, or even multiple layers of replication in your topology: handling all these tasks manually becomes very complicated, time-consuming and error-prone for DBAs. As the number of MySQL users grows, so does the usage of MySQL with business-critical applications and its footprint within organizations. The request to have a fault-tolerant MySQL system became a high priority for our customers and also for the MySQL engineering team at Oracle. And so my team started on the journey of creating MySQL Group Replication.
Q: It’s great to hear the story behind product development and that’s actually a good transition to our topic for today: What is MySQL Group Replication and how does it work?
A: MySQL Group Replication is a MySQL Database plugin that enables developers and DBAs to create elastic, highly available, fault-tolerant replication topologies. It’s a mechanism that manages a group of servers and presents it as if it’s a single server because all the servers in the same group do the same operations and have the same data. Having multiple copies of the same data set minimizes the risk of losing that data.
MySQL Group Replication can be operated in two modes:
1. Single-primary mode: in this mode, only one server accepts updates at a time, so it’s almost like a drop-in replacement for any single server, but with built-in high availability. In the case that the primary server fails, the group automatically elects a new primary, and there is no interruption to the service as everything happens in the background.
2. Multi-master mode: in this mode, all servers can accept updates, even if they are issued concurrently. The built-in group membership service keeps the view of the group consistent, and it’s available for all servers at any given point in time. Servers can leave or join the group, and the view would be updated accordingly. In the case when a server leaves the group unexpectedly, the built-in failure detection mechanism would detect this event and notify the group that the view has changed. And when a server joins, the group would go through a distributed recovery stage so updates will be provided to the group before handling requests. All these operations happen automatically with no manual intervention needed.
Q: How is MySQL Group Replication different from other MySQL replication mechanisms?
A: MySQL Group Replication, despite providing the same look and feel as a single server, it has a completely new implementation in the transport layer.
MySQL asynchronous replication uses typical TCP connections between the primary server and its secondary servers, and these operations are not coordinated. For example, if a primary has two secondary servers, it is not simple to ensure that data is replicated at the same time to both of the secondary servers. This makes handling failovers a very complex process for the administrator.
On the other hand, MySQL Group Replication is based on a Paxos implementation, which ensures that all servers receive the same set of data in the same order. This allows us to establish a logic clock among the group and thus all operations, such as real-time group membership or primary election in the single-primary mode, can be controlled according to that clock. With such implementation, MySQL Group Replication performs much better in terms of durability compared to the typical MySQL asynchronous replication.
Q: How does MySQL Group Replication help DBAs?
A: When MySQL asynchronous replication is used, DBAs are responsible for manually handling failures and primary failovers when the machine fails or during scheduled maintenance on the primary server. With the built-in group membership management in MySQL Group Replication, those tasks are managed automatically, no matter when a member is removed intentionally, such as for maintenance, or by accident due to machine failure. MySQL Group Replication provides data consistency guarantees, conflict detection and handling, node failure detection, and database failover-related operations, all without the need for manual intervention or custom tooling. When issues occur, the group has the capability to manage necessary failover and heal itself.
This is a major step forward on automating DBAs’ tasks. With MySQL Group Replication, DBAs not only save the time they otherwise would have had to spend on manually configuring necessary failovers during scheduled maintenance; more importantly, it removes the burden from DBAs to configure failovers and other necessary settings correctly during stressful disaster recovery. Since the failover process is automated, the failover time is significantly reduced in the case of server failure. For MySQL asynchronous replication, when the primary server fails, it takes from 5 seconds to a minute or more for the failover to complete, depending on the workload and mainly on how the primary failure is detected. With MySQL Group Replication, since we have a group of servers, if one fails, the failover is immediately taken care of by the group automatically. That is a huge improvement in high availability and also there is no single point of failure.
Q: How do developers benefit from MySQL Group Replication?
From the developers’ perspective, the best part of implementing MySQL Group Replication — using the single-primary mode — is that almost no change is required at the application level! Just minimal change in the code and much higher availability for the application — how great is that? Existing applications can be easily adapted when the underlying infrastructure moves from a single server to a group of servers managed by MySQL Group Replication, and developers can expect that the usual behavior of InnoDB, Performance Schema as well as other MySQL components.
A quick note to developers thinking about trying out MySQL Group Replication: transactions may rollback on commit due to conflicts between concurrent operations, given the distributed fashion in the architecture. For example, if you have a group of three, when two transactions are issued in parallel to two different servers and they touch the same row, one of them will be rolled back and only one will be committed. This is the difference developers should be aware of when you replace a single server with Group Replication.
Another benefit Group Replication offers for developers is guaranteed durability. MySQL Group Replication only acknowledges the commit once it reaches the majority of servers in the group. Therefore, even if some servers fail, the data is never lost because the majority already has it. This is really, really important for developers.
Q: What has the feedback been from MySQL users?
A: MySQL Group Replication has only been generally available since December 2016, so most of our users are either testing this feature or using it in their pilot programs. So far we’ve heard a lot of positive feedback from those early adopters. They especially like the fact that this feature is really easy to use and deploy, with almost no change required in the application. We also received very useful input from our users, which we’re using to make MySQL Group Replication even more powerful and user-friendly.
Q: Now MySQL Group Replication is also available in the Oracle MySQL Cloud Service. What additional benefits do you foresee by having this feature in the cloud?
A: With MySQL Group Replication available in Oracle MySQL Cloud Service, the biggest and most immediate benefit is that users have everything they need all together, at one place. With a few clicks, our users can access the latest and greatest replication technology for MySQL on the best hardware, with optimal configuration. The end user will be able to easily create elastic, highly available, fault-tolerant MySQL replication deployment.
Here is a good example: with all the great capabilities I mentioned earlier about MySQL Group Replication, some DBAs may be very interested in trying it out, but they may be hesitant because they would have to buy five machines and deploy five machines to take advantage of the benefits of having a (5-member) group. Considering the time and money required to purchase and configure five machines only to test MySQL Group Replication, the idea of trying out this new feature seems less appealing. On the other hand, having MySQL Group Replication in Oracle MySQL Cloud Service, the entire process becomes very easy. Those DBAs only need to click a few buttons and request five MySQL instances in Oracle Cloud, and the service is ready to go in a matter of minutes — far faster than acquiring and configuring five physical servers! This scenario would be perfect for many or even most customers in my opinion.
Q: What future enhancements can users look forward to?
A: We are always working to make MySQL Group Replication, and MySQL replication in general, even easier to use and more performant. There are two areas of performance enhancements we are currently working on for MySQL Group Replication: the first is to minimize the performance overhead or impact when MySQL Group Replication is enabled; the other is to further increase the number of members we can support in one group.
Q: Any parting words you'd like to share with us?
A: MySQL Group Replication was a huge team effort, and it is great to see it already being used by costumers and to hear their positive feedback. It has been a pleasure to take an active part in the creation of this product.
Thank you, Nuno, for sharing your insight into MySQL Group Replication! To learn more, visit the MySQL High Availability info page for presentations, documentation, and additional resources.
Published at DZone with permission of Wei-Chen Chiu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments