AI Paradigm Shift: Analytics Without SQL
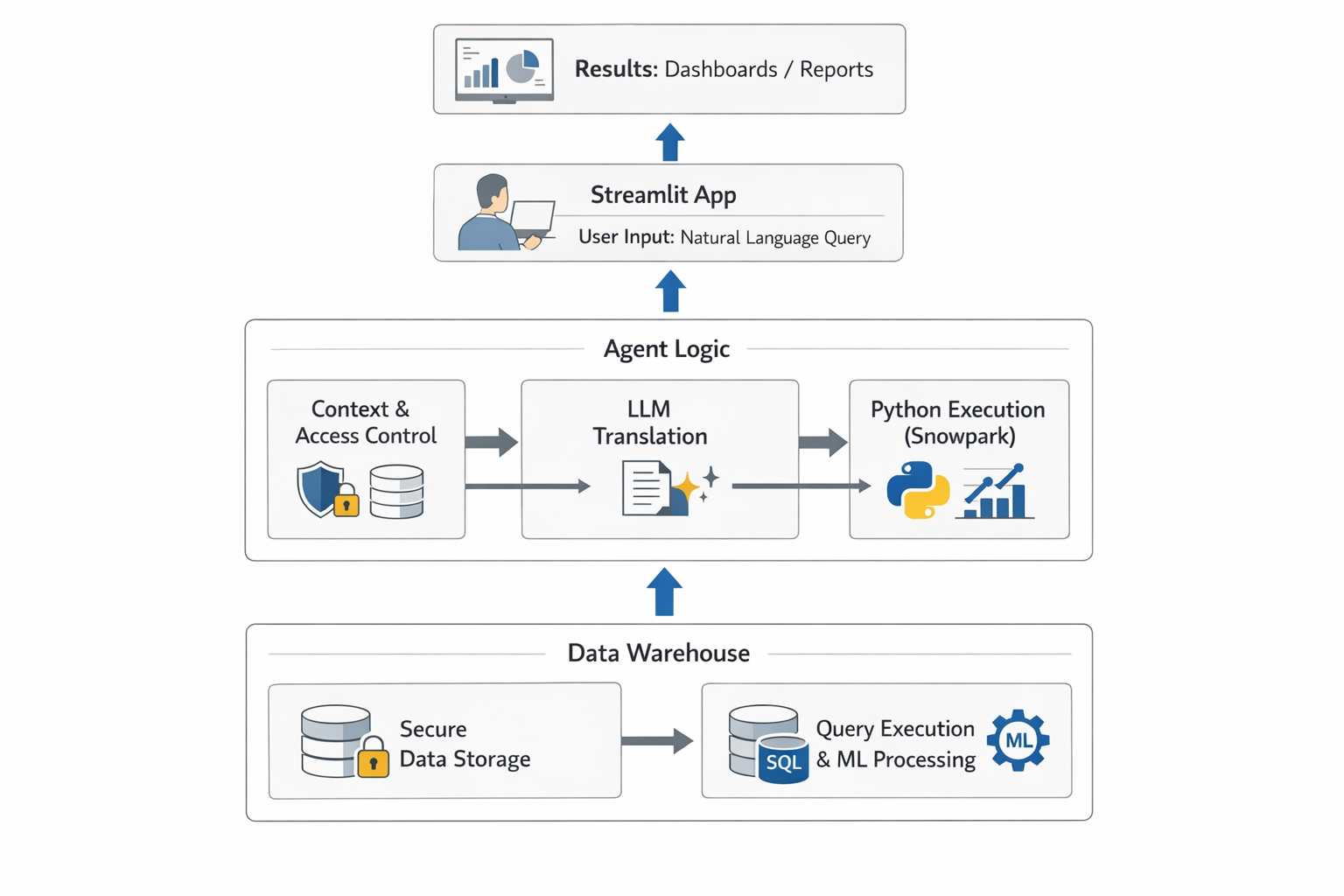
An AI-native analytics agent sits between users and the data warehouse, translating natural-language questions into governed SQL or Python workflows and dashboards.
Join the DZone community and get the full member experience.
Join For FreeThe idea of “asking data questions in plain English” has been around for a while, but most implementations never made it into production in a serious way. The usual reason is not the language model itself but everything around it: security boundaries, schema ambiguity, cost control, and the fact that analytics systems are rarely clean enough for unconstrained natural language to work reliably.
What has changed in the last couple of years is not that natural language is suddenly perfect, but that data platforms have started bringing computation, metadata, and AI into the same controlled environment. One example of this approach is the way agents are being built directly inside data warehouses like Snowflake. The important detail is not the brand itself, but the architectural pattern: the model, the data, and the execution layer sit together rather than being stitched across multiple systems.
That shift changes how analytics tools are designed. Instead of building external “AI layers” on top of a warehouse, teams are embedding the agent logic inside the warehouse itself using tools like Snowpark and managed LLM services such as Snowflake Cortex. The result is a system where natural language is just another input format, not a separate application tier.
From Dashboards to Agent-Driven Querying
Traditional analytics workflows are structured around predefined models: dashboards, semantic layers, and curated datasets. A user question is usually translated into one of these prebuilt views. If the question does not fit, someone writes SQL or updates the dashboard.
Agent-based systems invert this flow. Instead of forcing questions into predefined structures, they attempt to generate the structure dynamically.
At a high level, the flow looks like this:
- A user submits a natural language question
- The system enriches the prompt with schema and access context
- A model generates SQL or an execution plan
- The query runs inside the warehouse
- Results are returned in a structured form or visualized output
The key difference from earlier “text-to-SQL” experiments is that steps two and three are tightly grounded in the database context. The model is not guessing a schema from generic training data. It is being provided with actual table definitions, column descriptions, and sometimes usage statistics.
This context injection is what makes the system usable in production. Without it, SQL generation tends to fail in subtle ways: incorrect joins, wrong aggregations, or hallucinated columns.
Agent Architecture Inside the Warehouse
A practical implementation of an analytics agent inside a warehouse typically has three layers.
1. Context and Permission Layer
Before any model is called, the system resolves what the user is allowed to see. This includes:
- Role-based access control
- Row-level filters
- Column masking rules
- Available schemas and tables
This step is often underestimated, but it is what makes the system safe enough for real usage. Without it, natural language becomes a bypass mechanism for data access control.
2. Language Model Translation Layer
Once context is assembled, the prompt is passed into an LLM hosted within the data platform. In Snowflake’s case, this is handled through Cortex services, but the pattern is not unique to any vendor.
The model’s job is not just to produce SQL but to produce SQL that is:
- Syntactically valid
- Aligned with schema constraints
- Consistent with security rules
- Optimized for warehouse execution patterns
For example, a question like, “Show top 10 products by revenue in Q1 2024 grouped by region,” might become:
SELECT
region,
product_name,
SUM(revenue) AS total_revenue
FROM sales.fact_sales
WHERE transaction_date >= '2024-01-01'
AND transaction_date < '2024-04-01'
GROUP BY
region,
product_name
ORDER BY
total_revenue DESC
LIMIT 10;The challenge here is not generating SQL that looks correct, but ensuring it respects business definitions. Revenue, for example, might need to be net of returns or adjusted for currency conversion, depending on the organization.
3. Execution and Governance Layer
Once SQL is generated, it is executed inside the warehouse engine. This is where the architecture becomes important: nothing leaves the system. The same security policies that apply to human-written queries apply here as well.
Because execution happens inside the warehouse, audit logs remain consistent. Every agent action can be traced as a query event, which is important for compliance-heavy environments.
Why Snowpark Matters in This Setup
Tools like Snowpark extend this model beyond SQL generation. Instead of limiting the agent to query rewriting, Snowpark allows it to execute Python-based logic directly next to the data.
This becomes useful when the question is not purely relational.
For example: “Forecast next month’s sales for product X.” A simple SQL query cannot answer this. The agent can instead generate a Snowpark Python job that:
- Extracts historical time series data
- Converts it into a DataFrame
- Applies a forecasting model such as ARIMA or Prophet
- Writes predictions back into a table
The important point is that the data is never exported to an external notebook environment. The compute moves to the data, not the other way around.
This pattern also applies to machine learning inference. Pretrained models can be registered as user-defined functions, and the agent can call them like regular SQL functions:
SELECT
feedback_text,
predict_sentiment(feedback_text) AS sentiment_score
FROM customer_feedback;From a systems perspective, the agent becomes a planner rather than just a translator. It decides whether SQL is sufficient or whether a Python-based workflow is required.
The Streamlit Layer: Turning Queries Into Applications
While the warehouse handles computation and the agent handles reasoning, users still need an interface. One of the simpler ways to build this layer is with Streamlit.
Streamlit is often used because it reduces the overhead of building internal analytics tools. Instead of designing full frontend systems, teams can wrap agent logic into lightweight interactive apps.
A minimal pattern looks like this:
import streamlit as st
st.title("Data Agent Interface")
query = st.text_input("Ask a question about your data")
if query:
result = run_agent(query)
st.subheader("Generated SQL")
st.code(result["sql"])
st.subheader("Results")
st.dataframe(result["data"])In more mature setups, the Streamlit layer becomes more than a query box. It evolves into a dynamic dashboard generator:
- Charts are generated based on query intent
- Filters are derived from schema metadata
- Results can be saved into reusable views
- Users can refine queries conversationally
This reduces dependency on static dashboards, which are often slow to update and hard to maintain.
Governance Is the Real Constraint, Not AI Capability
A common misconception is that the main challenge in building these systems is model accuracy. In practice, governance is the harder problem.
Three constraints usually define whether an agent system is viable:
- Data access control must remain intact. Natural language cannot become a bypass layer for restricted data.
- Query cost must be predictable. Poorly generated queries can become expensive quickly in large warehouses.
- Results must be reproducible. Two identical questions should not produce different interpretations unless the underlying data changes.
Warehouse-native architectures help with this because they centralize execution. There is no separate “AI data layer” that can drift from governance rules.
Limitations of the Current Approach
Despite progress, these systems are not fully autonomous analytics engines.
There are still recurring issues:
- Ambiguous business definitions lead to incorrect aggregations
- Complex joins across poorly modeled schemas still fail frequently
- LLMs may overgeneralize metrics like revenue or churn
- Latency increases when multi-step reasoning is required
In practice, most teams deploy agents as assistants rather than replacements for BI systems. They are good at exploration, not final reporting.
Closing Thoughts
What is emerging is not a replacement for SQL or dashboards, but a new interface layer on top of them. Natural language becomes a routing mechanism that decides how to query or compute over structured data.
The interesting architectural shift is that the intelligence layer is moving closer to the data itself. Whether implemented in Snowflake or other platforms, the pattern is consistent: context-aware models, governed execution, and embedded compute through tools like Snowpark and Cortex.
Streamlit or similar tools then complete the stack by providing a lightweight interface that can evolve from simple query boxes into full analytical applications.
The result is not “analytics without SQL” but something more realistic: analytics where SQL is still present, but no longer the only way in.
Opinions expressed by DZone contributors are their own.
Comments