When Valid SQL Was Still the Wrong Answer
A personal project exploring why AI-generated SQL isn't always trustworthy and how semantic context, validation, and governance improve analytics accuracy.
Join the DZone community and get the full member experience.
Join For FreeEditor’s Note: The following is an article written for and published in DZone’s 2026 Trend Report, Cognitive Databases, Intelligent Data: Unified Infrastructure for Vector Search, AI-Optimized Queries, and Hybrid Workloads.
I started working on a personal project with a simple question: If AI can analyze a database schema and generate SQL, what still makes the answer hard to trust?
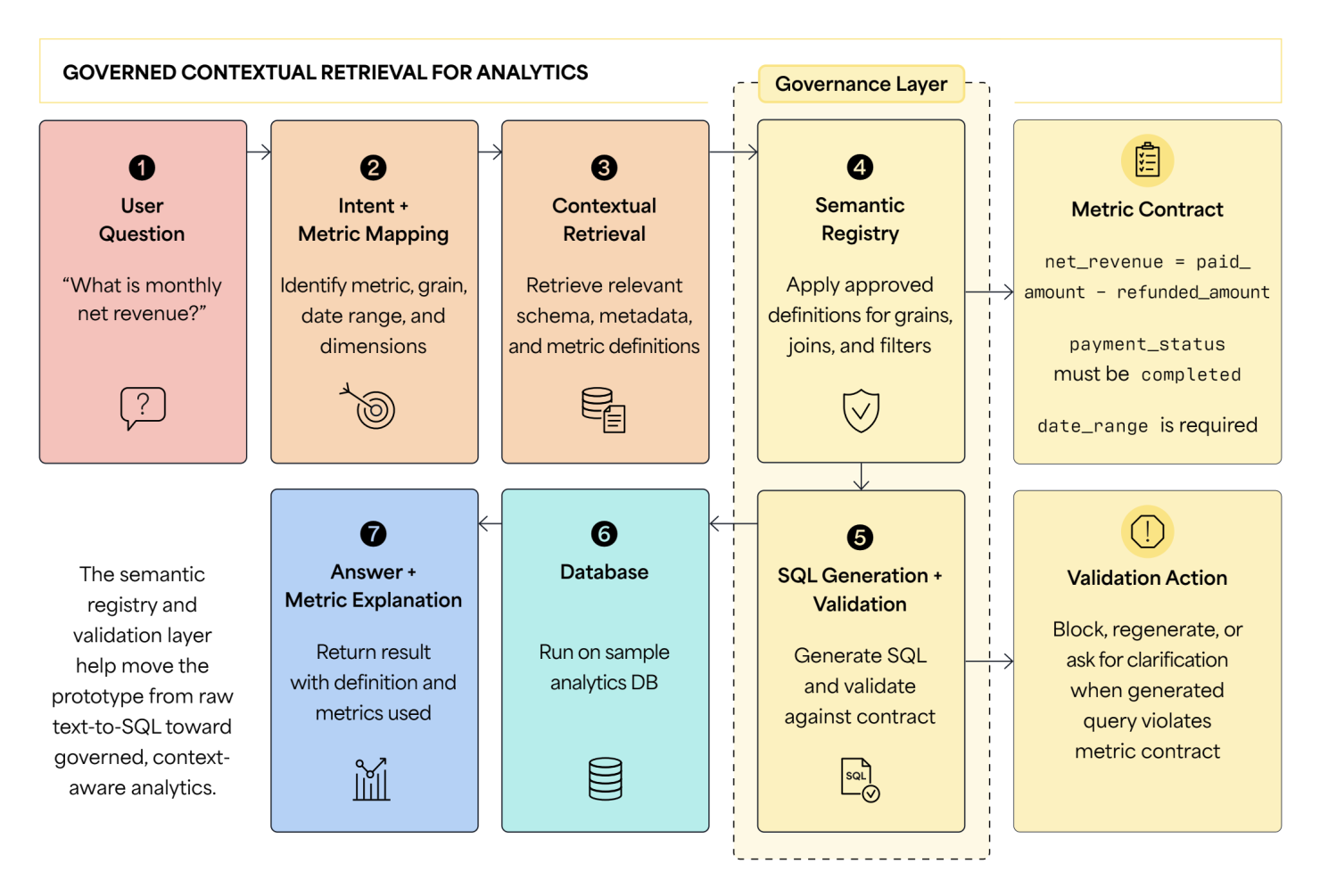
The first version of my prototype worked at a surface level. A user could ask a business question, and the system would retrieve the relevant schema, generate SQL, run the query against a sample analytics database, and return a result. Technically, that felt like progress. But then I tested a question like, What is monthly revenue? The SQL ran. The database returned an answer. Still, I could not say the answer was truly correct because the meaning of revenue was not clear enough.
After that test, I stopped treating the prototype as a text-to-SQL demo. I started handling it as an experiment in the database context that an AI assistant needs: metric definitions, semantic retrieval, validation rules, and governance signals.
The semantic registry and validation layer help move the prototype from raw text-to-SQL toward governed, context-aware analytics.
The Problem: Context Is Not the Same as Understanding
The model could write SQL; the problem was that SQL execution alone did not prove the answer was right. In my database, monthly revenue could mean net revenue after refunds, gross order value, or paid revenue. Active customer could mean a customer with a login, a purchase, or both. Even if the model retrieved the right tables, it still needed to understand which business definition to use.
The main failure signals were:
- Metric names that had more than one possible meaning
- Multiple date columns that could change the answer
- Joins that were technically possible but not analytically safe
- Missing filters like date range, status, or region
- Questions that needed clarification before execution
The Constraints: Keep It Small, But Make It Reliable
Because this was a personal project, I was not trying to build a full BI platform or enterprise data catalog. I wanted to focus on one narrow and realistic piece: how to make an AI-generated database answer more trustworthy before it reaches the user.
Table: Prototype Boundaries
| Constraint | Design Response |
|---|---|
| Small project scope | Focused on a few high-risk metrics |
| Ambiguous business terms | Created explicit metric contracts |
| The schema alone was not enough | Added semantic retrieval over definitions |
| No analyst review step | Added validation before SQL execution |
| Simple user experience | Used clarification instead of exposing schema complexity |
The hard part was keeping the prototype lightweight without making it too shallow. I wanted enough structure to make the answers safer, but not so much complexity that the project turned into a full governance platform.
The Tradeoffs: What I Changed in the Pipeline
The first major decision was to add a lightweight semantic registry. Each metric contract included the metric name, definition, grain, default date column, required filters, safe dimensions, and approved join path.
metric: net_revenue
definition: paid_amount - refunded_amount
grain: month
date_column: payment_date
required_filters:
- payment_status = 'completed'
clarify_if_missing:
- date_rangeI almost relied only on schema retrieval because it was easier to build. But the schema only tells the model what exists. It does not tell the model what is correct for a specific business question.
The second decision was to retrieve both schema metadata and metric definitions. This made the retrieval step more useful because the model was both matching a question to tables and grounding the answer in business meaning.
The third decision was to validate SQL before execution. The generated query had to pass checks for allowed tables, approved joins, required filters, and selected dimensions. If it failed, the system either regenerated the query with stronger constraints or asked the user a clarification question.
Table: Decisions, Tradeoffs, and Outcomes
| Choice | Tradeoff | Outcome |
|---|---|---|
| Add metric contracts | More setup work | Clearer business meaning |
| Retrieve semantic context, not just schema | More retrieval complexity | Better grounding |
| Validate before execution | Slightly slower response | Fewer misleading answers |
What Changed
The biggest lesson was that query execution is not the same as analytical correctness. A query can run successfully and still answer the wrong question. The prototype became more reliable when I stopped treating the database as just tables and columns. The model needed more context: what the metric means, which joins are safe, which filters are required, and when it should ask the user for clarification.
My main takeaway was practical: Before tuning prompts, define the meaning layer the prompt is expected to respect.
For intelligent data systems, the interesting work is not only faster retrieval or cleaner SQL. It is the connection between data, definitions, governance rules, and answers people can trust.
This is an excerpt from DZone’s 2026 Trend Report, Cognitive Databases, Intelligent Data: Unified Infrastructure for Vector Search, AI-Optimized Queries, and Hybrid Workloads.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments