Parser Generators: ANTLR vs JavaCC
A performance review of two parser generators: Java CC and ANTLR. One of them is a clear winner according to the measurements.
Join the DZone community and get the full member experience.
Join For FreeANTLR (ANother Tool for Language Recognition) is a parser generator developed by Terence Parr, it is extremely versatile and is capable of generating parsers in multiple programming languages, but requires a runtime library.
ANTLR Features:
- ALL(*) or ALL(k) Parser Generator (an adaptive top down parser with arbitrary token lookahead, ie there is no need to specify the lookahead k)
- Capable of generate parsers in a number of different programming languages including Java, C#, Python and JavaScript
- A runtime library is required.
- A good level of support in the most popular IDEs
- Version 4 JIT Compiles the parser
- The lexer, parser and abstract syntax tree can all be generated from a single grammar file.
- Parse tree is built automatically.
- Supports parsing modes for mixed language documents.
- Support for semantic and syntactic predicates.
- Grammar Definition is EBNF like.
- A book is available about ANTLR here
Example Syntax
A JSON parser written in ANTLR.
grammar JSONParser;
/*
* ==============================================
* ==============================================
* Parser Rules and AST generation are defined/
* handled in this section
* ==============================================
* ==============================================
*/
jsonObject : LBRACE nameValuePairList RBRACE ;
array : LSQR valueList RSQR ;
nameValuePairList : nameValuePair (COMMA nameValuePairList)* ;
nameValuePair : name COLON value ;
name : STRING;
valueList : value (COMMA valueList)* ;
value : (jsonObject | array | STRING | NUMBER | booleanValue) ;
booleanValue : TRUE | FALSE ;
/*
* ==============================================
* ==============================================
* Lexer token deinifitions are defined in this section.
* ==============================================
* ==============================================
*/
STRING : '"' STRING_CONTENT '"' ;
TRUE : 'true' ;
FALSE : 'false' ;
NULL : 'null' ;
NUMBER : NUM (EXPONENT)? ;
EXPONENT : ([Ee] ([-+])? ([0-9])+) ;
COLON : ':' ;
COMMA : ',' ;
LBRACE : '{' ;
RBRACE : '}' ;
LSQR : '[' ;
RSQR : ']' ;
NUM : (([-+])? ([0-9])+ | ([-+])? ([0-9])* '.' ([0-9])+) ;
fragment
STRING_CONTENT : (~[\n\r\f\\\"] | '\\' NL | ESCAPE)* ;
fragment
HEX : ([0-9a-fA-F]) ;
fragment
UNICODE: 'u' HEX (HEX (HEX (HEX)?)?)? ;
fragment
ESCAPE : UNICODE | '\\\\' ~[\r\n\f0-9a-f] ;
WS : [ \t]+ -> skip ;
NL : ([\n\r\f])+ -> skip ;JavaCC
JavaCC (Java Compiler Compiler) was written originally by Dr. Sriram Sankar and Sreenivasa Viswanadha. It is only capable of generating parsers in Java but doesn’t require a runtime library and the parsers it generates are very performant for an LL(k) parsers.
JavaCC Features:
- LL(k) Parser Generator (a top down parser with arbitrary token lookahead)
- Can only generate parsers in Java or C/C++.
- No runtime is required, the generated parser is completely autonomous.
- The lexer, parser, abstract syntax tree and documentation can all be generated from a single grammar file.
- Supports parsing modes for mixed language documents.
- Supports ranges for example a colour in CSS could be defined as “#”(([“0”-“9”,“a”-“f”,“A”-“F”]){3}){1,2}
- Grammar Definition is Java like.
- A book is available about JAVACC here
Example Syntax
A JSON Parser written in JavaCC
/**
* JavaCC JSON Parser
*/
options {
JDK_VERSION = "1.6";
STATIC = false;
UNICODE_INPUT = true;
MULTI = true;
VISITOR = true;
TRACK_TOKENS = true;
LOOKAHEAD=3;
NODE_USES_PARSER=true;
NODE_FACTORY = true;
}
/*
Class definition begins here:
Code added in this section is included as part of the generated parser.
*/
PARSER_BEGIN(JSONParser)
package com.brett.jsonparser.javacc;
import java.io.Reader;
import java.io.IOException;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import org.apache.log4j.Logger;
public class JSONParser {
private static final Logger logger = Logger.getLogger(JSONParser.class);
public static void main(String[] args) {
try {
String filename = System.getProperty("TEST_FILE_NAME");
Reader reader = new InputStreamReader(new FileInputStream(filename), "utf-8");
JSONParser p = new JSONParser(reader);
try {
SimpleNode node = p.value();
node.dump(">");
} catch (ParseException e) {
e.printStackTrace();
logger.error("Failed to parse because:", e);
}
} catch (IOException e) {
e.printStackTrace();
logger.error("An IOException occurred while trying to parse the file", e);
}
}
}
PARSER_END(JSONParser)
/*
==============================================================================================
Lexer token deinifitions are defined in this section.
==============================================================================================
*/
SKIP :
{
< WS : ([" ","\t"]) > |
< NL : (["\n","\r","\f"])+ >
}
TOKEN :
{
< #HEX: (["0"-"9","a"-"f","A"-"F"]) > |
< #UNICODE: "u" ((<HEX>)){4} > |
< #ESCAPE: <UNICODE> | "\\\\" ~["\r","\n","\f","0"-"9","a"-"f"] > |
< STRING: "\"" <STRING_CONTENT> "\"" > |
< #STRING_CONTENT: (~["\n","\r","\f","\\","\""] | "\\" <NL>|<ESCAPE>)* > |
< TRUE: "true" > |
< FALSE: "false" > |
< NULL: "null" > |
< NUMBER: <NUM>(<EXPONENT>)? > |
< EXPONENT: (["E","e"] (["-","+"])? (["0"-"9"])+) > |
< COLON: ":" > |
< COMMA: "," > |
< LBRACE: "{" > |
< RBRACE: "}" > |
< LSQR: "[" > |
< RSQR: "]" > |
< NUM: ((["-","+"])? (["0"-"9"])+ | (["-","+"])? (["0"-"9"])* "." (["0"-"9"])+) >
}
/*
==============================================================================================
Parser Rules and AST generation are defined/handled in this section
==============================================================================================
*/
void jsonObject() #JSONObject : {}
{
<LBRACE> nameValuePairList() <RBRACE>
}
void array() #Array : {}
{
<LSQR> valueList() <RSQR>
}
void nameValuePairList() #NameValuePairList : {}
{
nameValuePair() (<COMMA> nameValuePairList())*
}
void nameValuePair() #NameValuePair : {}
{
name() <COLON> value()
}
void name() #Name : {}
{
<STRING>
}
void valueList() #ValueList : {}
{
value() ((<COMMA>) valueList())*
}
SimpleNode value() #Value : {}
{
(jsonObject() | array() | <STRING> | <NUMBER> | booleanValue())
{ return jjtThis; }
}
void booleanValue() #BooleanValue : {}
{
<TRUE> | <FALSE>
}Benchmarks
The JSON file being parsed during the benchmark is a free example from https://adobe.github.io/Spry/samples/ and is shown here below:
[
{
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters": {
"batter": [
{
"id": "1001",
"type": "Regular"
},
{
"id": "1002",
"type": "Chocolate"
},
{
"id": "1003",
"type": "Blueberry"
},
{
"id": "1004",
"type": "Devil's Food"
}
]
},
"topping": [
{
"id": "5001",
"type": "None"
},
{
"id": "5002",
"type": "Glazed"
},
{
"id": "5005",
"type": "Sugar"
},
{
"id": "5007",
"type": "Powdered Sugar"
},
{
"id": "5006",
"type": "Chocolate with Sprinkles"
},
{
"id": "5003",
"type": "Chocolate"
},
{
"id": "5004",
"type": "Maple"
}
]
}
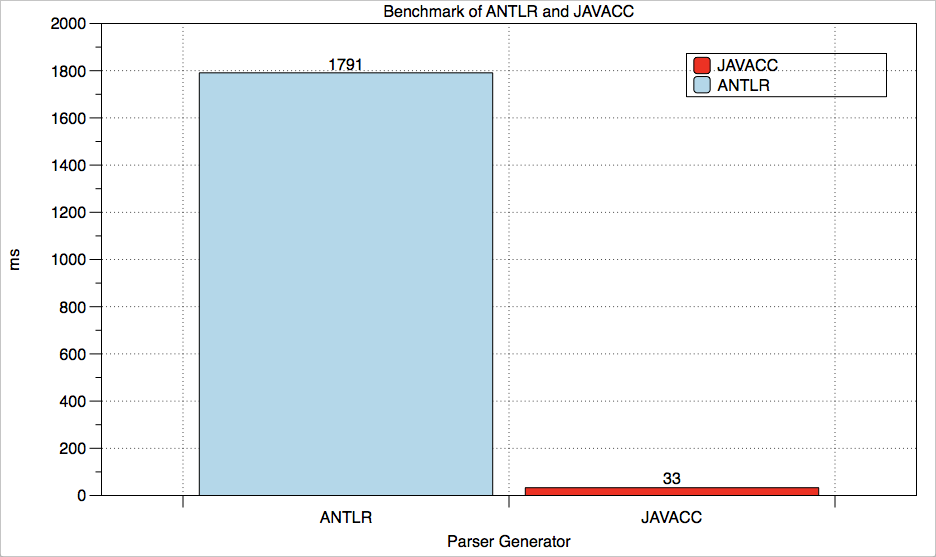
]Both parsers where launched and profiled using the same machine, the same profiler and JVM. The results are displayed below:
Parser Generator | Time (ms) | Avg. Time (ms) | Invocations |
ANTLR | 179,105 | 1,791 | 100 |
JAVACC | 3,312 | 33 | 100 |
Summary
JavaCC is clearly more performant than ANTLR however if performance is not an issue, both parser generators are valid tools. The syntax is very similar, both have books available to bring you up to speed. Each have pros and cons, your decision which one to use depends on your needs and on your personal preference. Obviously it also depends on what your target programming language will be for the project where you intend to use the parser.
Opinions expressed by DZone contributors are their own.
Comments