Anypoint Batch Processing and Polling Scope With Mulesoft
Batch processing is useful for handling large quantities of data, engineering near real-time data integration, integrating data sets, and more.
Join the DZone community and get the full member experience.
Join For FreeMule has the capability to process messages in batches. It splits the large messages into individual records that are processed asynchronously within batch jobs.
Batch processing is particularly useful when working with following scenarios:
Handling large quantities of incoming data from APIs into legacy systems.
Extracting, transforming, and loading (ETL) information into the destination system (i.e., uploading CSV or flat file data into the Hadoop system).
Engineering near real-time data integration (i.e., between SaaS applications).
Integrating datasets — small or large, streaming or not — to parallel process records.
Poll Scheduler
Poll scope in Mule is set up to be 1,000 ms by default to poll the resources for new data. You can change default polling intervals depending on your requirements. Polling can be done in the following two ways.
1. Fixed Frequency Scheduler
This method of configuring a poll schedule simply defines a fixed, time-based frequency for polling a source.
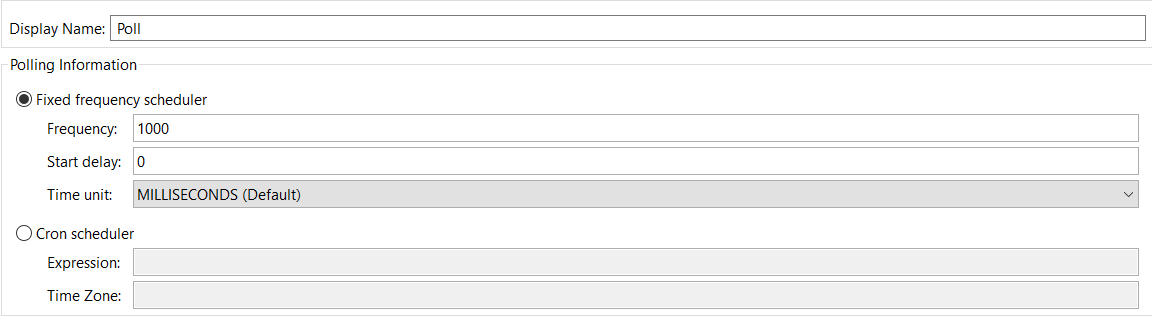
2. Cron Frequency Scheduler
This method allows you to configure the polling interval on basic cron expressions.

Phases Of Batch Jobs
Input
This is an optional phase. It triggers the flow via inbound endpoints and modifies the payload before batch processing (like transform messages).
Load And Dispatch
This is an implicit phase. It works behind the scene, splits the payload into a collection of records, and creates a queue.
Process
This is a mandatory phase in the batch job. It can have one or more batch steps. It synchronously processes the records.
On Complete
This is an optional phase. It provides a summary report of records processed and helps you get insight into which records fail so that you can properly address the issue. Payload is a BatchJobResult. It has properties for processing the following statistics:
loadedRecords, processedRecords, successfulRecords, failedRecords, totalRecords.
Let's walk through how you use batch jobs and polling scopes with Anypoint Studio.
Create Batch Job
Drag and drop Batch Scope to the Mule design palette. Batch scope has three stages: input, process, and on complete.
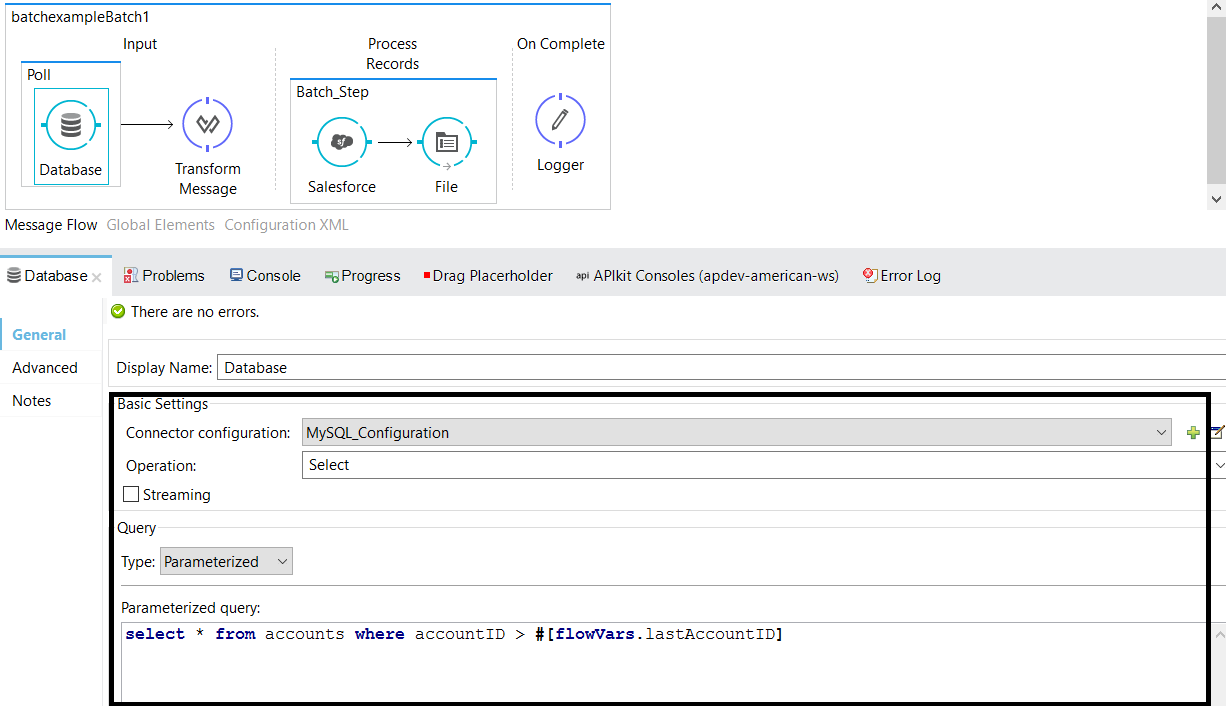
Place a Poll scope at the input stage and wrap up the database connector with the poll scope. Configure the database connector.
In this example, we will connect to MySQL database and make sure you add mysql-connector-java-5.0.8-bin.jar into your build path of your project.
Enable watermarks within the poll scope. In the context of Mule flows, this persistent record is called a watermark. In this example, we will store lastAccountID in the persistent object store and exposed flow variable.
This watermark is very helpful when you need to synchronize data between two systems (for example, a database to an SaaS application). Now, you have lastAccountID stored in a persistent object store. While selecting records from the database, we can use lastAccountID in the filter condition. So, we will only select newly added records in the database and synchronize with an SaaS application like Salesforce.
select * from accounts where accountID > #[flowVars.lastAccountID]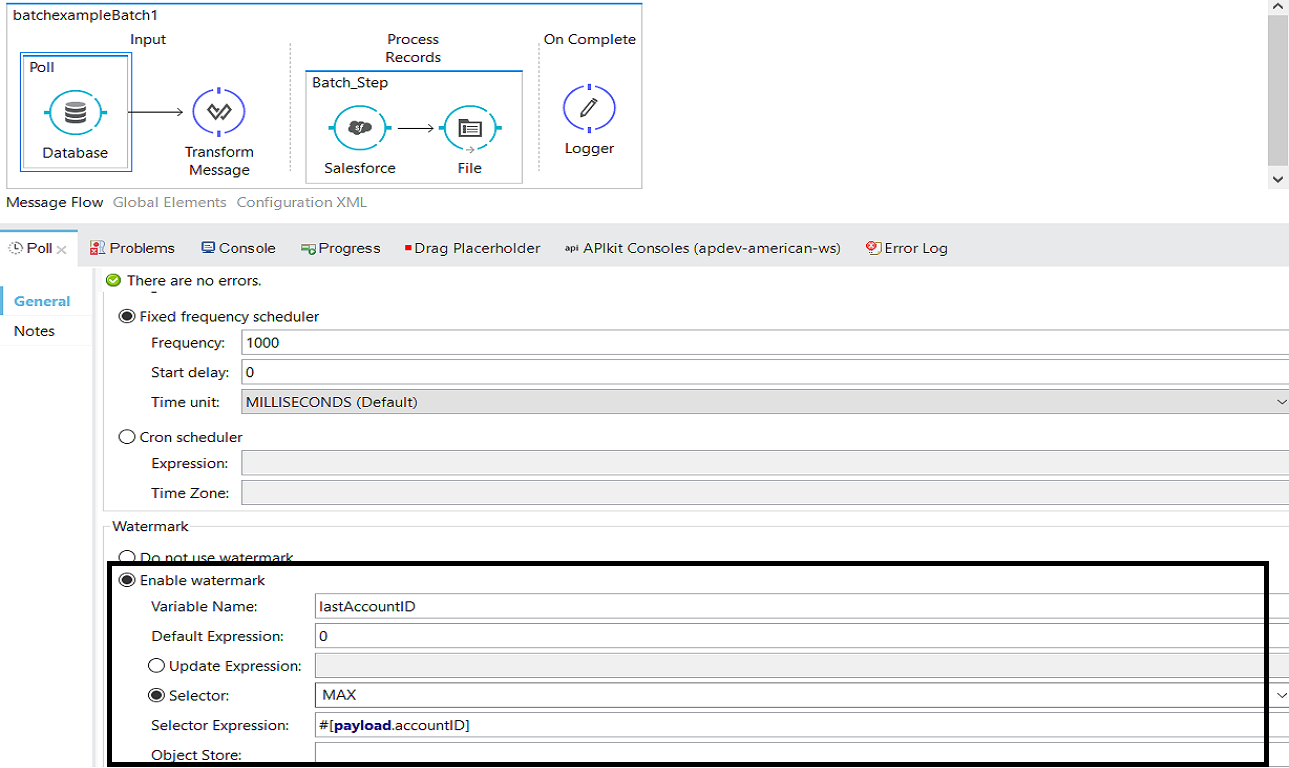
Place the Salesforce connector at the process records stage and configure it. For more details on configuring the Salesforce connector and creating records in Salesforce, please refer one of my articles about how to integrate Salesforce with Mule.
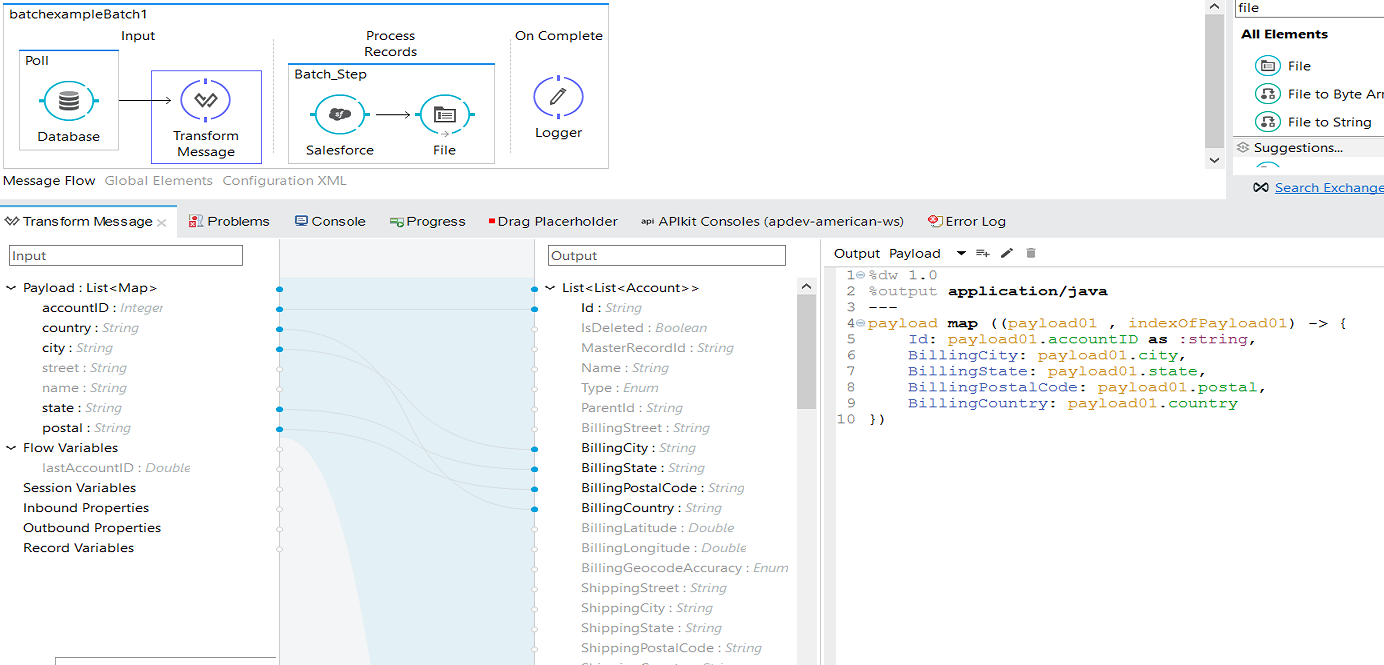
Place the Transform Message after database connector at the input stage. Input metadata will be generated automatically depending on the select query you have used and output metadata will automatically be generated by the Salesforce connector. Perform transformations as per your requirements.
Code
<?xml version="1.0" encoding="UTF-8"?>
<mule
xmlns:db="http://www.mulesoft.org/schema/mule/db"
xmlns:file="http://www.mulesoft.org/schema/mule/file"
xmlns:dw="http://www.mulesoft.org/schema/mule/ee/dw"
xmlns:metadata="http://www.mulesoft.org/schema/mule/metadata"
xmlns:http="http://www.mulesoft.org/schema/mule/http"
xmlns:batch="http://www.mulesoft.org/schema/mule/batch"
xmlns:sfdc="http://www.mulesoft.org/schema/mule/sfdc"
xmlns:tracking="http://www.mulesoft.org/schema/mule/ee/tracking"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:spring="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/sfdc http://www.mulesoft.org/schema/mule/sfdc/current/mule-sfdc.xsd
http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd
http://www.mulesoft.org/schema/mule/batch http://www.mulesoft.org/schema/mule/batch/current/mule-batch.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/ee/dw http://www.mulesoft.org/schema/mule/ee/dw/current/dw.xsd
http://www.mulesoft.org/schema/mule/ee/tracking http://www.mulesoft.org/schema/mule/ee/tracking/current/mule-tracking-ee.xsd
http://www.mulesoft.org/schema/mule/db http://www.mulesoft.org/schema/mule/db/current/mule-db.xsd">
<sfdc:config name="Salesforce__Basic_Authentication" username="" password="" securityToken="" doc:name="Salesforce: Basic Authentication"/>
<http:listener-config name="HTTP_Listener_Configuration" host="0.0.0.0" port="8081" doc:name="HTTP Listener Configuration"/>
<db:mysql-config name="MySQL_Configuration" host="" port="" user="" password="" database="" doc:name="MySQL Configuration"/>
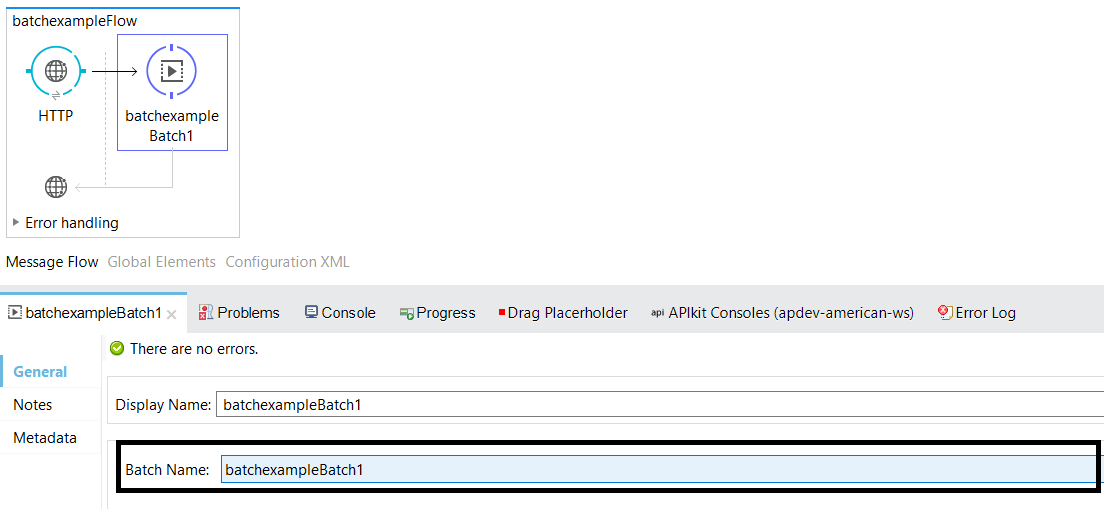
<batch:job name="batchexampleBatch1">
<batch:input>
<poll doc:name="Poll">
<fixed-frequency-scheduler frequency="1000"/>
<watermark variable="lastAccountID" default-expression="0" selector="MAX" selector-expression="#[payload.accountID]"/>
<db:select config-ref="MySQL_Configuration" doc:name="Database">
<db:parameterized-query>
<![CDATA[select * from accounts where accountID > #[flowVars.lastAccountID]]]>
</db:parameterized-query>
</db:select>
</poll>
<dw:transform-message doc:name="Transform Message">
<dw:set-payload>
<![CDATA[%dw 1.0
%output application/java
---
payload map ((payload01 , indexOfPayload01) -> {
Id: payload01.accountID as :string,
BillingCity: payload01.city,
BillingState: payload01.state,
BillingPostalCode: payload01.postal,
BillingCountry: payload01.country
})]]>
</dw:set-payload>
</dw:transform-message>
</batch:input>
<batch:process-records>
<batch:step name="Batch_Step">
<sfdc:create config-ref="Salesforce__Basic_Authentication" type="Account" doc:name="Salesforce">
<sfdc:objects ref="#[payload]"/>
</sfdc:create>
<file:outbound-endpoint path="src/test/resources/output" responseTimeout="10000" doc:name="File"/>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger message="Batch Job Completed" level="INFO" doc:name="Logger"/>
</batch:on-complete>
</batch:job>
</mule>Batch Commit
A scope that accumulates records into chunks to prepare bulk upserts to the external source or service is called a batch commit. You can add batch commits at the process record stage and wrap up the Salesforce connector with batch commit and set the commit size depending on your requirement.
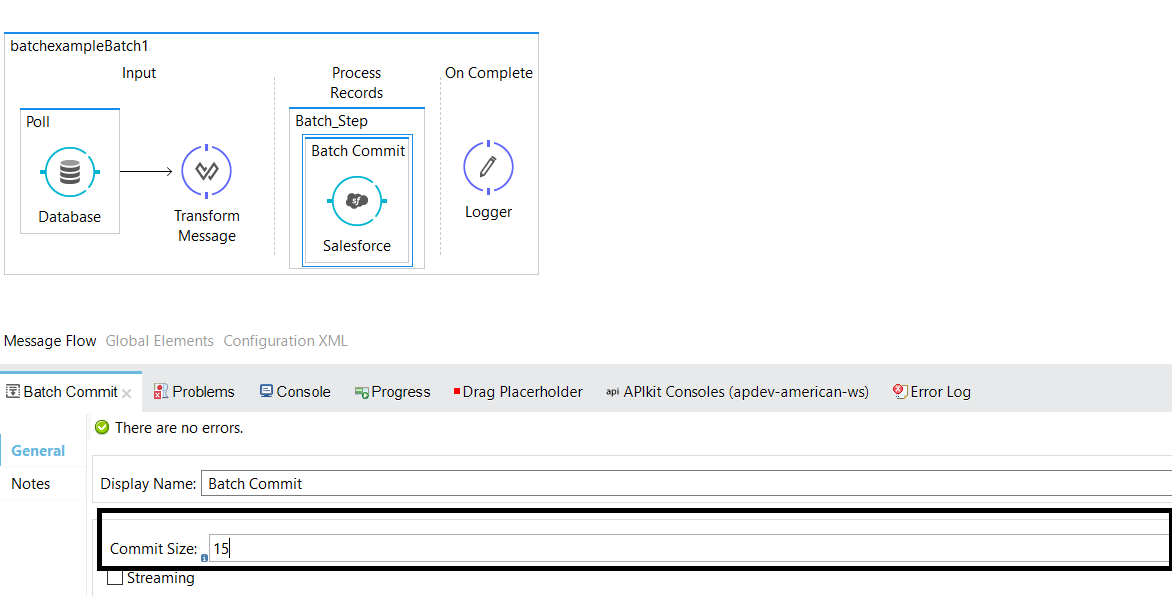
Batch Execute
Batch execute can be used to trigger the batch job. If you are not using poll scope or any message source in your batch job, then you can use batch execute to trigger a batch job.
 Now, you know how batch job and polling scope can be implemented!
Now, you know how batch job and polling scope can be implemented!
Here is the video tutorial.
Opinions expressed by DZone contributors are their own.
Comments