Apache Hive on YARN
Using Apache Hive on YARN enables Hadoop to support more varied processing approaches and a broader array of applications. Learn how to do it in this article!
Join the DZone community and get the full member experience.
Join For FreeYARN is a software rewrite that decouples MapReduce’s resource management and scheduling capabilities from the data processing component, enabling Hadoop to support more varied processing approaches and a broader array of applications. For example, Hadoop clusters can now run interactive querying and streaming data applications simultaneously with MapReduce batch jobs. In this blog, we will use Apache YARN on Apache Hive. Let's get started!
Add the file yarn-site.xml inside your /usr/local/hadoop/etc/hadoop folder with the following content:
<configuration>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx768m</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>Execution framework.</description>
</property>
<property>
<name>mapreduce.map.cpu.vcores</name>
<value>1</value>
<description>The number of virtual cores required for each map task.</description>
</property>
<property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>1</value>
<description>The number of virtual cores required for each map task.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
<description>Larger resource limit for maps.</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx768m</value>
<description>Heap-size for child jvms of maps.</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
<description>Larger resource limit for reduces.</description>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx768m</value>
<description>Heap-size for child jvms of reduces.</description>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>jobtracker.alexjf.net:8021</value>
</property>
</configuration>First, start the DFS with the following command: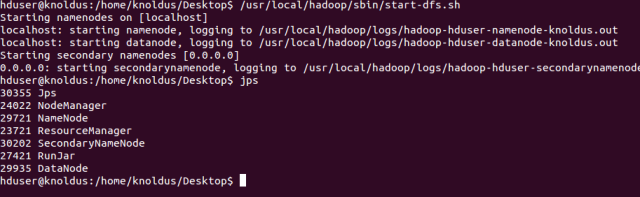
Next, start the YARN Resource Manager with the command yarn resourcemanager start: 
Then, start the YARN Node Manager with the command yarn nodemanager start:

Start your Hive CLI and fire an insert into the query since it is a MapReduce query:
Now, why does this job fail? There are two ways to see the application logs. One is by typing command yarn logs -applicationId <applicationId>:
...and the other is through navigating to job rankings specified by the YARN UI job tracking URL.
From the error message, you can see that you’re using more virtual memory than your current limit of 1.0 gb. This can be resolved in two ways; one is by increasing the memory of yarn.app.mapreduce.am.resource.mb to a higher value such as 4096. The other is specifying this when starting Hive fires your query:
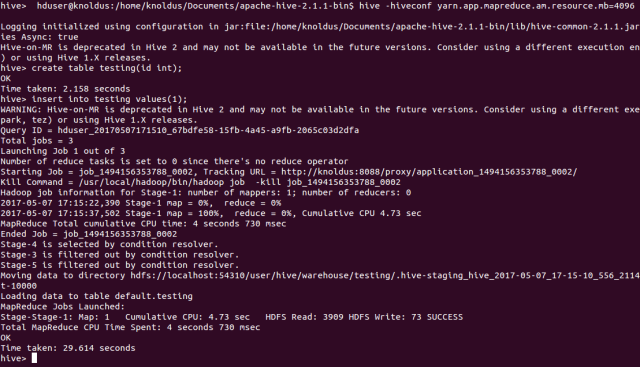
Now, even if you navigate to the YARN UI, the query is successful. That's it! I hope that this blog is helpful for for those starting with Apache Hive and YARN.
That's it! I hope that this blog is helpful for for those starting with Apache Hive and YARN.
Published at DZone with permission of Anubhav Tarar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments