Apache Phoenix With Variable-Length Encoded Data
Learn how Apache Phoenix has developed a new variable-length encoded binary data type to support a wide range of large language models (LLMs) use cases.
Join the DZone community and get the full member experience.
Join For FreeApache Phoenix is an open-source, SQL skin over Apache HBase that enables lightning-fast OLTP (Online Transactional Processing) operations on petabytes of data using standard SQL queries. Phoenix helps combine the scalability of NoSQL with the familiarity and power of SQL. By supporting large-scale aggregate and non-aggregate functionality, Phoenix has evolved into an OLTP and OLAP (Online Analytical Processing) database. This makes it a compelling choice for organizations looking to combine real-time data processing with complex analytical querying in a single, unified system.
Phoenix supports several variable-length data types:
VARCHARVARBINARYDECIMAL- All array data types (e.g.,
BINARY ARRAY,BOOLEAN ARRAY,CHAR ARRAY,DATE ARRAY,VARCHAR ARRAY, etc.)
Out of the variable-length data types, VARBINARY represents variable-length binary blobs. The value of the VARBINARY data type is similar to the HBase row key. Clients can provide non-fixed-length binary values. On the other hand, if the max length of the column is known in advance, clients can consider using the fixed-length binary data type: BINARY(<length>), e.g., BINARY(10), BINARY(25), BINARY(200), etc.
HBase provides a single row key. Any client application that requires using more than one column for primary keys, using HBase requires special handling of storing both column values as a single binary row key. Phoenix provides the ability to use more than one primary key by providing composite primary keys. A composite primary key can contain any number of primary key columns.
Phoenix also provides the ability to add new nullable primary key columns to the existing composite primary keys. Phoenix uses HBase as its backing store. To allow users to define multiple primary keys, Phoenix internally concatenates the binary-encoded values of each primary key column and uses the resulting concatenated binary value as the HBase row key. In order to efficiently concatenate as well as retrieve individual primary key values, Phoenix implements two ways:
- For fixed-length columns: The length of the given column is determined by the maximum length of the column. As part of the read flow, while iterating through the row key, fixed-length numbers of bytes are retrieved while reading. While writing, if the original encoded value of the given column has less number of bytes, additional null bytes (
\x00) are padded until the fixed length is filled up. Hence, for smaller values, we end up wasting some space. - For variable-length columns: Since we cannot know the length of the value of a variable-length data type in advance, a separator or terminator byte is used. Phoenix uses a null byte as a separator (
\x00). As of today,VARCHARis the most commonly used variable-length data type, and sinceVARCHARrepresents String, the null byte is not part of valid String characters. Hence, it can be effectively used to determine when to terminate the givenVARCHARvalue.
Problem Statement
The null byte (\x00) works fine as a separator for VARCHAR. However, it cannot be used as a separator byte for VARBINARY because VARBINARY can contain any binary blob values. Due to this, Phoenix has restrictions for the VARBINARY type:
- It can only be used as the last part of the composite primary key.
-
It cannot be used as a DESC order primary key column.
Using the VARBINARY data type as an earlier portion of the composite primary key is a valid use case. One can also use multiple VARBINARY primary key columns. After all, Phoenix provides the ability to use multiple primary key columns for users.
Besides, using a secondary index on a data table means that the composite primary key of the secondary index table includes:
<secondary-index-col1> <secondary-index-col2> … <secondary-index-colN> <primary-key-col1> <primary-key-col2> … <primary-key-colN>As primary key columns are appended to the secondary index columns, one cannot create a secondary index on any VARBINARY column. It is also important to consider that the original sort order of the binary should not be compromised.
Solutions
Use Length Information as the Terminator Bytes
Embedding length information as a prefix can compromise the sort order. We can embed the length information as a suffix of the row keys. However, this can also change the sort order. The only way we can use this approach is if the last portion of the composite primary key needs a strict sort order, but earlier portions of the composite keys (i.e., partition keys) do not have a strict sort order requirement.
In any case, encoding length information for individual VARBINARY column values can change the sort order. Therefore, this is not a promising solution.
Use Different Separator Bytes
Using a null byte as a separator for variable-length binary is not feasible. However, we can encode the binary values such that we can use a separator that is never guaranteed to be present in the binary data. This does require encoding of the binary blob. We can use two-byte separators for binary, e.g., \x00\x01 for ASC-ordered variable-length binary values. This requires encoding binary values such that the (\x00\x01) sequence is never present. We can encode every null byte (\x00) in the binary value by appending the reverse of the null byte (\xFF) to it, i.e., every \x00 byte is encoded to \x00\xFF while storing the value in HBase. Similarly, while retrieving the value, every sequence of \x00\xFF is decoded to \x00.
Examples:
Binary data: \xFE\xC8\x02\x80\x00\x02
Encoded data: \xFE\xC8\x02\x80\x00\xFF\x02
Binary data: \xEB\xFF\x00\x019\xAD\x00\xFF
Encoded data: \xEB\xFF\x00\xFF\x019\xAD\x00\xFF\xFFIn the second example, \x00\xFF becomes \x00\xFF\xFF.
If we were to concatenate the above-mentioned bytes into a single row key:
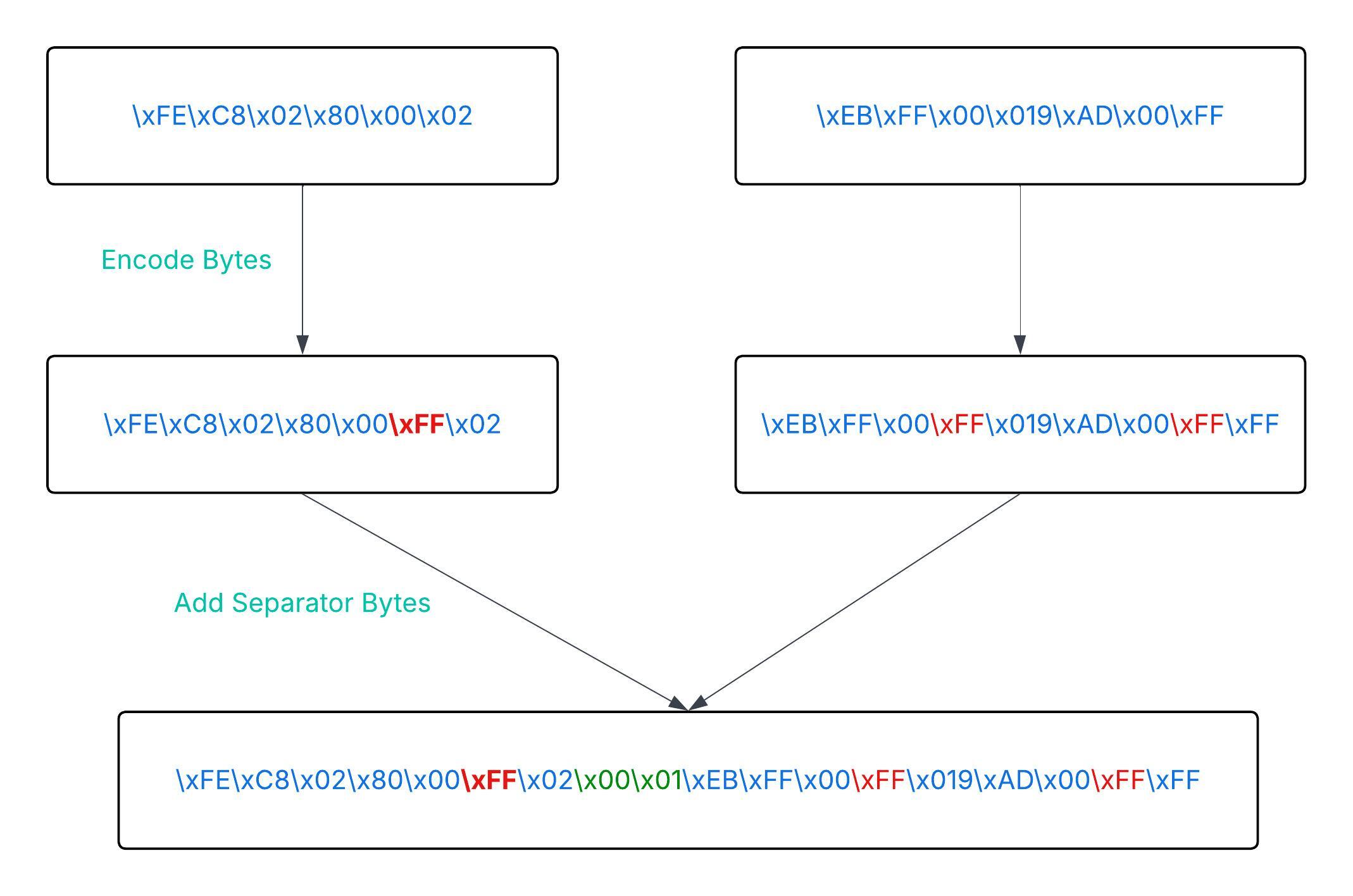
This encoded version of binary data ensures that separator bytes (\x00\x01) always stay unique.
We also need to support DESC order for variable-length binary data type. As we invert the byte values for any DESC order data type, the same must be followed here.
| bytes value | inverted bytes value |
|---|---|
|
\x00 |
\xFF |
|
\xFF |
\x00 |
|
\x00\xFF |
\xFF\x00 |
|
\x01 |
\xFE |
|
\x00\x01 |
\xFF\xFE |
Hence, for DESC-ordered binary columns, every sequence of \xFF in the original binary data needs to be encoded to \xFF\x00, and separator bytes are \xFF\xFE.
By using the new separate bytes, a new data type has evolved in Phoenix: VARBINARY_ENCODED.
Let's understand how the data is decoded for the VARBINARY_ENCODED data type:
One major challenge in retrieving individual primary key column values is that RowKeyValueAccessor does not retain column data type information while iterating over the row key. It currently has only three values:
- Offsets as an int array
- Does the column value have a fixed length?
- Does it have the separator byte?
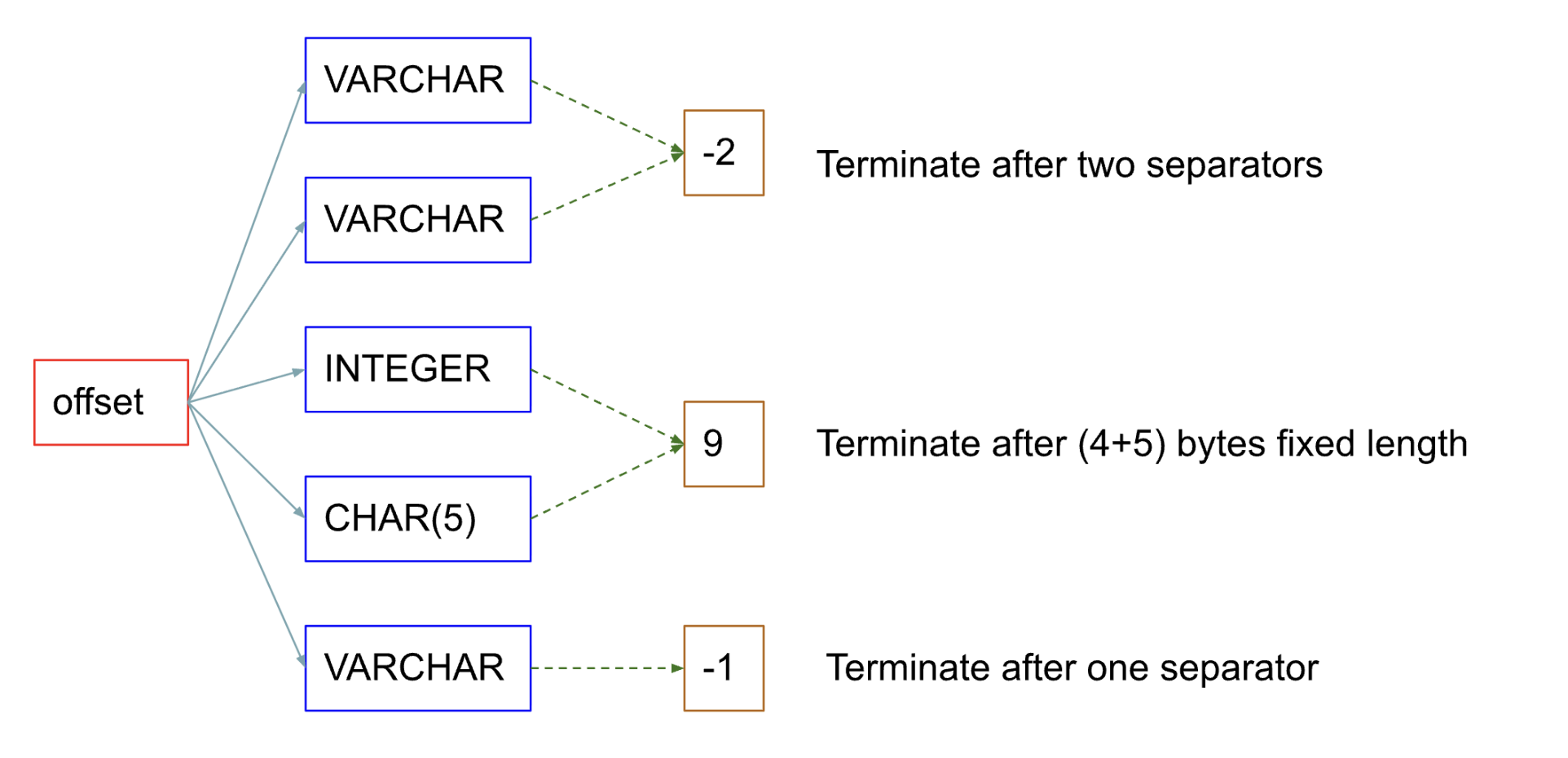
Offsets contain information about preceding columns. For every fixed-length column in the composite key that has been visited so far, it maintains the fixed-width value for that column. For every variable-length column in the composite key that has been visited so far, it maintains a value of -1. For subsequent variable-length columns, it keeps adding -1 to the offset. While retrieving individual column values, the iteration starts from offset 0 in the HBase row key. For every negative value, a subsequent number of separator bytes (\x00) are searched.
For instance, if the offset value at the current index is -1, the iteration stops when the first \x00 byte is identified. Similarly, when the offset value is -2, the iteration stops only after \x00 byte is read twice. This is to skip two consecutive variable-length data types.
With the introduction of the VARBINARY_ENCODED column that requires different separator bytes, we can no longer rely only on offset values maintained by RowKeyValueAccessor. We also need to determine whether the traversed primary key is VARBINARY_ENCODED and hence requires separator bytes \x00\x01 (or \xFF\xFE).
As we introduce new fields, we also need to serialize and deserialize them. As RowKeyValueAccessor is an Expression, its serialization takes place with other Expressions. Hence, in order to maintain compatibility with old clients, we need to introduce new separator bytes for the (de)serialization purpose.
Deserialization of the new RowKeyValueAccessor fields must be done carefully because we might end up increasing the read offset of the DataInput or DataInputStream holding the underlying bytes. For Phoenix, DataInput can be either of type DataInputBuffer or DataInputStream (with mark support), and hence, the underlying byte array must be accessed to read the RowKeyValueAccessor separator bytes without increasing the offset value.
Let’s consider an example of composite primary keys:
CREATE TABLE T1 (
VARCHAR pk1,
VARCHAR pk2,
INTEGER pk3 NOT NULL,
CHAR(5) pk4 NOT NULL,
VARCHAR pk5,
DOUBLE col1,
VARCHAR col2,
CONSTRAINT pk PRIMARY KEY (pk1, pk2, pk3, pk4, pk5)
)When we retrieve the value for column pk5, row key iteration takes place according to this structure:
As the negative offset values require us to scan for separator bytes, and so far we have had only the null byte as a separator, this is not sufficient with the evolution of VARBINARY_ENCODED. Now we expand the structure of RowKeyValueAccessor and include variable-length data type information for the prefix columns, as well as their sort orders.
As separator bytes are different for VARBINARY_ENCODED and VARCHAR, and with the combination of ASC and DESC orders, we have a total of four separator bytes; we preserve both data types and sort orders.
Separator bytes for each case:
VARCHAR with ASC order: \x00
VARCHAR with DESC order: \xFF
VARBINARY_ENCODED with ASC order: \x00\xFF
VARBINARY_ENCODED with DESC order: \xFF\x00As RowKeyValueAccessor is an Expression, the serialization and deserialization of its fields now requires us to serialize and deserialize additional fields. However, several Expression implementations are serialized and combined together. During deserialization, we might end up accessing unnecessary bytes if RowKeyValueAccessor was serialized by an old client.
Hence, we need new separator bytes for the purpose of maintaining compatibility between old and new clients during the serialization and deserialization process. This makes sure the VARBINARY_ENCODED data type can be seamlessly used with Phoenix 5.3.0 onwards versions, without breaking client compatibility for old data types used by old Phoenix versions (lower than 5.3.0).
The addition of VARBINARY_ENCODED data type support in Phoenix represents a significant key enhancement for modern LLM workloads, providing strongly consistent OLTP capabilities with optimized binary encoding support.
Opinions expressed by DZone contributors are their own.
Comments