Apache Spark: All About Serialization
Learn how you can tune your spark jobs to perform better. Serialization is essential to the performance of distributed applications to eliminates data transfer issues.
Join the DZone community and get the full member experience.
Join For Free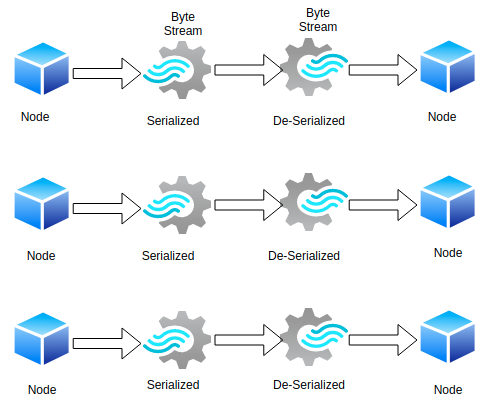
Serialization
Converting objects into a stream of bytes and vice-versa(De-Serialization) in an optimal way to transfer over nodes of network or to store it in file/memory buffer. Spark provides two serialization libraries with supported and configured modes through spark.serializerproperty:
Java Serialization (Default)
Java Serialization is the default serialization that is used by Spark when we spin up the driver. Spark serializes objects using Java’s ObjectOutputStream framework. The serializability of a class is enabled by the class implementing the java.io.Serializable interface. Classes that do not implement this interface will not have any of their state serialized or deserialized. All subtypes of a serializable class are themselves serializable.
A class is never serialized, only the object of a class is serialized. Java Serialization is slow and leads to large serialized formats for many classes. we can fine-tune the performance by extending java.io.Externalizable.
Kryo Serialization (Recommended by Spark)
public class KryoSerializer extends Serializerimplements Logging, java.io.Serializable
Kryo is a Java serialization framework with a focus on speed, efficiency, and a user-friendly API. It has less memory footprint which becomes very important when you are shuffling and caching a large amount of data. but is not natively supported to serialize to the disk. Both methods, saveAsObjectFile on RDD and objectFile method on SparkContext supports only java serialization.
Kryo is not the default because of the custom registration and manual configuration requirement.
Default Serializer
When Kryo serializes an object, it creates an instance of a previously registered Serializer class to do the conversion to bytes. default serializers and can be used without any setup on our part.
Custom Serializer
for more control over the serialization process, Kryo provides two options, we can write our own Serializer class and register it with Kryo or let the class handle the serialization by itself.
Let's see how we can set up Kryo to use in our application.
val conf = new SparkConf()
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.kryoserializer.buffer.mb","24")
val sc = new SparkContext(conf)val sc = new SparkContext(conf)
_______________________
val spark = SparkSession.builder().appName(“KryoSerializerExample”)
.config(someConfig) .config(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”) .config(“spark.kryoserializer.buffer”, “1024k”) .config(“spark.kryoserializer.buffer.max”, “1024m”) .config(“spark.kryo.registrationRequired”, “true”)
.getOrCreate }
The buffer size is used to hold the largest object you will serialize and it should be large enough for optimal performance. KryoSerializer is a helper class provided by the spark to deal with Kryo. We create a single instance of KryoSerializer which configures the required buffer sizes provided in the configuration.
Databricks Guidelines to Avoid Serialization Issues
Following are some of the guidelines that were made by Databricks to avoid the Serialization issues:
- Make the object/class serializable.
- declare the instance within the lambda function.
- Declare functions inside an Object as much as possible.
- Redefine variables provided to class constructors inside functions.
Resources
https://spark.apache.org/docs/latest/tuning.html
https://github.com/EsotericSoftware/kryo
Opinions expressed by DZone contributors are their own.
Comments