Apache Spark for the Impatient
Join the DZone community and get the full member experience.
Join For FreeBelow is a list of the most important topics in Spark that everyone who does not have the time to go through an entire book but wants to discover the amazing power of this distributed computing framework should definitely go through before starting.
Architecture
MapReduce vs Spark
Although there are a lot of low-level differences between Apache Spark and MapReduce, the following are the most prominent ones:
- Spark has been found to run 100 times faster in-memory, and 10 times faster on disk.
- A sorting application that was used to sort 100 TB of data was three times faster than the application running on Hadoop MapReduce using one-tenth of the machines.
- Spark has particularly been found to be faster on machine learning applications, such as Naive Bayes and K-Means.
- However, if Spark is running on YARN with other shared services, performance might degrade and cause RAM overhead memory leaks. For this reason, if a user has a use-case of batch processing, Hadoop has been found to be the more efficient system.
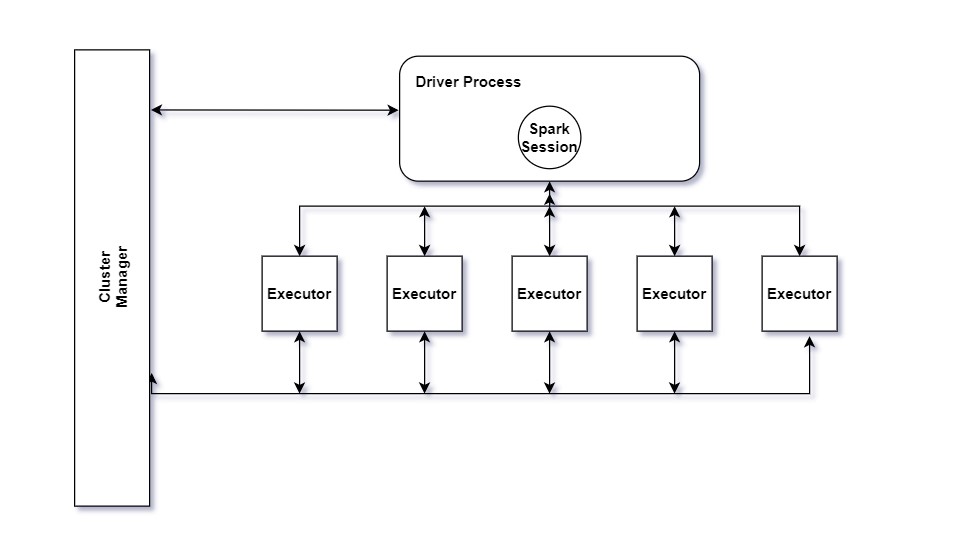
Driver and Executors
The driver process that runs your main() function sits on a node in the cluster and is responsible for three things:
- Maintaining information about the Spark application.
- Responding to a user’s program or input.
- Analyzing, distributing, and scheduling work across the executors.
The driver process is absolutely essential — it’s the heart of a Spark application and maintains all relevant information during the lifetime of the application.
The executors are responsible for actually carrying out the work that the driver assigns them. This means that each executor is responsible for only two things:
- Executing code assigned to it by the driver.
- Reporting the state of the computation on that executor back to the driver node.
Partitions
To allow every executor to perform work in parallel, Spark breaks up data into chunks called partitions. A partition is a collection of rows that sit on one physical machine in your cluster. A Dataframe’s partitions represent how the data is physically distributed across the cluster of machines during execution.
If you have one partition, Spark will have a parallelism of only one, even if you have thousands of executors. If you have many partitions but only one executor, Spark will still have a parallelism of only one because there is only one computation resource.
Execution Mode: Client or Cluster or Local
An execution mode gives you the power to determine where the aforementioned resources like Driver and Executors are physically located when you run your application.
You have three modes to choose from:
- Cluster Mode.
- Client Mode.
- Local Mode.
Cluster Mode is probably the most common way of running Spark Applications. In cluster mode, a user submits pre-compiled code to a cluster manager. The cluster manager then launches the driver process on a worker node inside the cluster, in addition to the executor processes. This means that the cluster manager is responsible for managing all the processes related to the Spark Application.
Client Mode is nearly the same as cluster mode except that the Spark driver remains on the client machine that submitted the application. This means that the client machine is responsible for maintaining the Spark driver process, and the cluster manager maintains the executor processes. Machines, where we run Spark Applications from and are not collocated on the cluster, are commonly referred to as gateway machines or edge nodes.
Local Mode can be thought of as running a program on your computer, in which you tell spark to run the driver as well as executors in the same JVM.
RDD, Dataframe, and Dataset
The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it.
In cases when a single RDD is supposed to be used multiple times, the users can request Spark to persist an RDD, there are multiple persistence levels, which will instruct the spark application to save the RDD and allowing efficient use. Finally, RDDs automatically recover from node failures.
A Dataframe is the most common Structured API and simply represents a table of data with rows and columns. The columns and their datatypes when combined form the schema of the dataframe. You can think of a Dataframe as a spreadsheet with named columns.
Although there is a fundamental difference: a spreadsheet resides on one computer in one specific location, whereas a Spark Dataframe can span thousands of computers. There can be various reasons of putting a file on multiple nodes: either the data is too large to fit on one machine or it would simply take too long to perform that computation on one machine.
Starting in Spark 2.0, Dataset takes on two distinct APIs characteristics: a strongly-typed API and an untyped API. Conceptually, consider Dataframe as an alias for a collection of generic objects Dataset[Row], where a Row is a generic untyped JVM object. Dataset, by contrast, is a collection of strongly-typed JVM objects, dictated by a case class you define in Scala or a class in Java.
Shared Variables
The second abstraction in Spark is shared variables that can be used across all participating nodes, during parallel operations. Although, normally, Spark ships a copy of the variables that are required by the task to perform its functions. However, sometimes, a variable needs to be shared across tasks, or between tasks and the driver program. Spark supports two types of shared variables:
- Broadcast Variables, which can be used to cache a value in memory on all nodes.
- Accumulators, which are variables that are only “added” to, such as counters and sums.
Spark Session
The first step of any Spark application is creating a SparkSession. Some of your legacy code might use the new SparkContext pattern. This should be avoided in favor of the builder method on the SparkSession, which more robustly instantiates the Spark and SQL Contexts and ensures that there is no context conflict, given that there might be multiple libraries trying to create a session in the same Spark application:
After you have a SparkSession, you should be able to run your Spark code. From the SparkSession, you can access all of the low-level and legacy contexts and configurations accordingly, as well.
Note: The SparkSession class was only added in Spark 2.X. Older code you might find would instead directly create a SparkContext and an SQLContext for structured APIs.
A SparkContext object within the SparkSession represents the connection to the Spark cluster. This class is how you communicate with some of Spark’s lower-level APIs, such as RDDs. Through a SparkContext, you can create RDDs, accumulators, and broadcast variables, and you can run code on the cluster. If you want to initialize SparkContext, you should create it in the most general way, through the getOrCreate method:
Lazy Evaluation
Lazy evaluation means that Spark will wait until the very last moment to execute the graph of computation instructions. In Spark, instead of modifying the data immediately when you express some operation, you build up a plan of transformations that you would like to apply to your source data.
By waiting until the last minute to execute the code, Spark compiles this plan from your raw Dataframe transformations to a streamlined physical plan that will run as efficiently as possible across the cluster. This provides immense benefits because Spark can optimize the entire data flow from end to end. An example of this is something called predicate pushdown on Dataframes.
If we build a large Spark job but specify a filter at the end that only requires us to fetch one row from our source data, the most efficient way to execute this is to access the single record that we need. Spark will actually optimize this for us by pushing the filter down automatically.
Actions and Transformation
Transformations allow us to build up our logical transformation plan. To trigger the computation, we run an action. An action instructs Spark to compute a result from a series of transformations. The simplest action is count, which gives us the total number of records in the DataFrame: divisBy2.count() The output of the preceding code should be 500.
Of course, count is not the only action. There are three kinds of actions: Actions to view data in the console Actions to collect data to native objects in the respective language Actions to write to output data sources In specifying this action, we started a Spark job that runs our filter transformation (a narrow transformation), then an aggregation (a wide transformation) that performs the counts on a per partition basis, and then a collect, which brings our result to a native object in the respective language.
You can see all of this by inspecting the Spark UI, a tool included in Spark with which you can monitor the Spark jobs running on a cluster.
In Spark, the core data structures are immutable, meaning they cannot be changed after they’re created. This might seem like a strange concept at first: if you cannot change it, how are you supposed to use it? To “change” a DataFrame, you need to instruct Spark how you would like to modify it to do what you want. These instructions are called transformations.
Transformations are the core of how you express your business logic using Spark. There are two types of transformations: those that specify narrow dependencies, and those that specify wide dependencies. Transformations consisting of narrow dependencies (we’ll call them narrow transformations) are those for which each input partition will contribute to only one output partition. In the preceding code snippet, the where statement specifies a narrow dependency, where only one partition contributes to at most one output partition.
A wide dependency (or wide transformation) style transformation will have input partitions contributing to many output partitions. You will often hear this referred to as a shuffle whereby Spark will exchange partitions across the cluster. With narrow transformations, Spark will automatically perform an operation called pipelining, meaning that if we specify multiple filters on Dataframes, they’ll all be performed in-memory. The same cannot be said for shuffles. When we perform a shuffle, Spark writes the results to disk.
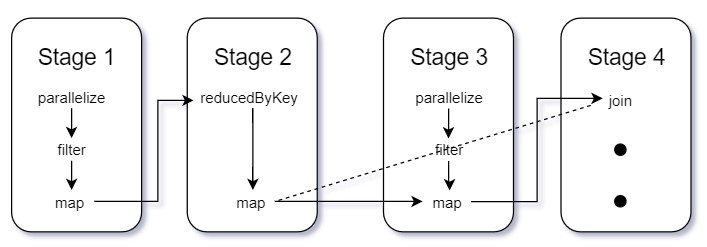
Stages and Tasks
Stages in Spark represent groups of tasks that can be executed together to compute the same operation on multiple machines. In general, Spark will try to pack as much work as possible (i.e., as many transformations as possible inside your job) into the same stage, but the engine starts new stages after operations called shuffles.
A shuffle represents a physical repartitioning of the data—for example, sorting a DataFrame, or grouping data that was loaded from a file by key (which requires sending records with the same key to the same node). This type of repartitioning requires coordinating across executors to move data around. Spark starts a new stage after each shuffle and keeps track of what order the stages must run in to compute the final result.
Stages in Spark consist of tasks. Each task corresponds to a combination of blocks of data and a set of transformations that will run on a single executor. If there is one big partition in our dataset, we will have one task. If there are 1,000 little partitions, we will have 1,000 tasks that can be executed in parallel. A task is just a unit of computation applied to a unit of data (the partition). Partitioning your data into a greater number of partitions means that more can be executed parallelly.
DAG: Directed Acyclic Graphs
DAG in Apache Spark is a set of Vertices and Edges, where vertices represent the RDDs, and the edges represent the operation to be applied to the RDD. In a Spark DAG, every edge directs from earlier to later in the sequence.
Resource Manager: Stand-Alone or YARN or MESOS
The cluster of machines that Spark will use to execute tasks is managed by a cluster manager, like Spark’s standalone cluster manager, YARN, or Mesos. We then submit Spark Applications to these cluster managers, which will grant resources to our application so that we can complete our work.
Fun Fact: Matei Zaharia, the creator of spark, started Spark to serve as a pilot workload for Mesos.
Follow me on twitter at @IamShivamMohan
Opinions expressed by DZone contributors are their own.
Comments